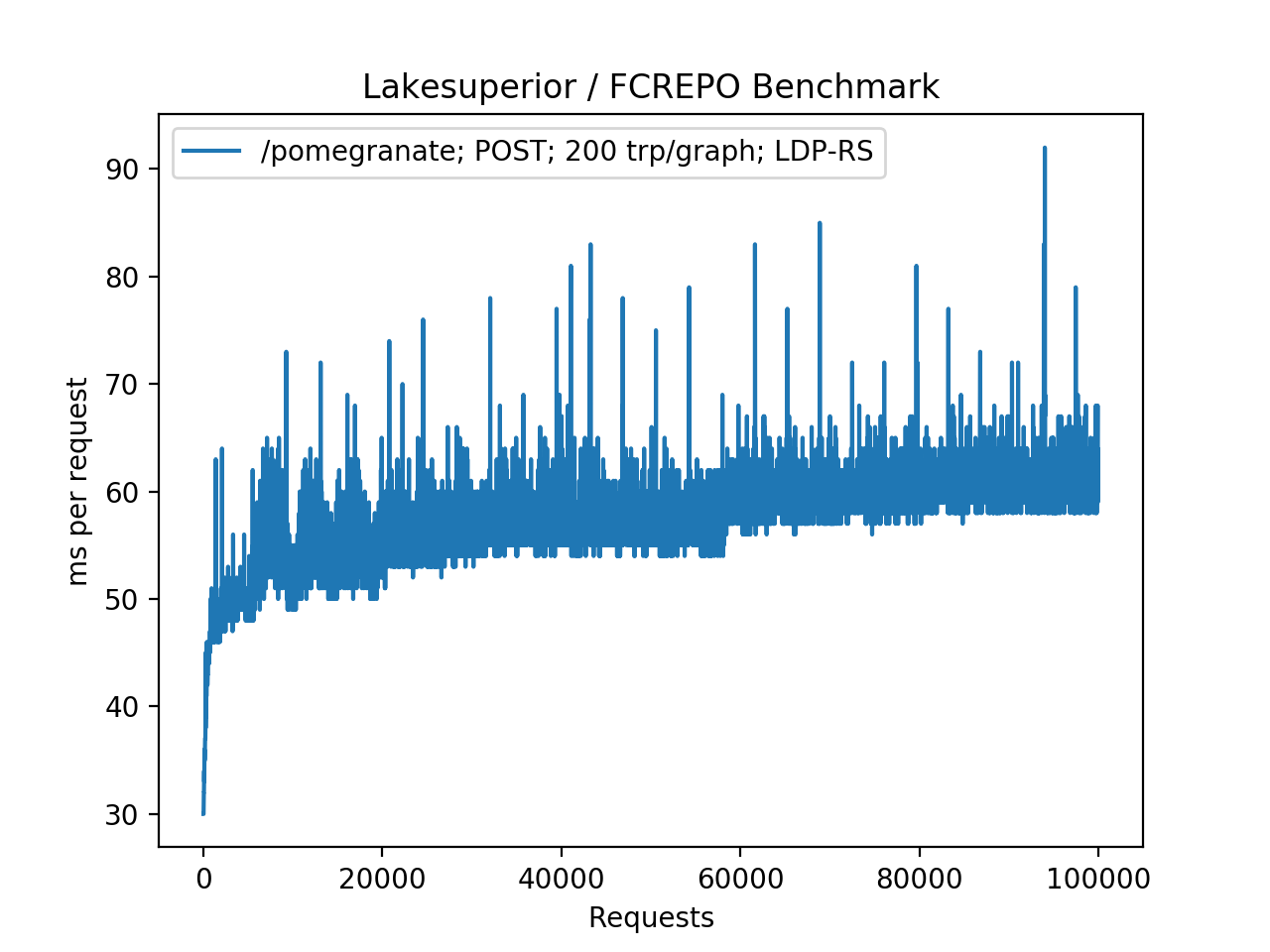
|
|
@@ -1,10266 +0,0 @@
|
|
|
-/** @file mdb.c
|
|
|
- * @brief Lightning memory-mapped database library
|
|
|
- *
|
|
|
- * A Btree-based database management library modeled loosely on the
|
|
|
- * BerkeleyDB API, but much simplified.
|
|
|
- */
|
|
|
-/*
|
|
|
- * Copyright 2011-2018 Howard Chu, Symas Corp.
|
|
|
- * All rights reserved.
|
|
|
- *
|
|
|
- * Redistribution and use in source and binary forms, with or without
|
|
|
- * modification, are permitted only as authorized by the OpenLDAP
|
|
|
- * Public License.
|
|
|
- *
|
|
|
- * A copy of this license is available in the file LICENSE in the
|
|
|
- * top-level directory of the distribution or, alternatively, at
|
|
|
- * <http://www.OpenLDAP.org/license.html>.
|
|
|
- *
|
|
|
- * This code is derived from btree.c written by Martin Hedenfalk.
|
|
|
- *
|
|
|
- * Copyright (c) 2009, 2010 Martin Hedenfalk <martin@bzero.se>
|
|
|
- *
|
|
|
- * Permission to use, copy, modify, and distribute this software for any
|
|
|
- * purpose with or without fee is hereby granted, provided that the above
|
|
|
- * copyright notice and this permission notice appear in all copies.
|
|
|
- *
|
|
|
- * THE SOFTWARE IS PROVIDED "AS IS" AND THE AUTHOR DISCLAIMS ALL WARRANTIES
|
|
|
- * WITH REGARD TO THIS SOFTWARE INCLUDING ALL IMPLIED WARRANTIES OF
|
|
|
- * MERCHANTABILITY AND FITNESS. IN NO EVENT SHALL THE AUTHOR BE LIABLE FOR
|
|
|
- * ANY SPECIAL, DIRECT, INDIRECT, OR CONSEQUENTIAL DAMAGES OR ANY DAMAGES
|
|
|
- * WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN AN
|
|
|
- * ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT OF
|
|
|
- * OR IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.
|
|
|
- */
|
|
|
-#ifndef _GNU_SOURCE
|
|
|
-#define _GNU_SOURCE 1
|
|
|
-#endif
|
|
|
-#if defined(__WIN64__)
|
|
|
-#define _FILE_OFFSET_BITS 64
|
|
|
-#endif
|
|
|
-#ifdef _WIN32
|
|
|
-#include <malloc.h>
|
|
|
-#include <windows.h>
|
|
|
-#include <wchar.h> /* get wcscpy() */
|
|
|
-
|
|
|
-/** getpid() returns int; MinGW defines pid_t but MinGW64 typedefs it
|
|
|
- * as int64 which is wrong. MSVC doesn't define it at all, so just
|
|
|
- * don't use it.
|
|
|
- */
|
|
|
-#define MDB_PID_T int
|
|
|
-#define MDB_THR_T DWORD
|
|
|
-#include <sys/types.h>
|
|
|
-#include <sys/stat.h>
|
|
|
-#ifdef __GNUC__
|
|
|
-# include <sys/param.h>
|
|
|
-#else
|
|
|
-# define LITTLE_ENDIAN 1234
|
|
|
-# define BIG_ENDIAN 4321
|
|
|
-# define BYTE_ORDER LITTLE_ENDIAN
|
|
|
-# ifndef SSIZE_MAX
|
|
|
-# define SSIZE_MAX INT_MAX
|
|
|
-# endif
|
|
|
-#endif
|
|
|
-#else
|
|
|
-#include <sys/types.h>
|
|
|
-#include <sys/stat.h>
|
|
|
-#define MDB_PID_T pid_t
|
|
|
-#define MDB_THR_T pthread_t
|
|
|
-#include <sys/param.h>
|
|
|
-#include <sys/uio.h>
|
|
|
-#include <sys/mman.h>
|
|
|
-#ifdef HAVE_SYS_FILE_H
|
|
|
-#include <sys/file.h>
|
|
|
-#endif
|
|
|
-#include <fcntl.h>
|
|
|
-#endif
|
|
|
-
|
|
|
-#if defined(__mips) && defined(__linux)
|
|
|
-/* MIPS has cache coherency issues, requires explicit cache control */
|
|
|
-#include <asm/cachectl.h>
|
|
|
-extern int cacheflush(char *addr, int nbytes, int cache);
|
|
|
-#define CACHEFLUSH(addr, bytes, cache) cacheflush(addr, bytes, cache)
|
|
|
-#else
|
|
|
-#define CACHEFLUSH(addr, bytes, cache)
|
|
|
-#endif
|
|
|
-
|
|
|
-#if defined(__linux) && !defined(MDB_FDATASYNC_WORKS)
|
|
|
-/** fdatasync is broken on ext3/ext4fs on older kernels, see
|
|
|
- * description in #mdb_env_open2 comments. You can safely
|
|
|
- * define MDB_FDATASYNC_WORKS if this code will only be run
|
|
|
- * on kernels 3.6 and newer.
|
|
|
- */
|
|
|
-#define BROKEN_FDATASYNC
|
|
|
-#endif
|
|
|
-
|
|
|
-#include <errno.h>
|
|
|
-#include <limits.h>
|
|
|
-#include <stddef.h>
|
|
|
-#include <inttypes.h>
|
|
|
-#include <stdio.h>
|
|
|
-#include <stdlib.h>
|
|
|
-#include <string.h>
|
|
|
-#include <time.h>
|
|
|
-
|
|
|
-#ifdef _MSC_VER
|
|
|
-#include <io.h>
|
|
|
-typedef SSIZE_T ssize_t;
|
|
|
-#else
|
|
|
-#include <unistd.h>
|
|
|
-#endif
|
|
|
-
|
|
|
-#if defined(__sun) || defined(ANDROID)
|
|
|
-/* Most platforms have posix_memalign, older may only have memalign */
|
|
|
-#define HAVE_MEMALIGN 1
|
|
|
-#include <malloc.h>
|
|
|
-/* On Solaris, we need the POSIX sigwait function */
|
|
|
-#if defined (__sun)
|
|
|
-# define _POSIX_PTHREAD_SEMANTICS 1
|
|
|
-#endif
|
|
|
-#endif
|
|
|
-
|
|
|
-#if !(defined(BYTE_ORDER) || defined(__BYTE_ORDER))
|
|
|
-#include <netinet/in.h>
|
|
|
-#include <resolv.h> /* defines BYTE_ORDER on HPUX and Solaris */
|
|
|
-#endif
|
|
|
-
|
|
|
-#if defined(__APPLE__) || defined (BSD) || defined(__FreeBSD_kernel__)
|
|
|
-# define MDB_USE_POSIX_SEM 1
|
|
|
-# define MDB_FDATASYNC fsync
|
|
|
-#elif defined(ANDROID)
|
|
|
-# define MDB_FDATASYNC fsync
|
|
|
-#endif
|
|
|
-
|
|
|
-#ifndef _WIN32
|
|
|
-#include <pthread.h>
|
|
|
-#include <signal.h>
|
|
|
-#ifdef MDB_USE_POSIX_SEM
|
|
|
-# define MDB_USE_HASH 1
|
|
|
-#include <semaphore.h>
|
|
|
-#else
|
|
|
-#define MDB_USE_POSIX_MUTEX 1
|
|
|
-#endif
|
|
|
-#endif
|
|
|
-
|
|
|
-#if defined(_WIN32) + defined(MDB_USE_POSIX_SEM) \
|
|
|
- + defined(MDB_USE_POSIX_MUTEX) != 1
|
|
|
-# error "Ambiguous shared-lock implementation"
|
|
|
-#endif
|
|
|
-
|
|
|
-#ifdef USE_VALGRIND
|
|
|
-#include <valgrind/memcheck.h>
|
|
|
-#define VGMEMP_CREATE(h,r,z) VALGRIND_CREATE_MEMPOOL(h,r,z)
|
|
|
-#define VGMEMP_ALLOC(h,a,s) VALGRIND_MEMPOOL_ALLOC(h,a,s)
|
|
|
-#define VGMEMP_FREE(h,a) VALGRIND_MEMPOOL_FREE(h,a)
|
|
|
-#define VGMEMP_DESTROY(h) VALGRIND_DESTROY_MEMPOOL(h)
|
|
|
-#define VGMEMP_DEFINED(a,s) VALGRIND_MAKE_MEM_DEFINED(a,s)
|
|
|
-#else
|
|
|
-#define VGMEMP_CREATE(h,r,z)
|
|
|
-#define VGMEMP_ALLOC(h,a,s)
|
|
|
-#define VGMEMP_FREE(h,a)
|
|
|
-#define VGMEMP_DESTROY(h)
|
|
|
-#define VGMEMP_DEFINED(a,s)
|
|
|
-#endif
|
|
|
-
|
|
|
-#ifndef BYTE_ORDER
|
|
|
-# if (defined(_LITTLE_ENDIAN) || defined(_BIG_ENDIAN)) && !(defined(_LITTLE_ENDIAN) && defined(_BIG_ENDIAN))
|
|
|
-/* Solaris just defines one or the other */
|
|
|
-# define LITTLE_ENDIAN 1234
|
|
|
-# define BIG_ENDIAN 4321
|
|
|
-# ifdef _LITTLE_ENDIAN
|
|
|
-# define BYTE_ORDER LITTLE_ENDIAN
|
|
|
-# else
|
|
|
-# define BYTE_ORDER BIG_ENDIAN
|
|
|
-# endif
|
|
|
-# else
|
|
|
-# define BYTE_ORDER __BYTE_ORDER
|
|
|
-# endif
|
|
|
-#endif
|
|
|
-
|
|
|
-#ifndef LITTLE_ENDIAN
|
|
|
-#define LITTLE_ENDIAN __LITTLE_ENDIAN
|
|
|
-#endif
|
|
|
-#ifndef BIG_ENDIAN
|
|
|
-#define BIG_ENDIAN __BIG_ENDIAN
|
|
|
-#endif
|
|
|
-
|
|
|
-#if defined(__i386) || defined(__x86_64) || defined(_M_IX86)
|
|
|
-#define MISALIGNED_OK 1
|
|
|
-#endif
|
|
|
-
|
|
|
-#include "lmdb.h"
|
|
|
-#include "midl.h"
|
|
|
-
|
|
|
-#if (BYTE_ORDER == LITTLE_ENDIAN) == (BYTE_ORDER == BIG_ENDIAN)
|
|
|
-# error "Unknown or unsupported endianness (BYTE_ORDER)"
|
|
|
-#elif (-6 & 5) || CHAR_BIT != 8 || UINT_MAX < 0xffffffff || ULONG_MAX % 0xFFFF
|
|
|
-# error "Two's complement, reasonably sized integer types, please"
|
|
|
-#endif
|
|
|
-
|
|
|
-#ifdef __GNUC__
|
|
|
-/** Put infrequently used env functions in separate section */
|
|
|
-# ifdef __APPLE__
|
|
|
-# define ESECT __attribute__ ((section("__TEXT,text_env")))
|
|
|
-# else
|
|
|
-# define ESECT __attribute__ ((section("text_env")))
|
|
|
-# endif
|
|
|
-#else
|
|
|
-#define ESECT
|
|
|
-#endif
|
|
|
-
|
|
|
-#ifdef _WIN32
|
|
|
-#define CALL_CONV WINAPI
|
|
|
-#else
|
|
|
-#define CALL_CONV
|
|
|
-#endif
|
|
|
-
|
|
|
-/** @defgroup internal LMDB Internals
|
|
|
- * @{
|
|
|
- */
|
|
|
-/** @defgroup compat Compatibility Macros
|
|
|
- * A bunch of macros to minimize the amount of platform-specific ifdefs
|
|
|
- * needed throughout the rest of the code. When the features this library
|
|
|
- * needs are similar enough to POSIX to be hidden in a one-or-two line
|
|
|
- * replacement, this macro approach is used.
