|
|
@@ -15,16 +15,18 @@ Hardware
|
|
|
- 16Gb RAM
|
|
|
- SSD
|
|
|
- OS X 10.13
|
|
|
-- python 3.7.2
|
|
|
+- Python 3.7.2
|
|
|
- lmdb 0.9.22
|
|
|
|
|
|
Benchmark script
|
|
|
~~~~~~~~~~~~~~~~
|
|
|
|
|
|
-`Generator script <../../util/benchmark.py>`__
|
|
|
+`Source code <../../util/benchmark.py>`__
|
|
|
|
|
|
-The script was run with default values: resprectively 10,000 and 100,000
|
|
|
-children under the same parent. PUT and POST requests were tested separately.
|
|
|
+The script was run by generating 100,000 children under the same parent. PUT
|
|
|
+and POST requests were tested separately. The POST method produced pairtrees
|
|
|
+in Fedora to counter its known issue with many resources as direct children of
|
|
|
+a container.
|
|
|
|
|
|
The script calculates only the timings used for the PUT or POST requests, not
|
|
|
counting the time used to generate the random data.
|
|
|
@@ -43,6 +45,10 @@ with a consistent size and variation:
|
|
|
- 100 triples have an object that is a 64-character random Unicode
|
|
|
string (50 unique predicates; 100 unique objects).
|
|
|
|
|
|
+The benchmark script is also capable of generating random binaries and a mix of
|
|
|
+binary and RDF resources; a large-scale benchmark, however, was impractical at
|
|
|
+the moment due to storage constraints.
|
|
|
+
|
|
|
LDP Data Retrieval
|
|
|
~~~~~~~~~~~~~~~~~~
|
|
|
|
|
|
@@ -53,12 +59,8 @@ REST API request::
|
|
|
SPARQL Query
|
|
|
~~~~~~~~~~~~
|
|
|
|
|
|
-*Note:* The query may take a long time and therefore is made on the
|
|
|
-single-threaded server (``lsup-server``) that does not impose a timeout (of
|
|
|
-course, gunicorn could also be used by changing the configuration to allow a
|
|
|
-long timeout).
|
|
|
-
|
|
|
-Sample query::
|
|
|
+The following query was used against the repository after the 100K resource
|
|
|
+ingest::
|
|
|
|
|
|
PREFIX ldp: <http://www.w3.org/ns/ldp#>
|
|
|
SELECT (COUNT(?s) AS ?c) WHERE {
|
|
|
@@ -83,76 +85,79 @@ IPython console::
|
|
|
|
|
|
In [1]: from lakesuperior import env_setup
|
|
|
In [2]: from lakesuperior.api import resource as rsrc_api
|
|
|
- In [3]: %timeit x = rsrc_api.get('/pomegranate').imr.as_rdflib
|
|
|
+ In [3]: %timeit x = rsrc_api.get('/pomegranate').imr.as_rdflib()
|
|
|
|
|
|
Results
|
|
|
-------
|
|
|
|
|
|
-10K Resources
|
|
|
-^^^^^^^^^^^^^
|
|
|
-
|
|
|
-=============================== ============= ============= ============ ============ ============
|
|
|
-System PUT POST Store GET SPARQL Query
|
|
|
-=============================== ============= ============= ============ ============ ============
|
|
|
-FCREPO / Modeshape 4.7.5 68ms (100%) XXms (100%) 3.9Gb (100%) 6.2s (100%) N/A
|
|
|
-Lakesuperior 1.0a20 REST API 105ms (159%) XXXms (XXX%) 298Mb (8%) 2.1s XXXXXXXs
|
|
|
-Lakesuperior 1.0a20 Python API 53ms (126%) XXms (XXX%) 789Mb (21%) 381ms N/A
|
|
|
-=============================== ============= ============= ============ ============ ============
|
|
|
-
|
|
|
-**Notes:**
|
|
|
-
|
|
|
-- The Python API time for the GET request in alpha18 is 8.5% of the request.