|
|
|
- * @{
|
|
|
- */
|
|
|
-
|
|
|
- /** Features under development */
|
|
|
-#ifndef MDB_DEVEL
|
|
|
-#define MDB_DEVEL 0
|
|
|
-#endif
|
|
|
-
|
|
|
- /** Wrapper around __func__, which is a C99 feature */
|
|
|
-#if __STDC_VERSION__ >= 199901L
|
|
|
-# define mdb_func_ __func__
|
|
|
-#elif __GNUC__ >= 2 || _MSC_VER >= 1300
|
|
|
-# define mdb_func_ __FUNCTION__
|
|
|
-#else
|
|
|
-/* If a debug message says <mdb_unknown>(), update the #if statements above */
|
|
|
-# define mdb_func_ "<mdb_unknown>"
|
|
|
-#endif
|
|
|
-
|
|
|
-/* Internal error codes, not exposed outside liblmdb */
|
|
|
-#define MDB_NO_ROOT (MDB_LAST_ERRCODE + 10)
|
|
|
-#ifdef _WIN32
|
|
|
-#define MDB_OWNERDEAD ((int) WAIT_ABANDONED)
|
|
|
-#elif defined(MDB_USE_POSIX_MUTEX) && defined(EOWNERDEAD)
|
|
|
-#define MDB_OWNERDEAD EOWNERDEAD /**< #LOCK_MUTEX0() result if dead owner */
|
|
|
-#endif
|
|
|
-
|
|
|
-#ifdef __GLIBC__
|
|
|
-#define GLIBC_VER ((__GLIBC__ << 16 )| __GLIBC_MINOR__)
|
|
|
-#endif
|
|
|
-/** Some platforms define the EOWNERDEAD error code
|
|
|
- * even though they don't support Robust Mutexes.
|
|
|
- * Compile with -DMDB_USE_ROBUST=0, or use some other
|
|
|
- * mechanism like -DMDB_USE_POSIX_SEM instead of
|
|
|
- * -DMDB_USE_POSIX_MUTEX.
|
|
|
- * (Posix semaphores are not robust.)
|
|
|
- */
|
|
|
-#ifndef MDB_USE_ROBUST
|
|
|
-/* Android currently lacks Robust Mutex support. So does glibc < 2.4. */
|
|
|
-# if defined(MDB_USE_POSIX_MUTEX) && (defined(ANDROID) || \
|
|
|
- (defined(__GLIBC__) && GLIBC_VER < 0x020004))
|
|
|
-# define MDB_USE_ROBUST 0
|
|
|
-# else
|
|
|
-# define MDB_USE_ROBUST 1
|
|
|
-# endif
|
|
|
-#endif /* !MDB_USE_ROBUST */
|
|
|
-
|
|
|
-#if defined(MDB_USE_POSIX_MUTEX) && (MDB_USE_ROBUST)
|
|
|
-/* glibc < 2.12 only provided _np API */
|
|
|
-# if (defined(__GLIBC__) && GLIBC_VER < 0x02000c) || \
|
|
|
- (defined(PTHREAD_MUTEX_ROBUST_NP) && !defined(PTHREAD_MUTEX_ROBUST))
|
|
|
-# define PTHREAD_MUTEX_ROBUST PTHREAD_MUTEX_ROBUST_NP
|
|
|
-# define pthread_mutexattr_setrobust(attr, flag) pthread_mutexattr_setrobust_np(attr, flag)
|
|
|
-# define pthread_mutex_consistent(mutex) pthread_mutex_consistent_np(mutex)
|
|
|
-# endif
|
|
|
-#endif /* MDB_USE_POSIX_MUTEX && MDB_USE_ROBUST */
|
|
|
-
|
|
|
-#if defined(MDB_OWNERDEAD) && (MDB_USE_ROBUST)
|
|
|
-#define MDB_ROBUST_SUPPORTED 1
|
|
|
-#endif
|
|
|
-
|
|
|
-#ifdef _WIN32
|
|
|
-#define MDB_USE_HASH 1
|
|
|
-#define MDB_PIDLOCK 0
|
|
|
-#define THREAD_RET DWORD
|
|
|
-#define pthread_t HANDLE
|
|
|
-#define pthread_mutex_t HANDLE
|
|
|
-#define pthread_cond_t HANDLE
|
|
|
-typedef HANDLE mdb_mutex_t, mdb_mutexref_t;
|
|
|
-#define pthread_key_t DWORD
|
|
|
-#define pthread_self() GetCurrentThreadId()
|
|
|
-#define pthread_key_create(x,y) \
|
|
|
- ((*(x) = TlsAlloc()) == TLS_OUT_OF_INDEXES ? ErrCode() : 0)
|
|
|
-#define pthread_key_delete(x) TlsFree(x)
|
|
|
-#define pthread_getspecific(x) TlsGetValue(x)
|
|
|
-#define pthread_setspecific(x,y) (TlsSetValue(x,y) ? 0 : ErrCode())
|
|
|
-#define pthread_mutex_unlock(x) ReleaseMutex(*x)
|
|
|
-#define pthread_mutex_lock(x) WaitForSingleObject(*x, INFINITE)
|
|
|
-#define pthread_cond_signal(x) SetEvent(*x)
|
|
|
-#define pthread_cond_wait(cond,mutex) do{SignalObjectAndWait(*mutex, *cond, INFINITE, FALSE); WaitForSingleObject(*mutex, INFINITE);}while(0)
|
|
|
-#define THREAD_CREATE(thr,start,arg) \
|
|
|
- (((thr) = CreateThread(NULL, 0, start, arg, 0, NULL)) ? 0 : ErrCode())
|
|
|
-#define THREAD_FINISH(thr) \
|
|
|
- (WaitForSingleObject(thr, INFINITE) ? ErrCode() : 0)
|
|
|
-#define LOCK_MUTEX0(mutex) WaitForSingleObject(mutex, INFINITE)
|
|
|
-#define UNLOCK_MUTEX(mutex) ReleaseMutex(mutex)
|
|
|
-#define mdb_mutex_consistent(mutex) 0
|
|
|
-#define getpid() GetCurrentProcessId()
|
|
|
-#define MDB_FDATASYNC(fd) (!FlushFileBuffers(fd))
|
|
|
-#define MDB_MSYNC(addr,len,flags) (!FlushViewOfFile(addr,len))
|
|
|
-#define ErrCode() GetLastError()
|
|
|
-#define GET_PAGESIZE(x) {SYSTEM_INFO si; GetSystemInfo(&si); (x) = si.dwPageSize;}
|
|
|
-#define close(fd) (CloseHandle(fd) ? 0 : -1)
|
|
|
-#define munmap(ptr,len) UnmapViewOfFile(ptr)
|
|
|
-#ifdef PROCESS_QUERY_LIMITED_INFORMATION
|
|
|
-#define MDB_PROCESS_QUERY_LIMITED_INFORMATION PROCESS_QUERY_LIMITED_INFORMATION
|
|
|
-#else
|
|
|
-#define MDB_PROCESS_QUERY_LIMITED_INFORMATION 0x1000
|
|
|
-#endif
|
|
|
-#define Z "I"
|
|
|
-#else
|
|
|
-#define THREAD_RET void *
|
|
|
-#define THREAD_CREATE(thr,start,arg) pthread_create(&thr,NULL,start,arg)
|
|
|
-#define THREAD_FINISH(thr) pthread_join(thr,NULL)
|
|
|
-#define Z "z" /**< printf format modifier for size_t */
|
|
|
-
|
|
|
- /** For MDB_LOCK_FORMAT: True if readers take a pid lock in the lockfile */
|
|
|
-#define MDB_PIDLOCK 1
|
|
|
-
|
|
|
-#ifdef MDB_USE_POSIX_SEM
|
|
|
-
|
|
|
-typedef sem_t *mdb_mutex_t, *mdb_mutexref_t;
|
|
|
-#define LOCK_MUTEX0(mutex) mdb_sem_wait(mutex)
|
|
|
-#define UNLOCK_MUTEX(mutex) sem_post(mutex)
|
|
|
-
|
|
|
-static int
|
|
|
-mdb_sem_wait(sem_t *sem)
|
|
|
-{
|
|
|
- int rc;
|
|
|
- while ((rc = sem_wait(sem)) && (rc = errno) == EINTR) ;
|
|
|
- return rc;
|
|
|
-}
|
|
|
-
|
|
|
-#else /* MDB_USE_POSIX_MUTEX: */
|
|
|
- /** Shared mutex/semaphore as the original is stored.
|
|
|
- *
|
|
|
- * Not for copies. Instead it can be assigned to an #mdb_mutexref_t.
|
|
|
- * When mdb_mutexref_t is a pointer and mdb_mutex_t is not, then it
|
|
|
- * is array[size 1] so it can be assigned to the pointer.
|
|
|
- */
|
|
|
-typedef pthread_mutex_t mdb_mutex_t[1];
|
|
|
- /** Reference to an #mdb_mutex_t */
|
|
|
-typedef pthread_mutex_t *mdb_mutexref_t;
|
|
|
- /** Lock the reader or writer mutex.