|
|
|
- This means that over 91% of the time is spent serializing the results.
|
|
|
- This time could be dramatically reduced by using faster serialization
|
|
|
- libraries, or can be outright zeroed out by an application that uses the
|
|
|
- Python API directly and manipulates the native RDFLib objects (of course, if
|
|
|
- a serialized output is eventually needed, that cost is unavoidable).
|
|
|
-- Similarly, the ``triples`` retrieval method of the SPARQL query only takes
|
|
|
- 13.6% of the request time. The rest is spent evaluating SPARQL and results.
|
|
|
- An application can use ``triples`` directly for relatively simple lookups
|
|
|
- without that overhead.
|
|
|
-
|
|
|
-100K Resources
|
|
|
-^^^^^^^^^^^^^^
|
|
|
-
|
|
|
-=============================== =============== =============== ============= =============== ==============
|
|
|
-System PUT POST Store GET SPARQL Query
|
|
|
-=============================== =============== =============== ============= =============== ==============
|
|
|
-FCREPO / Modeshape 4.7.5 500+ms* 65ms (100%)\*\* 12Gb (100%) 3m41s (100%) N/A
|
|
|
-Lakesuperior 1.0a20 REST API 104ms (100%) 123ms (189%) 8.7Gb (72%) 30s (14%) 19.3s (100%)
|
|
|
-Lakesuperior 1.0a20 Python API 69ms (60%) 58ms (89%) 8.7Gb (72%) 6s (2.7%) 9.17s (47%)
|
|
|
-=============================== =============== =============== ============= =============== ==============
|
|
|
-
|
|
|
-\* POST was stopped at 30K resources after the ingest time reached >1s per
|
|
|
-resource. This is the manifestation of the "many members" issue which is
|
|
|
-visible in the graph below. The "Store" value is for the PUT operation which
|
|
|
-ran regularly with 100K resources.
|
|
|
-
|
|
|
-\*\* the POST test with 100K resources was conducted with fedora 4.7.5 because
|
|
|
-5.0 would not automatically create a pairtree, thereby resulting in the same
|
|
|
-performance as the PUT method.
|
|
|
-
|
|
|
-\*\*\* Timing based on a warm cache. The first query timed at 0m22.2s.
|
|
|
+=================== =============== ================ ============= ==================== ==============
|
|
|
+Software PUT POST Store Size GET SPARQL Query
|
|
|
+=================== =============== ================ ============= ==================== ==============
|
|
|
+FCREPO 5.0.2 >500ms [#]_ 65ms (100%) [#]_ 12Gb (100%) 3m41s (100%) N/A
|
|
|
+Lakesuperior REST 104ms (100%) 123ms (189%) 8.7Gb (72%) 30s (14%) 19.3s (100%)
|
|
|
+Lakesuperior Python 69ms (60%) 58ms (89%) 8.7Gb (72%) 6.7s (3%) [#]_ [#]_ 9.17s (47%)
|
|
|
+=================== =============== ================ ============= ==================== ==============
|
|
|
+
|
|
|
+.. [#] POST was stopped at 30K resources after the ingest time reached >1s per
|
|
|
+ resource. This is the manifestation of the "many members" issue which is
|
|
|
+ visible in the graph below. The "Store" value is for the PUT operation
|
|
|
+ which ran regularly with 100K resources.
|
|
|
+
|
|
|
+.. [#] the POST test with 100K resources was conducted with fedora 4.7.5
|
|
|
+ because 5.0 would not automatically create a pairtree, thereby resulting
|
|
|
+ in the same performance as the PUT method.
|
|
|
+
|
|
|
+.. [#] Timing based on a warm cache. The first query timed at 22.2s.
|
|
|
+
|
|
|
+.. [#] The Python API time for the "GET request" (retrieval) without the
|
|
|
+ conversion to Python in alpha20 is 3.2 seconds, versus the 6.7s that
|
|
|
+ includes conversion to Python/RDFlib objects. This can be improved by
|
|
|
+ using more efficient libraries that allow serialization and
|
|
|
+ deserialization of RDF.
|
|
|
+
|
|
|
+Charts
|
|
|
+------
|
|
|
+
|
|
|
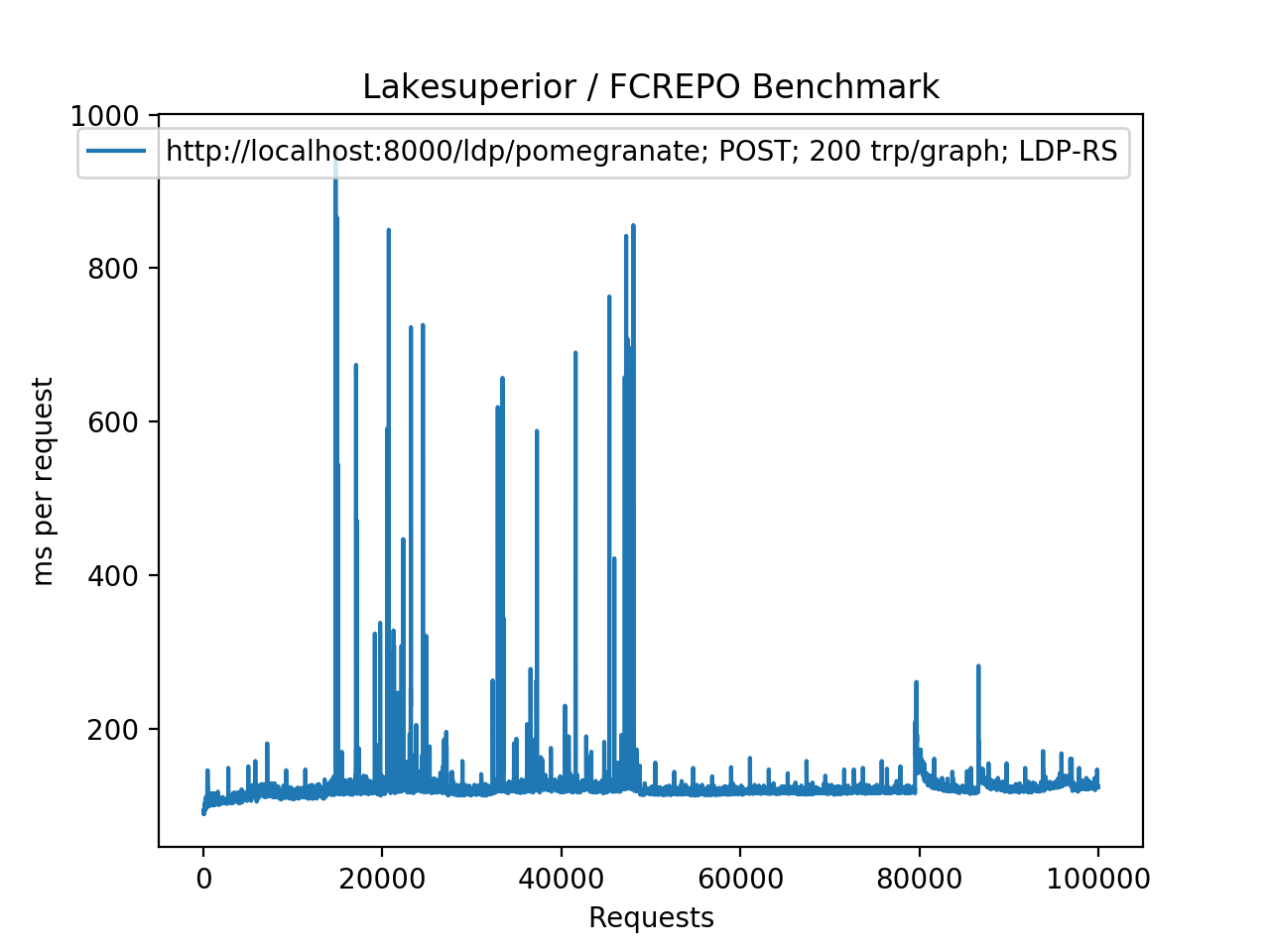
+.. figure:: assets/plot_fcrepo_put_100K.png
|
|
|
+ :alt: Fedora with PUT, 100K request time chart
|
|
|
+
|
|
|
+ Fedora/Modeshape using PUT requests under the same parent. The "many
|
|
|
+ members" issue is clearly visible after a threshold is reached.