|
|
|
- * Returns 0 or a code to give #mdb_mutex_failed(), as in #LOCK_MUTEX().
|
|
|
- */
|
|
|
-#define LOCK_MUTEX0(mutex) pthread_mutex_lock(mutex)
|
|
|
- /** Unlock the reader or writer mutex.
|
|
|
- */
|
|
|
-#define UNLOCK_MUTEX(mutex) pthread_mutex_unlock(mutex)
|
|
|
- /** Mark mutex-protected data as repaired, after death of previous owner.
|
|
|
- */
|
|
|
-#define mdb_mutex_consistent(mutex) pthread_mutex_consistent(mutex)
|
|
|
-#endif /* MDB_USE_POSIX_SEM */
|
|
|
-
|
|
|
- /** Get the error code for the last failed system function.
|
|
|
- */
|
|
|
-#define ErrCode() errno
|
|
|
-
|
|
|
- /** An abstraction for a file handle.
|
|
|
- * On POSIX systems file handles are small integers. On Windows
|
|
|
- * they're opaque pointers.
|
|
|
- */
|
|
|
-#define HANDLE int
|
|
|
-
|
|
|
- /** A value for an invalid file handle.
|
|
|
- * Mainly used to initialize file variables and signify that they are
|
|
|
- * unused.
|
|
|
- */
|
|
|
-#define INVALID_HANDLE_VALUE (-1)
|
|
|
-
|
|
|
- /** Get the size of a memory page for the system.
|
|
|
- * This is the basic size that the platform's memory manager uses, and is
|
|
|
- * fundamental to the use of memory-mapped files.
|
|
|
- */
|
|
|
-#define GET_PAGESIZE(x) ((x) = sysconf(_SC_PAGE_SIZE))
|
|
|
-#endif
|
|
|
-
|
|
|
-#if defined(_WIN32) || defined(MDB_USE_POSIX_SEM)
|
|
|
-#define MNAME_LEN 32
|
|
|
-#else
|
|
|
-#define MNAME_LEN (sizeof(pthread_mutex_t))
|
|
|
-#endif
|
|
|
-
|
|
|
-/** @} */
|
|
|
-
|
|
|
-#ifdef MDB_ROBUST_SUPPORTED
|
|
|
- /** Lock mutex, handle any error, set rc = result.
|
|
|
- * Return 0 on success, nonzero (not rc) on error.
|
|
|
- */
|
|
|
-#define LOCK_MUTEX(rc, env, mutex) \
|
|
|
- (((rc) = LOCK_MUTEX0(mutex)) && \
|
|
|
- ((rc) = mdb_mutex_failed(env, mutex, rc)))
|
|
|
-static int mdb_mutex_failed(MDB_env *env, mdb_mutexref_t mutex, int rc);
|
|
|
-#else
|
|
|
-#define LOCK_MUTEX(rc, env, mutex) ((rc) = LOCK_MUTEX0(mutex))
|
|
|
-#define mdb_mutex_failed(env, mutex, rc) (rc)
|
|
|
-#endif
|
|
|
-
|
|
|
-#ifndef _WIN32
|
|
|
-/** A flag for opening a file and requesting synchronous data writes.
|
|
|
- * This is only used when writing a meta page. It's not strictly needed;
|
|
|
- * we could just do a normal write and then immediately perform a flush.
|
|
|
- * But if this flag is available it saves us an extra system call.
|
|
|
- *
|
|
|
- * @note If O_DSYNC is undefined but exists in /usr/include,
|
|
|
- * preferably set some compiler flag to get the definition.
|
|
|
- */
|
|
|
-#ifndef MDB_DSYNC
|
|
|
-# ifdef O_DSYNC
|
|
|
-# define MDB_DSYNC O_DSYNC
|
|
|
-# else
|
|
|
-# define MDB_DSYNC O_SYNC
|
|
|
-# endif
|
|
|
-#endif
|
|
|
-#endif
|
|
|
-
|
|
|
-/** Function for flushing the data of a file. Define this to fsync
|
|
|
- * if fdatasync() is not supported.
|
|
|
- */
|
|
|
-#ifndef MDB_FDATASYNC
|
|
|
-# define MDB_FDATASYNC fdatasync
|
|
|
-#endif
|
|
|
-
|
|
|
-#ifndef MDB_MSYNC
|
|
|
-# define MDB_MSYNC(addr,len,flags) msync(addr,len,flags)
|
|
|
-#endif
|
|
|
-
|
|
|
-#ifndef MS_SYNC
|
|
|
-#define MS_SYNC 1
|
|
|
-#endif
|
|
|
-
|
|
|
-#ifndef MS_ASYNC
|
|
|
-#define MS_ASYNC 0
|
|
|
-#endif
|
|
|
-
|
|
|
- /** A page number in the database.
|
|
|
- * Note that 64 bit page numbers are overkill, since pages themselves
|
|
|
- * already represent 12-13 bits of addressable memory, and the OS will
|
|
|
- * always limit applications to a maximum of 63 bits of address space.
|
|
|
- *
|
|
|
- * @note In the #MDB_node structure, we only store 48 bits of this value,
|
|
|
- * which thus limits us to only 60 bits of addressable data.
|
|
|
- */
|
|
|
-typedef MDB_ID pgno_t;
|
|
|
-
|
|
|
- /** A transaction ID.
|
|
|
- * See struct MDB_txn.mt_txnid for details.
|
|
|
- */
|
|
|
-typedef MDB_ID txnid_t;
|
|
|
-
|
|
|
-/** @defgroup debug Debug Macros
|
|
|
- * @{
|
|
|
- */
|
|
|
-#ifndef MDB_DEBUG
|
|
|
- /** Enable debug output. Needs variable argument macros (a C99 feature).
|
|
|
- * Set this to 1 for copious tracing. Set to 2 to add dumps of all IDLs
|
|
|
- * read from and written to the database (used for free space management).
|
|
|
- */
|
|
|
-#define MDB_DEBUG 0
|
|
|
-#endif
|
|
|
-
|
|
|
-#if MDB_DEBUG
|
|
|
-static int mdb_debug;
|
|
|
-static txnid_t mdb_debug_start;
|
|
|
-
|
|
|
- /** Print a debug message with printf formatting.
|
|
|
- * Requires double parenthesis around 2 or more args.
|
|
|
- */
|
|
|
-# define DPRINTF(args) ((void) ((mdb_debug) && DPRINTF0 args))
|
|
|
-# define DPRINTF0(fmt, ...) \
|
|
|
- fprintf(stderr, "%s:%d " fmt "\n", mdb_func_, __LINE__, __VA_ARGS__)
|
|
|
-#else
|
|
|
-# define DPRINTF(args) ((void) 0)
|
|
|
-#endif
|
|
|
- /** Print a debug string.
|
|
|
- * The string is printed literally, with no format processing.
|
|
|
- */
|
|
|
-#define DPUTS(arg) DPRINTF(("%s", arg))
|
|
|
- /** Debuging output value of a cursor DBI: Negative in a sub-cursor. */
|
|
|
-#define DDBI(mc) \
|
|
|
- (((mc)->mc_flags & C_SUB) ? -(int)(mc)->mc_dbi : (int)(mc)->mc_dbi)
|
|
|
-/** @} */
|
|
|
-
|
|
|
- /** @brief The maximum size of a database page.
|
|
|
- *
|
|
|
- * It is 32k or 64k, since value-PAGEBASE must fit in
|
|
|
- * #MDB_page.%mp_upper.
|
|
|
- *
|
|
|
- * LMDB will use database pages < OS pages if needed.
|
|
|
- * That causes more I/O in write transactions: The OS must
|
|
|
- * know (read) the whole page before writing a partial page.
|
|
|
- *
|
|
|
- * Note that we don't currently support Huge pages. On Linux,
|
|
|
- * regular data files cannot use Huge pages, and in general
|
|
|
- * Huge pages aren't actually pageable. We rely on the OS
|
|
|
- * demand-pager to read our data and page it out when memory
|
|
|
- * pressure from other processes is high. So until OSs have
|
|
|
- * actual paging support for Huge pages, they're not viable.
|
|
|
- */
|
|
|
-#define MAX_PAGESIZE (PAGEBASE ? 0x10000 : 0x8000)
|
|
|
-
|
|
|
- /** The minimum number of keys required in a database page.
|
|
|
- * Setting this to a larger value will place a smaller bound on the
|
|
|
- * maximum size of a data item. Data items larger than this size will
|
|
|
- * be pushed into overflow pages instead of being stored directly in
|
|
|
- * the B-tree node. This value used to default to 4. With a page size
|
|
|
- * of 4096 bytes that meant that any item larger than 1024 bytes would
|
|
|
- * go into an overflow page. That also meant that on average 2-3KB of
|
|
|
- * each overflow page was wasted space. The value cannot be lower than
|
|
|
- * 2 because then there would no longer be a tree structure. With this
|
|
|
- * value, items larger than 2KB will go into overflow pages, and on
|
|
|
- * average only 1KB will be wasted.
|
|
|
- */
|
|
|
-#define MDB_MINKEYS 2
|
|
|
-
|
|
|
- /** A stamp that identifies a file as an LMDB file.
|
|
|
- * There's nothing special about this value other than that it is easily
|
|
|
- * recognizable, and it will reflect any byte order mismatches.
|
|
|
- */
|
|
|
-#define MDB_MAGIC 0xBEEFC0DE
|
|
|
-
|
|
|
- /** The version number for a database's datafile format. */
|
|
|
-#define MDB_DATA_VERSION ((MDB_DEVEL) ? 999 : 1)
|
|
|
- /** The version number for a database's lockfile format. */
|
|
|
-#define MDB_LOCK_VERSION 1
|
|
|
-
|
|
|
- /** @brief The max size of a key we can write, or 0 for computed max.
|
|
|
- *
|
|
|
- * This macro should normally be left alone or set to 0.
|
|
|
- * Note that a database with big keys or dupsort data cannot be
|
|
|
- * reliably modified by a liblmdb which uses a smaller max.
|
|
|
- * The default is 511 for backwards compat, or 0 when #MDB_DEVEL.
|
|
|
- *
|
|
|
- * Other values are allowed, for backwards compat. However:
|
|
|
- * A value bigger than the computed max can break if you do not
|
|
|
- * know what you are doing, and liblmdb <= 0.9.10 can break when
|
|
|
- * modifying a DB with keys/dupsort data bigger than its max.
|
|
|
- *
|
|
|
- * Data items in an #MDB_DUPSORT database are also limited to
|
|
|
- * this size, since they're actually keys of a sub-DB. Keys and
|
|
|
- * #MDB_DUPSORT data items must fit on a node in a regular page.
|
|
|
- */
|
|
|
-#ifndef MDB_MAXKEYSIZE
|
|
|
-#define MDB_MAXKEYSIZE ((MDB_DEVEL) ? 0 : 511)
|
|
|
-#endif
|
|
|
-
|
|
|
- /** The maximum size of a key we can write to the environment. */
|
|
|
-#if MDB_MAXKEYSIZE
|
|
|
-#define ENV_MAXKEY(env) (MDB_MAXKEYSIZE)
|
|
|
-#else
|
|
|
-#define ENV_MAXKEY(env) ((env)->me_maxkey)
|
|
|
-#endif
|
|
|
-
|
|
|
- /** @brief The maximum size of a data item.
|
|
|
- *
|
|
|
- * We only store a 32 bit value for node sizes.
|
|
|
- */
|
|
|
-#define MAXDATASIZE 0xffffffffUL
|
|
|
-
|
|
|
-#if MDB_DEBUG
|
|
|
- /** Key size which fits in a #DKBUF.
|
|
|
- * @ingroup debug
|
|
|
- */
|
|
|
-#define DKBUF_MAXKEYSIZE ((MDB_MAXKEYSIZE) > 0 ? (MDB_MAXKEYSIZE) : 511)
|
|
|
- /** A key buffer.
|
|
|
- * @ingroup debug
|
|
|
- * This is used for printing a hex dump of a key's contents.
|
|
|
- */
|
|
|
-#define DKBUF char kbuf[DKBUF_MAXKEYSIZE*2+1]
|
|
|
- /** Display a key in hex.
|
|
|
- * @ingroup debug
|
|
|
- * Invoke a function to display a key in hex.
|
|
|
- */
|
|
|
-#define DKEY(x) mdb_dkey(x, kbuf)
|
|
|
-#else
|
|
|
-#define DKBUF
|
|
|
-#define DKEY(x) 0
|
|
|
-#endif
|
|
|
-
|
|
|
- /** An invalid page number.
|
|
|
- * Mainly used to denote an empty tree.
|
|
|
- */
|
|
|
-#define P_INVALID (~(pgno_t)0)
|
|
|
-
|
|
|
- /** Test if the flags \b f are set in a flag word \b w. */
|
|
|
-#define F_ISSET(w, f) (((w) & (f)) == (f))
|
|
|
-
|
|
|
- /** Round \b n up to an even number. */
|
|
|
-#define EVEN(n) (((n) + 1U) & -2) /* sign-extending -2 to match n+1U */
|
|
|
-
|
|
|
- /** Used for offsets within a single page.
|
|
|
- * Since memory pages are typically 4 or 8KB in size, 12-13 bits,
|
|
|
- * this is plenty.
|
|
|
- */
|
|
|
-typedef uint16_t indx_t;
|
|
|
-
|
|
|
- /** Default size of memory map.
|
|
|
- * This is certainly too small for any actual applications. Apps should always set
|
|
|
- * the size explicitly using #mdb_env_set_mapsize().
|
|
|
- */
|
|
|
-#define DEFAULT_MAPSIZE 1048576
|
|
|
-
|
|
|
-/** @defgroup readers Reader Lock Table
|
|
|
- * Readers don't acquire any locks for their data access. Instead, they
|
|
|
- * simply record their transaction ID in the reader table. The reader
|
|
|
- * mutex is needed just to find an empty slot in the reader table. The
|
|
|
- * slot's address is saved in thread-specific data so that subsequent read
|
|
|
- * transactions started by the same thread need no further locking to proceed.
|
|
|
- *
|
|
|
- * If #MDB_NOTLS is set, the slot address is not saved in thread-specific data.
|
|
|
- *
|
|
|
- * No reader table is used if the database is on a read-only filesystem, or
|
|
|
- * if #MDB_NOLOCK is set.
|
|
|
- *
|
|
|
- * Since the database uses multi-version concurrency control, readers don't
|
|
|
- * actually need any locking. This table is used to keep track of which
|
|
|
- * readers are using data from which old transactions, so that we'll know
|
|
|
- * when a particular old transaction is no longer in use. Old transactions
|
|
|
- * that have discarded any data pages can then have those pages reclaimed
|
|
|
- * for use by a later write transaction.
|
|
|
- *
|
|
|
- * The lock table is constructed such that reader slots are aligned with the
|
|
|
- * processor's cache line size. Any slot is only ever used by one thread.
|
|
|
- * This alignment guarantees that there will be no contention or cache
|
|
|
- * thrashing as threads update their own slot info, and also eliminates
|
|
|
- * any need for locking when accessing a slot.
|
|
|
- *
|
|
|
- * A writer thread will scan every slot in the table to determine the oldest
|
|
|
- * outstanding reader transaction. Any freed pages older than this will be
|
|
|
- * reclaimed by the writer. The writer doesn't use any locks when scanning
|
|
|
- * this table. This means that there's no guarantee that the writer will
|
|
|
- * see the most up-to-date reader info, but that's not required for correct
|
|
|
- * operation - all we need is to know the upper bound on the oldest reader,
|
|
|
- * we don't care at all about the newest reader. So the only consequence of
|
|
|
- * reading stale information here is that old pages might hang around a
|
|
|
- * while longer before being reclaimed. That's actually good anyway, because
|
|
|
- * the longer we delay reclaiming old pages, the more likely it is that a
|
|
|
- * string of contiguous pages can be found after coalescing old pages from
|
|
|
- * many old transactions together.
|
|
|
- * @{
|
|
|
- */
|
|
|
- /** Number of slots in the reader table.
|
|
|
- * This value was chosen somewhat arbitrarily. 126 readers plus a
|
|
|
- * couple mutexes fit exactly into 8KB on my development machine.
|
|
|
- * Applications should set the table size using #mdb_env_set_maxreaders().
|
|
|
- */
|
|
|
-#define DEFAULT_READERS 126
|
|
|
-
|
|
|
- /** The size of a CPU cache line in bytes. We want our lock structures
|
|
|
- * aligned to this size to avoid false cache line sharing in the
|
|
|
- * lock table.
|
|
|
- * This value works for most CPUs. For Itanium this should be 128.
|
|
|
- */
|
|
|
-#ifndef CACHELINE
|
|
|
-#define CACHELINE 64
|
|
|
-#endif
|
|
|
-
|
|
|
- /** The information we store in a single slot of the reader table.
|
|
|
- * In addition to a transaction ID, we also record the process and
|
|
|
- * thread ID that owns a slot, so that we can detect stale information,
|
|
|
- * e.g. threads or processes that went away without cleaning up.
|
|
|
- * @note We currently don't check for stale records. We simply re-init
|
|
|
- * the table when we know that we're the only process opening the
|
|
|
- * lock file.
|
|
|
- */
|
|
|
-typedef struct MDB_rxbody {
|
|
|
- /** Current Transaction ID when this transaction began, or (txnid_t)-1.
|
|
|
- * Multiple readers that start at the same time will probably have the
|
|
|
- * same ID here. Again, it's not important to exclude them from
|
|
|
- * anything; all we need to know is which version of the DB they
|
|
|
- * started from so we can avoid overwriting any data used in that
|
|
|
- * particular version.
|
|
|
- */
|
|
|
- volatile txnid_t mrb_txnid;
|
|
|
- /** The process ID of the process owning this reader txn. */
|
|
|
- volatile MDB_PID_T mrb_pid;
|
|
|
- /** The thread ID of the thread owning this txn. */
|
|
|
- volatile MDB_THR_T mrb_tid;
|
|
|
-} MDB_rxbody;
|
|
|
-
|
|
|
- /** The actual reader record, with cacheline padding. */
|
|
|
-typedef struct MDB_reader {
|
|
|
- union {
|
|
|
- MDB_rxbody mrx;
|
|
|
- /** shorthand for mrb_txnid */
|
|
|
-#define mr_txnid mru.mrx.mrb_txnid
|
|
|
-#define mr_pid mru.mrx.mrb_pid
|
|
|
-#define mr_tid mru.mrx.mrb_tid
|
|
|
- /** cache line alignment */
|
|
|
- char pad[(sizeof(MDB_rxbody)+CACHELINE-1) & ~(CACHELINE-1)];
|
|
|
- } mru;
|
|
|
-} MDB_reader;
|
|
|
-
|
|
|
- /** The header for the reader table.
|
|
|
- * The table resides in a memory-mapped file. (This is a different file
|
|
|
- * than is used for the main database.)
|
|
|
- *
|
|
|
- * For POSIX the actual mutexes reside in the shared memory of this
|
|
|
- * mapped file. On Windows, mutexes are named objects allocated by the
|
|
|
- * kernel; we store the mutex names in this mapped file so that other
|
|
|
- * processes can grab them. This same approach is also used on
|
|
|
- * MacOSX/Darwin (using named semaphores) since MacOSX doesn't support
|
|
|
- * process-shared POSIX mutexes. For these cases where a named object
|
|
|
- * is used, the object name is derived from a 64 bit FNV hash of the
|
|
|
- * environment pathname. As such, naming collisions are extremely
|
|
|
- * unlikely. If a collision occurs, the results are unpredictable.
|
|
|
- */
|
|
|
-typedef struct MDB_txbody {
|
|
|
- /** Stamp identifying this as an LMDB file. It must be set
|
|
|
- * to #MDB_MAGIC. */
|
|
|
- uint32_t mtb_magic;
|
|
|
- /** Format of this lock file. Must be set to #MDB_LOCK_FORMAT. */
|
|
|
- uint32_t mtb_format;
|
|
|
-#if defined(_WIN32) || defined(MDB_USE_POSIX_SEM)
|
|
|
- char mtb_rmname[MNAME_LEN];
|
|
|
-#else
|
|
|
- /** Mutex protecting access to this table.
|
|
|
- * This is the reader table lock used with LOCK_MUTEX().
|
|
|
- */
|
|
|
- mdb_mutex_t mtb_rmutex;
|
|
|
-#endif
|
|
|
- /** The ID of the last transaction committed to the database.
|
|
|
- * This is recorded here only for convenience; the value can always
|
|
|
- * be determined by reading the main database meta pages.
|
|
|
- */
|
|
|
- volatile txnid_t mtb_txnid;
|
|
|
- /** The number of slots that have been used in the reader table.
|
|
|
- * This always records the maximum count, it is not decremented
|
|
|
- * when readers release their slots.
|
|
|
- */
|
|
|
- volatile unsigned mtb_numreaders;
|
|
|
-} MDB_txbody;
|
|
|
-
|
|
|
- /** The actual reader table definition. */
|
|
|
-typedef struct MDB_txninfo {
|
|
|
- union {
|
|
|
- MDB_txbody mtb;
|
|
|
-#define mti_magic mt1.mtb.mtb_magic
|
|
|
-#define mti_format mt1.mtb.mtb_format
|
|
|
-#define mti_rmutex mt1.mtb.mtb_rmutex
|
|
|
-#define mti_rmname mt1.mtb.mtb_rmname
|
|
|
-#define mti_txnid mt1.mtb.mtb_txnid
|
|
|
-#define mti_numreaders mt1.mtb.mtb_numreaders
|
|
|
- char pad[(sizeof(MDB_txbody)+CACHELINE-1) & ~(CACHELINE-1)];
|
|
|
- } mt1;
|
|
|
- union {
|
|
|
-#if defined(_WIN32) || defined(MDB_USE_POSIX_SEM)
|
|
|
- char mt2_wmname[MNAME_LEN];
|
|
|
-#define mti_wmname mt2.mt2_wmname
|
|
|
-#else
|
|
|
- mdb_mutex_t mt2_wmutex;
|
|
|
-#define mti_wmutex mt2.mt2_wmutex
|
|
|
-#endif
|
|
|
- char pad[(MNAME_LEN+CACHELINE-1) & ~(CACHELINE-1)];
|
|
|
- } mt2;
|
|
|
- MDB_reader mti_readers[1];
|
|
|
-} MDB_txninfo;
|
|
|
-
|
|
|
- /** Lockfile format signature: version, features and field layout */
|
|
|
-#define MDB_LOCK_FORMAT \
|
|
|
- ((uint32_t) \
|
|
|
- ((MDB_LOCK_VERSION) \
|
|
|
- /* Flags which describe functionality */ \
|
|
|
- + (((MDB_PIDLOCK) != 0) << 16)))
|
|
|
-/** @} */
|
|
|
-
|
|
|
-/** Common header for all page types. The page type depends on #mp_flags.
|
|
|
- *
|
|
|
- * #P_BRANCH and #P_LEAF pages have unsorted '#MDB_node's at the end, with
|
|
|
- * sorted #mp_ptrs[] entries referring to them. Exception: #P_LEAF2 pages
|
|
|
- * omit mp_ptrs and pack sorted #MDB_DUPFIXED values after the page header.
|
|
|
- *
|
|
|
- * #P_OVERFLOW records occupy one or more contiguous pages where only the
|
|
|
- * first has a page header. They hold the real data of #F_BIGDATA nodes.
|
|
|
- *
|
|
|
- * #P_SUBP sub-pages are small leaf "pages" with duplicate data.
|
|
|
- * A node with flag #F_DUPDATA but not #F_SUBDATA contains a sub-page.
|
|
|
- * (Duplicate data can also go in sub-databases, which use normal pages.)
|
|
|
- *
|
|
|
- * #P_META pages contain #MDB_meta, the start point of an LMDB snapshot.
|
|
|
- *
|
|
|
- * Each non-metapage up to #MDB_meta.%mm_last_pg is reachable exactly once
|
|
|
- * in the snapshot: Either used by a database or listed in a freeDB record.
|
|
|
- */
|
|
|
-typedef struct MDB_page {
|
|
|
-#define mp_pgno mp_p.p_pgno
|
|
|
-#define mp_next mp_p.p_next
|
|
|
- union {
|
|
|
- pgno_t p_pgno; /**< page number */
|
|
|
- struct MDB_page *p_next; /**< for in-memory list of freed pages */
|
|
|
- } mp_p;
|
|
|
- uint16_t mp_pad; /**< key size if this is a LEAF2 page */
|
|
|
-/** @defgroup mdb_page Page Flags
|
|
|
- * @ingroup internal
|
|
|
- * Flags for the page headers.