|
|
|
+
|
|
|
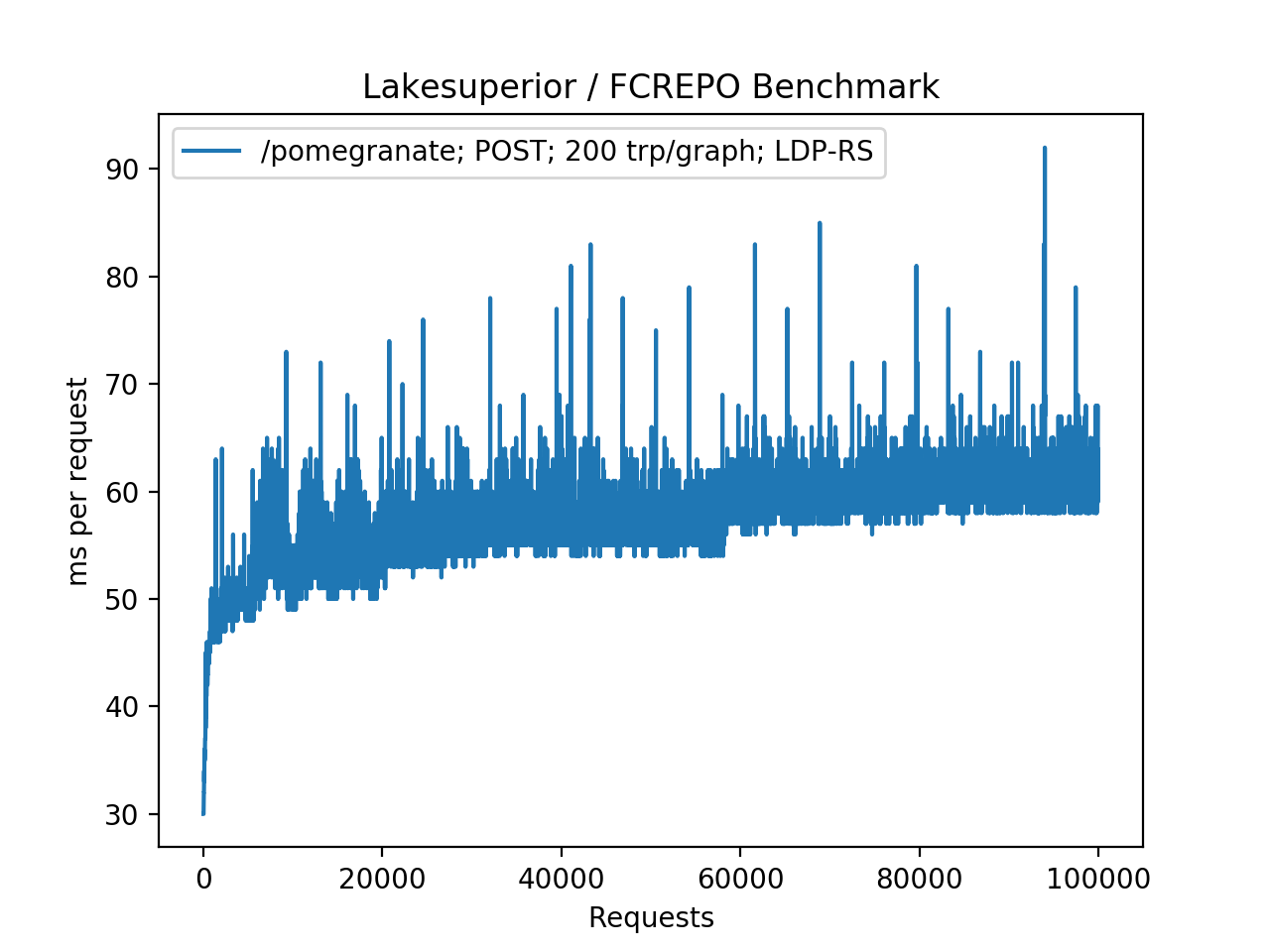
+.. figure:: assets/plot_fcrepo_post_100K.png
|
|
|
+ :alt: Fedora with POST, 100K request time chart
|
|
|
+
|
|
|
+ Fedora/Modeshape using POST requests generating pairtrees. The performance
|
|
|
+ is greatly improved, however the ingest time increases linearly with the
|
|
|
+ repository size (O(n) time complexity)
|
|
|
+
|
|
|
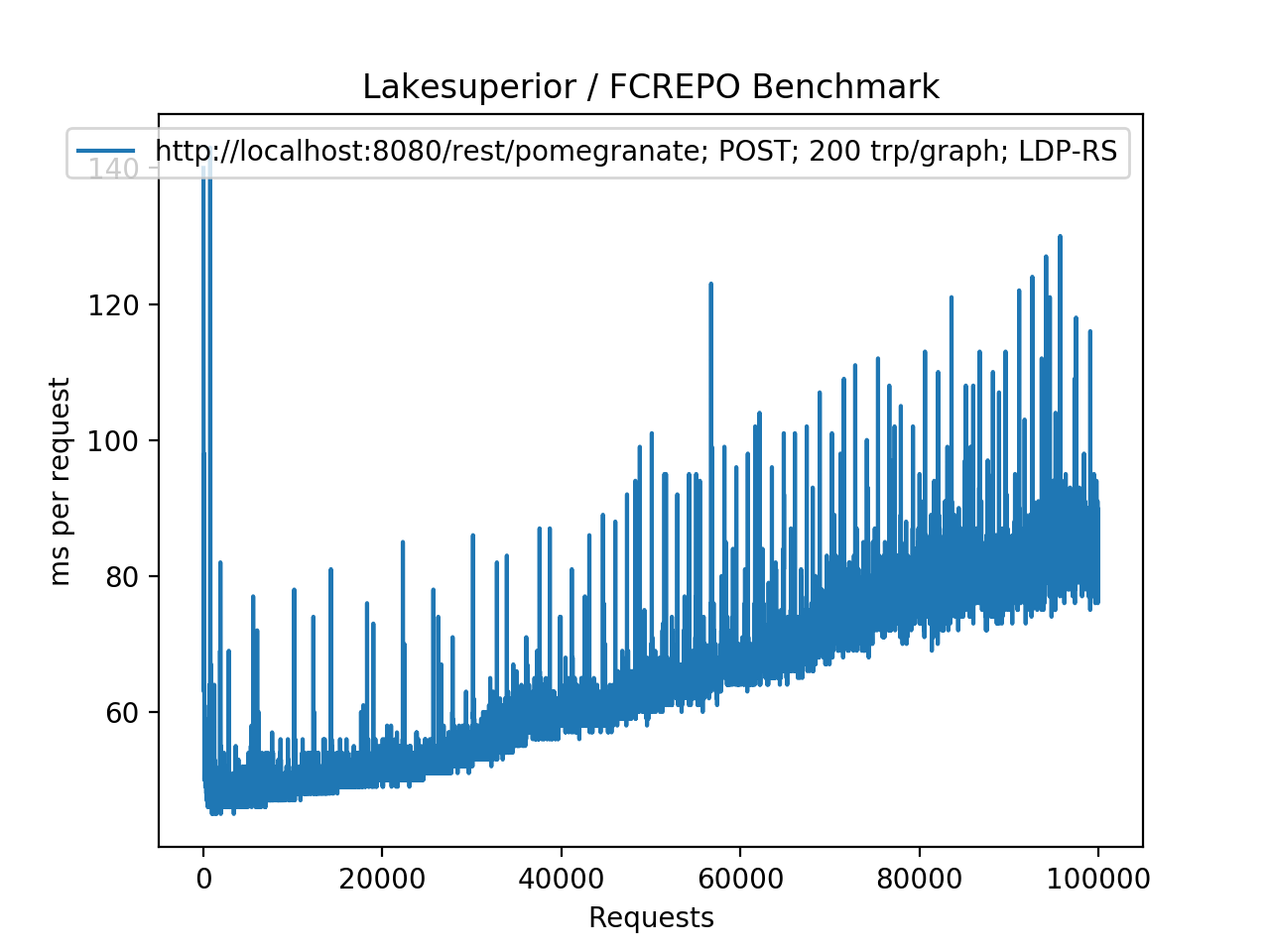
+.. figure:: assets/plot_lsup_post_100K.png
|
|
|
+ :alt: Lakesuperior with POST, 100K request time chart
|
|
|
+
|
|
|
+ Lakesuperior using POST requests, NOT generating pairtrees (equivalent to
|
|
|
+ a PUT request). The timing increase is closer to a O(log n) pattern.
|
|
|
+
|
|
|
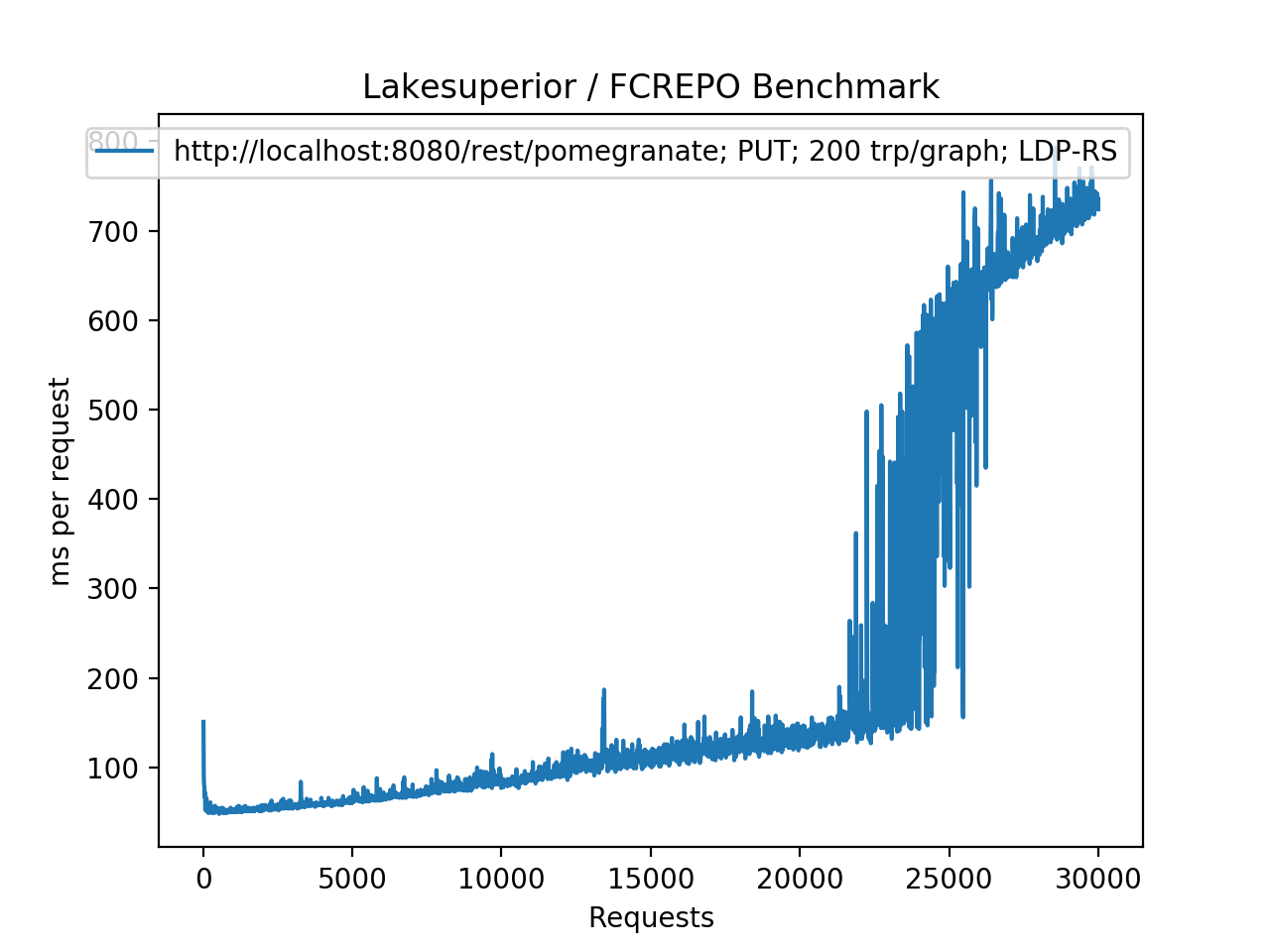