|
|
|
- * @{
|
|
|
- */
|
|
|
-#define P_BRANCH 0x01 /**< branch page */
|
|
|
-#define P_LEAF 0x02 /**< leaf page */
|
|
|
-#define P_OVERFLOW 0x04 /**< overflow page */
|
|
|
-#define P_META 0x08 /**< meta page */
|
|
|
-#define P_DIRTY 0x10 /**< dirty page, also set for #P_SUBP pages */
|
|
|
-#define P_LEAF2 0x20 /**< for #MDB_DUPFIXED records */
|
|
|
-#define P_SUBP 0x40 /**< for #MDB_DUPSORT sub-pages */
|
|
|
-#define P_LOOSE 0x4000 /**< page was dirtied then freed, can be reused */
|
|
|
-#define P_KEEP 0x8000 /**< leave this page alone during spill */
|
|
|
-/** @} */
|
|
|
- uint16_t mp_flags; /**< @ref mdb_page */
|
|
|
-#define mp_lower mp_pb.pb.pb_lower
|
|
|
-#define mp_upper mp_pb.pb.pb_upper
|
|
|
-#define mp_pages mp_pb.pb_pages
|
|
|
- union {
|
|
|
- struct {
|
|
|
- indx_t pb_lower; /**< lower bound of free space */
|
|
|
- indx_t pb_upper; /**< upper bound of free space */
|
|
|
- } pb;
|
|
|
- uint32_t pb_pages; /**< number of overflow pages */
|
|
|
- } mp_pb;
|
|
|
- indx_t mp_ptrs[1]; /**< dynamic size */
|
|
|
-} MDB_page;
|
|
|
-
|
|
|
- /** Size of the page header, excluding dynamic data at the end */
|
|
|
-#define PAGEHDRSZ ((unsigned) offsetof(MDB_page, mp_ptrs))
|
|
|
-
|
|
|
- /** Address of first usable data byte in a page, after the header */
|
|
|
-#define METADATA(p) ((void *)((char *)(p) + PAGEHDRSZ))
|
|
|
-
|
|
|
- /** ITS#7713, change PAGEBASE to handle 65536 byte pages */
|
|
|
-#define PAGEBASE ((MDB_DEVEL) ? PAGEHDRSZ : 0)
|
|
|
-
|
|
|
- /** Number of nodes on a page */
|
|
|
-#define NUMKEYS(p) (((p)->mp_lower - (PAGEHDRSZ-PAGEBASE)) >> 1)
|
|
|
-
|
|
|
- /** The amount of space remaining in the page */
|
|
|
-#define SIZELEFT(p) (indx_t)((p)->mp_upper - (p)->mp_lower)
|
|
|
-
|
|
|
- /** The percentage of space used in the page, in tenths of a percent. */
|
|
|
-#define PAGEFILL(env, p) (1000L * ((env)->me_psize - PAGEHDRSZ - SIZELEFT(p)) / \
|
|
|
- ((env)->me_psize - PAGEHDRSZ))
|
|
|
- /** The minimum page fill factor, in tenths of a percent.
|
|
|
- * Pages emptier than this are candidates for merging.
|
|
|
- */
|
|
|
-#define FILL_THRESHOLD 250
|
|
|
-
|
|
|
- /** Test if a page is a leaf page */
|
|
|
-#define IS_LEAF(p) F_ISSET((p)->mp_flags, P_LEAF)
|
|
|
- /** Test if a page is a LEAF2 page */
|
|
|
-#define IS_LEAF2(p) F_ISSET((p)->mp_flags, P_LEAF2)
|
|
|
- /** Test if a page is a branch page */
|
|
|
-#define IS_BRANCH(p) F_ISSET((p)->mp_flags, P_BRANCH)
|
|
|
- /** Test if a page is an overflow page */
|
|
|
-#define IS_OVERFLOW(p) F_ISSET((p)->mp_flags, P_OVERFLOW)
|
|
|
- /** Test if a page is a sub page */
|
|
|
-#define IS_SUBP(p) F_ISSET((p)->mp_flags, P_SUBP)
|
|
|
-
|
|
|
- /** The number of overflow pages needed to store the given size. */
|
|
|
-#define OVPAGES(size, psize) ((PAGEHDRSZ-1 + (size)) / (psize) + 1)
|
|
|
-
|
|
|
- /** Link in #MDB_txn.%mt_loose_pgs list.
|
|
|
- * Kept outside the page header, which is needed when reusing the page.
|
|
|
- */
|
|
|
-#define NEXT_LOOSE_PAGE(p) (*(MDB_page **)((p) + 2))
|
|
|
-
|
|
|
- /** Header for a single key/data pair within a page.
|
|
|
- * Used in pages of type #P_BRANCH and #P_LEAF without #P_LEAF2.
|
|
|
- * We guarantee 2-byte alignment for 'MDB_node's.
|
|
|
- *
|
|
|
- * #mn_lo and #mn_hi are used for data size on leaf nodes, and for child
|
|
|
- * pgno on branch nodes. On 64 bit platforms, #mn_flags is also used
|
|
|
- * for pgno. (Branch nodes have no flags). Lo and hi are in host byte
|
|
|
- * order in case some accesses can be optimized to 32-bit word access.
|
|
|
- *
|
|
|
- * Leaf node flags describe node contents. #F_BIGDATA says the node's
|
|
|
- * data part is the page number of an overflow page with actual data.
|
|
|
- * #F_DUPDATA and #F_SUBDATA can be combined giving duplicate data in
|
|
|
- * a sub-page/sub-database, and named databases (just #F_SUBDATA).
|
|
|
- */
|
|
|
-typedef struct MDB_node {
|
|
|
- /** part of data size or pgno
|
|
|
- * @{ */
|
|
|
-#if BYTE_ORDER == LITTLE_ENDIAN
|
|
|
- unsigned short mn_lo, mn_hi;
|
|
|
-#else
|
|
|
- unsigned short mn_hi, mn_lo;
|
|
|
-#endif
|
|
|
- /** @} */
|
|
|
-/** @defgroup mdb_node Node Flags
|
|
|
- * @ingroup internal
|
|
|
- * Flags for node headers.
|
|
|
- * @{
|
|
|
- */
|
|
|
-#define F_BIGDATA 0x01 /**< data put on overflow page */
|
|
|
-#define F_SUBDATA 0x02 /**< data is a sub-database */
|
|
|
-#define F_DUPDATA 0x04 /**< data has duplicates */
|
|
|
-
|
|
|
-/** valid flags for #mdb_node_add() */
|
|
|
-#define NODE_ADD_FLAGS (F_DUPDATA|F_SUBDATA|MDB_RESERVE|MDB_APPEND)
|
|
|
-
|
|
|
-/** @} */
|
|
|
- unsigned short mn_flags; /**< @ref mdb_node */
|
|
|
- unsigned short mn_ksize; /**< key size */
|
|
|
- char mn_data[1]; /**< key and data are appended here */
|
|
|
-} MDB_node;
|
|
|
-
|
|
|
- /** Size of the node header, excluding dynamic data at the end */
|
|
|
-#define NODESIZE offsetof(MDB_node, mn_data)
|
|
|
-
|
|
|
- /** Bit position of top word in page number, for shifting mn_flags */
|
|
|
-#define PGNO_TOPWORD ((pgno_t)-1 > 0xffffffffu ? 32 : 0)
|
|
|
-
|
|
|
- /** Size of a node in a branch page with a given key.
|
|
|
- * This is just the node header plus the key, there is no data.
|
|
|
- */
|
|
|
-#define INDXSIZE(k) (NODESIZE + ((k) == NULL ? 0 : (k)->mv_size))
|
|
|
-
|
|
|
- /** Size of a node in a leaf page with a given key and data.
|
|
|
- * This is node header plus key plus data size.
|
|
|
- */
|
|
|
-#define LEAFSIZE(k, d) (NODESIZE + (k)->mv_size + (d)->mv_size)
|
|
|
-
|
|
|
- /** Address of node \b i in page \b p */
|
|
|
-#define NODEPTR(p, i) ((MDB_node *)((char *)(p) + (p)->mp_ptrs[i] + PAGEBASE))
|
|
|
-
|
|
|
- /** Address of the key for the node */
|
|
|
-#define NODEKEY(node) (void *)((node)->mn_data)
|
|
|
-
|
|
|
- /** Address of the data for a node */
|
|
|
-#define NODEDATA(node) (void *)((char *)(node)->mn_data + (node)->mn_ksize)
|
|
|
-
|
|
|
- /** Get the page number pointed to by a branch node */
|
|
|
-#define NODEPGNO(node) \
|
|
|
- ((node)->mn_lo | ((pgno_t) (node)->mn_hi << 16) | \
|
|
|
- (PGNO_TOPWORD ? ((pgno_t) (node)->mn_flags << PGNO_TOPWORD) : 0))
|
|
|
- /** Set the page number in a branch node */
|
|
|
-#define SETPGNO(node,pgno) do { \
|
|
|
- (node)->mn_lo = (pgno) & 0xffff; (node)->mn_hi = (pgno) >> 16; \
|
|
|
- if (PGNO_TOPWORD) (node)->mn_flags = (pgno) >> PGNO_TOPWORD; } while(0)
|
|
|
-
|
|
|
- /** Get the size of the data in a leaf node */
|
|
|
-#define NODEDSZ(node) ((node)->mn_lo | ((unsigned)(node)->mn_hi << 16))
|
|
|
- /** Set the size of the data for a leaf node */
|
|
|
-#define SETDSZ(node,size) do { \
|
|
|
- (node)->mn_lo = (size) & 0xffff; (node)->mn_hi = (size) >> 16;} while(0)
|
|
|
- /** The size of a key in a node */
|
|
|
-#define NODEKSZ(node) ((node)->mn_ksize)
|
|
|
-
|
|
|
- /** Copy a page number from src to dst */
|
|
|
-#ifdef MISALIGNED_OK
|
|
|
-#define COPY_PGNO(dst,src) dst = src
|
|
|
-#else
|
|
|
-#if SIZE_MAX > 4294967295UL
|
|
|
-#define COPY_PGNO(dst,src) do { \
|
|
|
- unsigned short *s, *d; \
|
|
|
- s = (unsigned short *)&(src); \
|
|
|
- d = (unsigned short *)&(dst); \
|
|
|
- *d++ = *s++; \
|
|
|
- *d++ = *s++; \
|
|
|
- *d++ = *s++; \
|
|
|
- *d = *s; \
|
|
|
-} while (0)
|
|
|
-#else
|
|
|
-#define COPY_PGNO(dst,src) do { \
|
|
|
- unsigned short *s, *d; \
|
|
|
- s = (unsigned short *)&(src); \
|
|
|
- d = (unsigned short *)&(dst); \
|
|
|
- *d++ = *s++; \
|
|
|
- *d = *s; \
|
|
|
-} while (0)
|
|
|
-#endif
|
|
|
-#endif
|
|
|
- /** The address of a key in a LEAF2 page.
|
|
|
- * LEAF2 pages are used for #MDB_DUPFIXED sorted-duplicate sub-DBs.
|
|
|
- * There are no node headers, keys are stored contiguously.
|
|
|
- */
|
|
|
-#define LEAF2KEY(p, i, ks) ((char *)(p) + PAGEHDRSZ + ((i)*(ks)))
|
|
|
-
|
|
|
- /** Set the \b node's key into \b keyptr, if requested. */
|
|
|
-#define MDB_GET_KEY(node, keyptr) { if ((keyptr) != NULL) { \
|
|
|
- (keyptr)->mv_size = NODEKSZ(node); (keyptr)->mv_data = NODEKEY(node); } }
|
|
|
-
|
|
|
- /** Set the \b node's key into \b key. */
|
|
|
-#define MDB_GET_KEY2(node, key) { key.mv_size = NODEKSZ(node); key.mv_data = NODEKEY(node); }
|
|
|
-
|
|
|
- /** Information about a single database in the environment. */
|
|
|
-typedef struct MDB_db {
|
|
|
- uint32_t md_pad; /**< also ksize for LEAF2 pages */
|
|
|
- uint16_t md_flags; /**< @ref mdb_dbi_open */
|
|
|
- uint16_t md_depth; /**< depth of this tree */
|
|
|
- pgno_t md_branch_pages; /**< number of internal pages */
|
|
|
- pgno_t md_leaf_pages; /**< number of leaf pages */
|
|
|
- pgno_t md_overflow_pages; /**< number of overflow pages */
|
|
|
- size_t md_entries; /**< number of data items */
|
|
|
- pgno_t md_root; /**< the root page of this tree */
|
|
|
-} MDB_db;
|
|
|
-
|
|
|
-#define MDB_VALID 0x8000 /**< DB handle is valid, for me_dbflags */
|
|
|
-#define PERSISTENT_FLAGS (0xffff & ~(MDB_VALID))
|
|
|
- /** #mdb_dbi_open() flags */
|
|
|
-#define VALID_FLAGS (MDB_REVERSEKEY|MDB_DUPSORT|MDB_INTEGERKEY|MDB_DUPFIXED|\
|
|
|
- MDB_INTEGERDUP|MDB_REVERSEDUP|MDB_CREATE)
|
|
|
-
|
|
|
- /** Handle for the DB used to track free pages. */
|
|
|
-#define FREE_DBI 0
|
|
|
- /** Handle for the default DB. */
|
|
|
-#define MAIN_DBI 1
|
|
|
- /** Number of DBs in metapage (free and main) - also hardcoded elsewhere */
|
|
|
-#define CORE_DBS 2
|
|
|
-
|
|
|
- /** Number of meta pages - also hardcoded elsewhere */
|
|
|
-#define NUM_METAS 2
|
|
|
-
|
|
|
- /** Meta page content.
|
|
|
- * A meta page is the start point for accessing a database snapshot.
|
|
|
- * Pages 0-1 are meta pages. Transaction N writes meta page #(N % 2).
|
|
|
- */
|
|
|
-typedef struct MDB_meta {
|
|
|
- /** Stamp identifying this as an LMDB file. It must be set
|
|
|
- * to #MDB_MAGIC. */
|
|
|
- uint32_t mm_magic;
|
|
|
- /** Version number of this file. Must be set to #MDB_DATA_VERSION. */
|
|
|
- uint32_t mm_version;
|
|
|
- void *mm_address; /**< address for fixed mapping */
|
|
|
- size_t mm_mapsize; /**< size of mmap region */
|
|
|
- MDB_db mm_dbs[CORE_DBS]; /**< first is free space, 2nd is main db */
|
|
|
- /** The size of pages used in this DB */
|
|
|
-#define mm_psize mm_dbs[FREE_DBI].md_pad
|
|
|
- /** Any persistent environment flags. @ref mdb_env */
|
|
|
-#define mm_flags mm_dbs[FREE_DBI].md_flags
|
|
|
- /** Last used page in the datafile.
|
|
|
- * Actually the file may be shorter if the freeDB lists the final pages.
|
|
|
- */
|
|
|
- pgno_t mm_last_pg;
|
|
|
- volatile txnid_t mm_txnid; /**< txnid that committed this page */
|
|
|
-} MDB_meta;
|
|
|
-
|
|
|
- /** Buffer for a stack-allocated meta page.
|
|
|
- * The members define size and alignment, and silence type
|
|
|
- * aliasing warnings. They are not used directly; that could
|
|
|
- * mean incorrectly using several union members in parallel.
|
|
|
- */
|
|
|
-typedef union MDB_metabuf {
|
|
|
- MDB_page mb_page;
|
|
|
- struct {
|
|
|
- char mm_pad[PAGEHDRSZ];
|
|
|
- MDB_meta mm_meta;
|
|
|
- } mb_metabuf;
|
|
|
-} MDB_metabuf;
|
|
|
-
|
|
|
- /** Auxiliary DB info.
|
|
|
- * The information here is mostly static/read-only. There is
|
|
|
- * only a single copy of this record in the environment.
|
|
|
- */
|
|
|
-typedef struct MDB_dbx {
|
|
|
- MDB_val md_name; /**< name of the database */
|
|
|
- MDB_cmp_func *md_cmp; /**< function for comparing keys */
|
|
|
- MDB_cmp_func *md_dcmp; /**< function for comparing data items */
|
|
|
- MDB_rel_func *md_rel; /**< user relocate function */
|
|
|
- void *md_relctx; /**< user-provided context for md_rel */
|
|
|
-} MDB_dbx;
|
|
|
-
|
|
|
- /** A database transaction.
|
|
|
- * Every operation requires a transaction handle.
|
|
|
- */
|
|
|
-struct MDB_txn {
|
|
|
- MDB_txn *mt_parent; /**< parent of a nested txn */
|
|
|
- /** Nested txn under this txn, set together with flag #MDB_TXN_HAS_CHILD */
|
|
|
- MDB_txn *mt_child;
|
|
|
- pgno_t mt_next_pgno; /**< next unallocated page */
|
|
|
- /** The ID of this transaction. IDs are integers incrementing from 1.
|
|
|
- * Only committed write transactions increment the ID. If a transaction
|
|
|
- * aborts, the ID may be re-used by the next writer.
|
|
|
- */
|
|
|
- txnid_t mt_txnid;
|
|
|
- MDB_env *mt_env; /**< the DB environment */
|
|
|
- /** The list of pages that became unused during this transaction.
|
|
|
- */
|
|
|
- MDB_IDL mt_free_pgs;
|
|
|
- /** The list of loose pages that became unused and may be reused
|
|
|
- * in this transaction, linked through #NEXT_LOOSE_PAGE(page).
|
|
|
- */
|
|
|
- MDB_page *mt_loose_pgs;
|
|
|
- /** Number of loose pages (#mt_loose_pgs) */
|
|
|
- int mt_loose_count;
|
|
|
- /** The sorted list of dirty pages we temporarily wrote to disk
|
|
|
- * because the dirty list was full. page numbers in here are
|
|
|
- * shifted left by 1, deleted slots have the LSB set.
|
|
|
- */
|
|
|
- MDB_IDL mt_spill_pgs;
|
|
|
- union {
|
|
|
- /** For write txns: Modified pages. Sorted when not MDB_WRITEMAP. */
|
|
|
- MDB_ID2L dirty_list;
|
|
|
- /** For read txns: This thread/txn's reader table slot, or NULL. */
|
|
|
- MDB_reader *reader;
|
|
|
- } mt_u;
|
|
|
- /** Array of records for each DB known in the environment. */
|
|
|
- MDB_dbx *mt_dbxs;
|
|
|
- /** Array of MDB_db records for each known DB */
|
|
|
- MDB_db *mt_dbs;
|
|
|
- /** Array of sequence numbers for each DB handle */
|
|
|
- unsigned int *mt_dbiseqs;
|
|
|
-/** @defgroup mt_dbflag Transaction DB Flags
|
|
|
- * @ingroup internal
|
|
|
- * @{
|
|
|
- */
|
|
|
-#define DB_DIRTY 0x01 /**< DB was written in this txn */
|
|
|
-#define DB_STALE 0x02 /**< Named-DB record is older than txnID */
|
|
|
-#define DB_NEW 0x04 /**< Named-DB handle opened in this txn */
|
|
|
-#define DB_VALID 0x08 /**< DB handle is valid, see also #MDB_VALID */
|
|
|
-#define DB_USRVALID 0x10 /**< As #DB_VALID, but not set for #FREE_DBI */
|
|
|
-#define DB_DUPDATA 0x20 /**< DB is #MDB_DUPSORT data */
|
|
|
-/** @} */
|
|
|
- /** In write txns, array of cursors for each DB */
|
|
|
- MDB_cursor **mt_cursors;
|
|
|
- /** Array of flags for each DB */
|
|
|
- unsigned char *mt_dbflags;
|
|
|
- /** Number of DB records in use, or 0 when the txn is finished.
|
|
|
- * This number only ever increments until the txn finishes; we
|
|
|
- * don't decrement it when individual DB handles are closed.
|
|
|
- */
|
|
|
- MDB_dbi mt_numdbs;
|
|
|
-
|
|
|
-/** @defgroup mdb_txn Transaction Flags
|
|
|
- * @ingroup internal
|
|
|
- * @{
|
|
|
- */
|
|
|
- /** #mdb_txn_begin() flags */
|
|
|
-#define MDB_TXN_BEGIN_FLAGS MDB_RDONLY
|
|
|
-#define MDB_TXN_RDONLY MDB_RDONLY /**< read-only transaction */
|
|
|
- /* internal txn flags */
|
|
|
-#define MDB_TXN_WRITEMAP MDB_WRITEMAP /**< copy of #MDB_env flag in writers */
|
|
|
-#define MDB_TXN_FINISHED 0x01 /**< txn is finished or never began */
|
|
|
-#define MDB_TXN_ERROR 0x02 /**< txn is unusable after an error */
|
|
|
-#define MDB_TXN_DIRTY 0x04 /**< must write, even if dirty list is empty */
|
|
|
-#define MDB_TXN_SPILLS 0x08 /**< txn or a parent has spilled pages */
|
|
|
-#define MDB_TXN_HAS_CHILD 0x10 /**< txn has an #MDB_txn.%mt_child */
|
|
|
- /** most operations on the txn are currently illegal */
|
|
|
-#define MDB_TXN_BLOCKED (MDB_TXN_FINISHED|MDB_TXN_ERROR|MDB_TXN_HAS_CHILD)
|
|
|
-/** @} */
|
|
|
- unsigned int mt_flags; /**< @ref mdb_txn */
|
|
|
- /** #dirty_list room: Array size - \#dirty pages visible to this txn.
|
|
|
- * Includes ancestor txns' dirty pages not hidden by other txns'
|
|
|
- * dirty/spilled pages. Thus commit(nested txn) has room to merge
|
|
|
- * dirty_list into mt_parent after freeing hidden mt_parent pages.
|
|
|
- */
|
|
|
- unsigned int mt_dirty_room;
|
|
|
-};
|
|
|
-
|
|
|
-/** Enough space for 2^32 nodes with minimum of 2 keys per node. I.e., plenty.
|
|
|
- * At 4 keys per node, enough for 2^64 nodes, so there's probably no need to
|
|
|
- * raise this on a 64 bit machine.
|
|
|
- */
|
|
|
-#define CURSOR_STACK 32
|
|
|
-
|
|
|
-struct MDB_xcursor;
|
|
|
-
|
|
|
- /** Cursors are used for all DB operations.
|
|
|
- * A cursor holds a path of (page pointer, key index) from the DB
|
|
|
- * root to a position in the DB, plus other state. #MDB_DUPSORT
|
|
|
- * cursors include an xcursor to the current data item. Write txns
|
|
|
- * track their cursors and keep them up to date when data moves.
|
|
|
- * Exception: An xcursor's pointer to a #P_SUBP page can be stale.
|
|
|
- * (A node with #F_DUPDATA but no #F_SUBDATA contains a subpage).
|
|
|
- */
|
|
|
-struct MDB_cursor {
|
|
|
- /** Next cursor on this DB in this txn */
|
|
|
- MDB_cursor *mc_next;
|
|
|
- /** Backup of the original cursor if this cursor is a shadow */
|
|
|
- MDB_cursor *mc_backup;
|
|
|
- /** Context used for databases with #MDB_DUPSORT, otherwise NULL */
|
|
|
- struct MDB_xcursor *mc_xcursor;
|
|
|
- /** The transaction that owns this cursor */
|
|
|
- MDB_txn *mc_txn;
|
|
|
- /** The database handle this cursor operates on */
|
|
|
- MDB_dbi mc_dbi;
|
|
|
- /** The database record for this cursor */
|
|
|
- MDB_db *mc_db;
|
|
|
- /** The database auxiliary record for this cursor */
|
|
|
- MDB_dbx *mc_dbx;
|
|
|
- /** The @ref mt_dbflag for this database */
|
|
|
- unsigned char *mc_dbflag;
|
|
|
- unsigned short mc_snum; /**< number of pushed pages */
|
|
|
- unsigned short mc_top; /**< index of top page, normally mc_snum-1 */
|
|
|
-/** @defgroup mdb_cursor Cursor Flags
|
|
|
- * @ingroup internal
|
|
|
- * Cursor state flags.