+.. figure:: assets/plot_lsup_pyapi_post_100K.png
|
|
|
+ :alt: Lakesuperior Python API, 100K request time chart
|
|
|
+
|
|
|
+ Lakesuperior using Python API. The pattern is much smoother, with less
|
|
|
+ frequent and less pronounced spikes. The O(log n) performance is more
|
|
|
+ clearly visile here: time increases quickly at the beginning, then slows
|
|
|
+ down as the repository size increases.
|
|
|
|
|
|
Conclusions
|
|
|
-----------
|
|
|
|
|
|
-Lakesuperior appears to be markedly slower on writes and markedly faster
|
|
|
-on reads. Both these factors are very likely related to the underlying
|
|
|
-LMDB store which is optimized for read performance.
|
|
|
+Lakesuperior appears to be slower on writes and much faster on reads than
|
|
|
+Fedora 4-5. Both these factors are very likely related to the underlying LMDB
|
|
|
+store which is optimized for read performance. The write performance gap is
|
|
|
+more than filled when ingesting via the Python API.
|
|
|
|
|
|
In a real-world application scenario, in which a client may perform multiple
|
|
|
reads before and after storing resources, the write performance gap may
|
|
|
decrease. A Python application using the Python API for querying and writing
|
|
|
-would experience a dramatic improvement in reading timings, and somewhat in
|
|
|
-write timings.
|
|
|
-
|
|
|
-Comparison of results between the laptop and the server demonstrates
|
|
|
-that both read and write performance ratios between repository systems are
|
|
|
-identical in the two environments.
|
|
|
+would experience a dramatic improvement in read as well as write timings.
|
|
|
|
|
|
As it may be obvious, these are only very partial and specific
|
|
|
-results. They should not be taken as a thorough performance assessment.
|
|
|
-Such an assessment may be impossible and pointless to make given the
|
|
|
-very different nature of the storage models, which may behave radically
|
|
|
-differently depending on many variables.
|
|
|
+results. They should not be taken as a thorough performance assessment, but
|
|
|
+rather as a starting point to which specific use-case variables may be added.
|

 Stefano Cossu
Stefano Cossu
{kind=link}

{kind=link}
{kind=link}
{kind=link}
{kind=link}