|
|
|
- * @{
|
|
|
- */
|
|
|
-#define C_INITIALIZED 0x01 /**< cursor has been initialized and is valid */
|
|
|
-#define C_EOF 0x02 /**< No more data */
|
|
|
-#define C_SUB 0x04 /**< Cursor is a sub-cursor */
|
|
|
-#define C_DEL 0x08 /**< last op was a cursor_del */
|
|
|
-#define C_UNTRACK 0x40 /**< Un-track cursor when closing */
|
|
|
-/** @} */
|
|
|
- unsigned int mc_flags; /**< @ref mdb_cursor */
|
|
|
- MDB_page *mc_pg[CURSOR_STACK]; /**< stack of pushed pages */
|
|
|
- indx_t mc_ki[CURSOR_STACK]; /**< stack of page indices */
|
|
|
-};
|
|
|
-
|
|
|
- /** Context for sorted-dup records.
|
|
|
- * We could have gone to a fully recursive design, with arbitrarily
|
|
|
- * deep nesting of sub-databases. But for now we only handle these
|
|
|
- * levels - main DB, optional sub-DB, sorted-duplicate DB.
|
|
|
- */
|
|
|
-typedef struct MDB_xcursor {
|
|
|
- /** A sub-cursor for traversing the Dup DB */
|
|
|
- MDB_cursor mx_cursor;
|
|
|
- /** The database record for this Dup DB */
|
|
|
- MDB_db mx_db;
|
|
|
- /** The auxiliary DB record for this Dup DB */
|
|
|
- MDB_dbx mx_dbx;
|
|
|
- /** The @ref mt_dbflag for this Dup DB */
|
|
|
- unsigned char mx_dbflag;
|
|
|
-} MDB_xcursor;
|
|
|
-
|
|
|
- /** Check if there is an inited xcursor */
|
|
|
-#define XCURSOR_INITED(mc) \
|
|
|
- ((mc)->mc_xcursor && ((mc)->mc_xcursor->mx_cursor.mc_flags & C_INITIALIZED))
|
|
|
-
|
|
|
- /** Update the xcursor's sub-page pointer, if any, in \b mc. Needed
|
|
|
- * when the node which contains the sub-page may have moved. Called
|
|
|
- * with leaf page \b mp = mc->mc_pg[\b top].
|
|
|
- */
|
|
|
-#define XCURSOR_REFRESH(mc, top, mp) do { \
|
|
|
- MDB_page *xr_pg = (mp); \
|
|
|
- MDB_node *xr_node; \
|
|
|
- if (!XCURSOR_INITED(mc) || (mc)->mc_ki[top] >= NUMKEYS(xr_pg)) break; \
|
|
|
- xr_node = NODEPTR(xr_pg, (mc)->mc_ki[top]); \
|
|
|
- if ((xr_node->mn_flags & (F_DUPDATA|F_SUBDATA)) == F_DUPDATA) \
|
|
|
- (mc)->mc_xcursor->mx_cursor.mc_pg[0] = NODEDATA(xr_node); \
|
|
|
-} while (0)
|
|
|
-
|
|
|
- /** State of FreeDB old pages, stored in the MDB_env */
|
|
|
-typedef struct MDB_pgstate {
|
|
|
- pgno_t *mf_pghead; /**< Reclaimed freeDB pages, or NULL before use */
|
|
|
- txnid_t mf_pglast; /**< ID of last used record, or 0 if !mf_pghead */
|
|
|
-} MDB_pgstate;
|
|
|
-
|
|
|
- /** The database environment. */
|
|
|
-struct MDB_env {
|
|
|
- HANDLE me_fd; /**< The main data file */
|
|
|
- HANDLE me_lfd; /**< The lock file */
|
|
|
- HANDLE me_mfd; /**< For writing and syncing the meta pages */
|
|
|
- /** Failed to update the meta page. Probably an I/O error. */
|
|
|
-#define MDB_FATAL_ERROR 0x80000000U
|
|
|
- /** Some fields are initialized. */
|
|
|
-#define MDB_ENV_ACTIVE 0x20000000U
|
|
|
- /** me_txkey is set */
|
|
|
-#define MDB_ENV_TXKEY 0x10000000U
|
|
|
- /** fdatasync is unreliable */
|
|
|
-#define MDB_FSYNCONLY 0x08000000U
|
|
|
- uint32_t me_flags; /**< @ref mdb_env */
|
|
|
- unsigned int me_psize; /**< DB page size, inited from me_os_psize */
|
|
|
- unsigned int me_os_psize; /**< OS page size, from #GET_PAGESIZE */
|
|
|
- unsigned int me_maxreaders; /**< size of the reader table */
|
|
|
- /** Max #MDB_txninfo.%mti_numreaders of interest to #mdb_env_close() */
|
|
|
- volatile int me_close_readers;
|
|
|
- MDB_dbi me_numdbs; /**< number of DBs opened */
|
|
|
- MDB_dbi me_maxdbs; /**< size of the DB table */
|
|
|
- MDB_PID_T me_pid; /**< process ID of this env */
|
|
|
- char *me_path; /**< path to the DB files */
|
|
|
- char *me_map; /**< the memory map of the data file */
|
|
|
- MDB_txninfo *me_txns; /**< the memory map of the lock file or NULL */
|
|
|
- MDB_meta *me_metas[NUM_METAS]; /**< pointers to the two meta pages */
|
|
|
- void *me_pbuf; /**< scratch area for DUPSORT put() */
|
|
|
- MDB_txn *me_txn; /**< current write transaction */
|
|
|
- MDB_txn *me_txn0; /**< prealloc'd write transaction */
|
|
|
- size_t me_mapsize; /**< size of the data memory map */
|
|
|
- off_t me_size; /**< current file size */
|
|
|
- pgno_t me_maxpg; /**< me_mapsize / me_psize */
|
|
|
- MDB_dbx *me_dbxs; /**< array of static DB info */
|
|
|
- uint16_t *me_dbflags; /**< array of flags from MDB_db.md_flags */
|
|
|
- unsigned int *me_dbiseqs; /**< array of dbi sequence numbers */
|
|
|
- pthread_key_t me_txkey; /**< thread-key for readers */
|
|
|
- txnid_t me_pgoldest; /**< ID of oldest reader last time we looked */
|
|
|
- MDB_pgstate me_pgstate; /**< state of old pages from freeDB */
|
|
|
-# define me_pglast me_pgstate.mf_pglast
|
|
|
-# define me_pghead me_pgstate.mf_pghead
|
|
|
- MDB_page *me_dpages; /**< list of malloc'd blocks for re-use */
|
|
|
- /** IDL of pages that became unused in a write txn */
|
|
|
- MDB_IDL me_free_pgs;
|
|
|
- /** ID2L of pages written during a write txn. Length MDB_IDL_UM_SIZE. */
|
|
|
- MDB_ID2L me_dirty_list;
|
|
|
- /** Max number of freelist items that can fit in a single overflow page */
|
|
|
- int me_maxfree_1pg;
|
|
|
- /** Max size of a node on a page */
|
|
|
- unsigned int me_nodemax;
|
|
|
-#if !(MDB_MAXKEYSIZE)
|
|
|
- unsigned int me_maxkey; /**< max size of a key */
|
|
|
-#endif
|
|
|
- int me_live_reader; /**< have liveness lock in reader table */
|
|
|
-#ifdef _WIN32
|
|
|
- int me_pidquery; /**< Used in OpenProcess */
|
|
|
-#endif
|
|
|
-#ifdef MDB_USE_POSIX_MUTEX /* Posix mutexes reside in shared mem */
|
|
|
-# define me_rmutex me_txns->mti_rmutex /**< Shared reader lock */
|
|
|
-# define me_wmutex me_txns->mti_wmutex /**< Shared writer lock */
|
|
|
-#else
|
|
|
- mdb_mutex_t me_rmutex;
|
|
|
- mdb_mutex_t me_wmutex;
|
|
|
-#endif
|
|
|
- void *me_userctx; /**< User-settable context */
|
|
|
- MDB_assert_func *me_assert_func; /**< Callback for assertion failures */
|
|
|
-};
|
|
|
-
|
|
|
- /** Nested transaction */
|
|
|
-typedef struct MDB_ntxn {
|
|
|
- MDB_txn mnt_txn; /**< the transaction */
|
|
|
- MDB_pgstate mnt_pgstate; /**< parent transaction's saved freestate */
|
|
|
-} MDB_ntxn;
|
|
|
-
|
|
|
- /** max number of pages to commit in one writev() call */
|
|
|
-#define MDB_COMMIT_PAGES 64
|
|
|
-#if defined(IOV_MAX) && IOV_MAX < MDB_COMMIT_PAGES
|
|
|
-#undef MDB_COMMIT_PAGES
|
|
|
-#define MDB_COMMIT_PAGES IOV_MAX
|
|
|
-#endif
|
|
|
-
|
|
|
- /** max bytes to write in one call */
|
|
|
-#define MAX_WRITE (0x40000000U >> (sizeof(ssize_t) == 4))
|
|
|
-
|
|
|
- /** Check \b txn and \b dbi arguments to a function */
|
|
|
-#define TXN_DBI_EXIST(txn, dbi, validity) \
|
|
|
- ((txn) && (dbi)<(txn)->mt_numdbs && ((txn)->mt_dbflags[dbi] & (validity)))
|
|
|
-
|
|
|
- /** Check for misused \b dbi handles */
|
|
|
-#define TXN_DBI_CHANGED(txn, dbi) \
|
|
|
- ((txn)->mt_dbiseqs[dbi] != (txn)->mt_env->me_dbiseqs[dbi])
|
|
|
-
|
|
|
-static int mdb_page_alloc(MDB_cursor *mc, int num, MDB_page **mp);
|
|
|
-static int mdb_page_new(MDB_cursor *mc, uint32_t flags, int num, MDB_page **mp);
|
|
|
-static int mdb_page_touch(MDB_cursor *mc);
|
|
|
-
|
|
|
-#define MDB_END_NAMES {"committed", "empty-commit", "abort", "reset", \
|
|
|
- "reset-tmp", "fail-begin", "fail-beginchild"}
|
|
|
-enum {
|
|
|
- /* mdb_txn_end operation number, for logging */
|
|
|
- MDB_END_COMMITTED, MDB_END_EMPTY_COMMIT, MDB_END_ABORT, MDB_END_RESET,
|
|
|
- MDB_END_RESET_TMP, MDB_END_FAIL_BEGIN, MDB_END_FAIL_BEGINCHILD
|
|
|
-};
|
|
|
-#define MDB_END_OPMASK 0x0F /**< mask for #mdb_txn_end() operation number */
|
|
|
-#define MDB_END_UPDATE 0x10 /**< update env state (DBIs) */
|
|
|
-#define MDB_END_FREE 0x20 /**< free txn unless it is #MDB_env.%me_txn0 */
|
|
|
-#define MDB_END_SLOT MDB_NOTLS /**< release any reader slot if #MDB_NOTLS */
|
|
|
-static void mdb_txn_end(MDB_txn *txn, unsigned mode);
|
|
|
-
|
|
|
-static int mdb_page_get(MDB_cursor *mc, pgno_t pgno, MDB_page **mp, int *lvl);
|
|
|
-static int mdb_page_search_root(MDB_cursor *mc,
|
|
|
- MDB_val *key, int modify);
|
|
|
-#define MDB_PS_MODIFY 1
|
|
|
-#define MDB_PS_ROOTONLY 2
|
|
|
-#define MDB_PS_FIRST 4
|
|
|
-#define MDB_PS_LAST 8
|
|
|
-static int mdb_page_search(MDB_cursor *mc,
|
|
|
- MDB_val *key, int flags);
|
|
|
-static int mdb_page_merge(MDB_cursor *csrc, MDB_cursor *cdst);
|
|
|
-
|
|
|
-#define MDB_SPLIT_REPLACE MDB_APPENDDUP /**< newkey is not new */
|
|
|
-static int mdb_page_split(MDB_cursor *mc, MDB_val *newkey, MDB_val *newdata,
|
|
|
- pgno_t newpgno, unsigned int nflags);
|
|
|
-
|
|
|
-static int mdb_env_read_header(MDB_env *env, MDB_meta *meta);
|
|
|
-static MDB_meta *mdb_env_pick_meta(const MDB_env *env);
|
|
|
-static int mdb_env_write_meta(MDB_txn *txn);
|
|
|
-#ifdef MDB_USE_POSIX_MUTEX /* Drop unused excl arg */
|
|
|
-# define mdb_env_close0(env, excl) mdb_env_close1(env)
|
|
|
-#endif
|
|
|
-static void mdb_env_close0(MDB_env *env, int excl);
|
|
|
-
|
|
|
-static MDB_node *mdb_node_search(MDB_cursor *mc, MDB_val *key, int *exactp);
|
|
|
-static int mdb_node_add(MDB_cursor *mc, indx_t indx,
|
|
|
- MDB_val *key, MDB_val *data, pgno_t pgno, unsigned int flags);
|
|
|
-static void mdb_node_del(MDB_cursor *mc, int ksize);
|
|
|
-static void mdb_node_shrink(MDB_page *mp, indx_t indx);
|
|
|
-static int mdb_node_move(MDB_cursor *csrc, MDB_cursor *cdst, int fromleft);
|
|
|
-static int mdb_node_read(MDB_cursor *mc, MDB_node *leaf, MDB_val *data);
|
|
|
-static size_t mdb_leaf_size(MDB_env *env, MDB_val *key, MDB_val *data);
|
|
|
-static size_t mdb_branch_size(MDB_env *env, MDB_val *key);
|
|
|
-
|
|
|
-static int mdb_rebalance(MDB_cursor *mc);
|
|
|
-static int mdb_update_key(MDB_cursor *mc, MDB_val *key);
|
|
|
-
|
|
|
-static void mdb_cursor_pop(MDB_cursor *mc);
|
|
|
-static int mdb_cursor_push(MDB_cursor *mc, MDB_page *mp);
|
|
|
-
|
|
|
-static int mdb_cursor_del0(MDB_cursor *mc);
|
|
|
-static int mdb_del0(MDB_txn *txn, MDB_dbi dbi, MDB_val *key, MDB_val *data, unsigned flags);
|
|
|
-static int mdb_cursor_sibling(MDB_cursor *mc, int move_right);
|
|
|
-static int mdb_cursor_next(MDB_cursor *mc, MDB_val *key, MDB_val *data, MDB_cursor_op op);
|
|
|
-static int mdb_cursor_prev(MDB_cursor *mc, MDB_val *key, MDB_val *data, MDB_cursor_op op);
|
|
|
-static int mdb_cursor_set(MDB_cursor *mc, MDB_val *key, MDB_val *data, MDB_cursor_op op,
|
|
|
- int *exactp);
|
|
|
-static int mdb_cursor_first(MDB_cursor *mc, MDB_val *key, MDB_val *data);
|
|
|
-static int mdb_cursor_last(MDB_cursor *mc, MDB_val *key, MDB_val *data);
|
|
|
-
|
|
|
-static void mdb_cursor_init(MDB_cursor *mc, MDB_txn *txn, MDB_dbi dbi, MDB_xcursor *mx);
|
|
|
-static void mdb_xcursor_init0(MDB_cursor *mc);
|
|
|
-static void mdb_xcursor_init1(MDB_cursor *mc, MDB_node *node);
|
|
|
-static void mdb_xcursor_init2(MDB_cursor *mc, MDB_xcursor *src_mx, int force);
|
|
|
-
|
|
|
-static int mdb_drop0(MDB_cursor *mc, int subs);
|
|
|
-static void mdb_default_cmp(MDB_txn *txn, MDB_dbi dbi);
|
|
|
-static int mdb_reader_check0(MDB_env *env, int rlocked, int *dead);
|
|
|
-
|
|
|
-/** @cond */
|
|
|
-static MDB_cmp_func mdb_cmp_memn, mdb_cmp_memnr, mdb_cmp_int, mdb_cmp_cint, mdb_cmp_long;
|
|
|
-/** @endcond */
|
|
|
-
|
|
|
-/** Compare two items pointing at size_t's of unknown alignment. */
|
|
|
-#ifdef MISALIGNED_OK
|
|
|
-# define mdb_cmp_clong mdb_cmp_long
|
|
|
-#else
|
|
|
-# define mdb_cmp_clong mdb_cmp_cint
|
|
|
-#endif
|
|
|
-
|
|
|
-#ifdef _WIN32
|
|
|
-static SECURITY_DESCRIPTOR mdb_null_sd;
|
|
|
-static SECURITY_ATTRIBUTES mdb_all_sa;
|
|
|
-static int mdb_sec_inited;
|
|
|
-
|
|
|
-struct MDB_name;
|
|
|
-static int utf8_to_utf16(const char *src, struct MDB_name *dst, int xtra);
|
|
|
-#endif
|
|
|
-
|
|
|
-/** Return the library version info. */
|
|
|
-char * ESECT
|
|
|
-mdb_version(int *major, int *minor, int *patch)
|
|
|
-{
|
|
|
- if (major) *major = MDB_VERSION_MAJOR;
|
|
|
- if (minor) *minor = MDB_VERSION_MINOR;
|
|
|
- if (patch) *patch = MDB_VERSION_PATCH;
|
|
|
- return MDB_VERSION_STRING;
|
|
|
-}
|
|
|
-
|
|
|
-/** Table of descriptions for LMDB @ref errors */
|
|
|
-static char *const mdb_errstr[] = {
|
|
|
- "MDB_KEYEXIST: Key/data pair already exists",
|
|
|
- "MDB_NOTFOUND: No matching key/data pair found",
|
|
|
- "MDB_PAGE_NOTFOUND: Requested page not found",
|
|
|
- "MDB_CORRUPTED: Located page was wrong type",
|
|
|
- "MDB_PANIC: Update of meta page failed or environment had fatal error",
|
|
|
- "MDB_VERSION_MISMATCH: Database environment version mismatch",
|
|
|
- "MDB_INVALID: File is not an LMDB file",
|
|
|
- "MDB_MAP_FULL: Environment mapsize limit reached",
|
|
|
- "MDB_DBS_FULL: Environment maxdbs limit reached",
|
|
|
- "MDB_READERS_FULL: Environment maxreaders limit reached",
|
|
|
- "MDB_TLS_FULL: Thread-local storage keys full - too many environments open",
|
|
|
- "MDB_TXN_FULL: Transaction has too many dirty pages - transaction too big",
|
|
|
- "MDB_CURSOR_FULL: Internal error - cursor stack limit reached",
|
|
|
- "MDB_PAGE_FULL: Internal error - page has no more space",
|
|
|
- "MDB_MAP_RESIZED: Database contents grew beyond environment mapsize",
|
|
|
- "MDB_INCOMPATIBLE: Operation and DB incompatible, or DB flags changed",
|
|
|
- "MDB_BAD_RSLOT: Invalid reuse of reader locktable slot",
|
|
|
- "MDB_BAD_TXN: Transaction must abort, has a child, or is invalid",
|
|
|
- "MDB_BAD_VALSIZE: Unsupported size of key/DB name/data, or wrong DUPFIXED size",
|
|
|
- "MDB_BAD_DBI: The specified DBI handle was closed/changed unexpectedly",
|
|
|
-};
|
|
|
-
|
|
|
-char *
|
|
|
-mdb_strerror(int err)
|
|
|
-{
|
|
|
-#ifdef _WIN32
|
|
|
- /** HACK: pad 4KB on stack over the buf. Return system msgs in buf.
|
|
|
- * This works as long as no function between the call to mdb_strerror
|
|
|
- * and the actual use of the message uses more than 4K of stack.
|
|
|
- */
|
|
|
-#define MSGSIZE 1024
|
|
|
-#define PADSIZE 4096
|
|
|
- char buf[MSGSIZE+PADSIZE], *ptr = buf;
|
|
|
-#endif
|
|
|
- int i;
|
|
|
- if (!err)
|
|
|
- return ("Successful return: 0");
|
|
|
-
|
|
|
- if (err >= MDB_KEYEXIST && err <= MDB_LAST_ERRCODE) {
|
|
|
- i = err - MDB_KEYEXIST;
|
|
|
- return mdb_errstr[i];
|
|
|
- }
|
|
|
-
|
|
|
-#ifdef _WIN32
|
|
|
- /* These are the C-runtime error codes we use. The comment indicates
|
|
|
- * their numeric value, and the Win32 error they would correspond to
|
|
|
- * if the error actually came from a Win32 API. A major mess, we should
|
|
|
- * have used LMDB-specific error codes for everything.
|
|
|
- */
|
|
|
- switch(err) {
|
|
|
- case ENOENT: /* 2, FILE_NOT_FOUND */
|
|
|
- case EIO: /* 5, ACCESS_DENIED */
|
|
|
- case ENOMEM: /* 12, INVALID_ACCESS */
|
|
|
- case EACCES: /* 13, INVALID_DATA */
|
|
|
- case EBUSY: /* 16, CURRENT_DIRECTORY */
|
|
|
- case EINVAL: /* 22, BAD_COMMAND */
|
|
|
- case ENOSPC: /* 28, OUT_OF_PAPER */
|
|
|
- return strerror(err);
|
|
|
- default:
|
|
|
- ;
|
|
|
- }
|
|
|
- buf[0] = 0;
|
|
|
- FormatMessageA(FORMAT_MESSAGE_FROM_SYSTEM |
|
|
|
- FORMAT_MESSAGE_IGNORE_INSERTS,
|
|
|
- NULL, err, 0, ptr, MSGSIZE, (va_list *)buf+MSGSIZE);
|
|
|
- return ptr;
|
|
|
-#else
|
|
|
- return strerror(err);
|
|
|
-#endif
|
|
|
-}
|
|
|
-
|
|
|
-/** assert(3) variant in cursor context */
|
|
|
-#define mdb_cassert(mc, expr) mdb_assert0((mc)->mc_txn->mt_env, expr, #expr)
|
|
|
-/** assert(3) variant in transaction context */
|
|
|
-#define mdb_tassert(txn, expr) mdb_assert0((txn)->mt_env, expr, #expr)
|
|
|
-/** assert(3) variant in environment context */
|
|
|
-#define mdb_eassert(env, expr) mdb_assert0(env, expr, #expr)
|
|
|
-
|
|
|
-#ifndef NDEBUG
|
|
|
-# define mdb_assert0(env, expr, expr_txt) ((expr) ? (void)0 : \
|
|
|
- mdb_assert_fail(env, expr_txt, mdb_func_, __FILE__, __LINE__))
|
|
|
-
|
|
|
-static void ESECT
|
|
|
-mdb_assert_fail(MDB_env *env, const char *expr_txt,
|
|
|
- const char *func, const char *file, int line)
|
|
|
-{
|
|
|
- char buf[400];
|
|
|
- sprintf(buf, "%.100s:%d: Assertion '%.200s' failed in %.40s()",
|
|
|
- file, line, expr_txt, func);
|
|
|
- if (env->me_assert_func)
|
|
|
- env->me_assert_func(env, buf);
|
|
|
- fprintf(stderr, "%s\n", buf);
|
|
|
- abort();
|
|
|
-}
|
|
|
-#else
|
|
|
-# define mdb_assert0(env, expr, expr_txt) ((void) 0)
|
|
|
-#endif /* NDEBUG */
|
|
|
-
|
|
|
-#if MDB_DEBUG
|
|
|
-/** Return the page number of \b mp which may be sub-page, for debug output */
|
|
|
-static pgno_t
|
|
|
-mdb_dbg_pgno(MDB_page *mp)
|
|
|
-{
|
|
|
- pgno_t ret;
|
|
|
- COPY_PGNO(ret, mp->mp_pgno);
|
|
|
- return ret;
|
|
|
-}
|
|
|
-
|
|
|
-/** Display a key in hexadecimal and return the address of the result.
|
|
|
- * @param[in] key the key to display
|
|
|
- * @param[in] buf the buffer to write into. Should always be #DKBUF.
|
|
|
- * @return The key in hexadecimal form.
|
|
|
- */
|
|
|
-char *
|
|
|
-mdb_dkey(MDB_val *key, char *buf)
|
|
|
-{
|
|
|
- char *ptr = buf;
|
|
|
- unsigned char *c = key->mv_data;
|
|
|
- unsigned int i;
|
|
|
-
|
|
|
- if (!key)
|
|
|
- return "";
|
|
|
-
|
|
|
- if (key->mv_size > DKBUF_MAXKEYSIZE)
|
|
|
- return "MDB_MAXKEYSIZE";
|
|
|
- /* may want to make this a dynamic check: if the key is mostly
|
|
|
- * printable characters, print it as-is instead of converting to hex.
|
|
|
- */
|
|
|
-#if 1
|
|
|
- buf[0] = '\0';
|
|
|
- for (i=0; i<key->mv_size; i++)
|
|
|
- ptr += sprintf(ptr, "%02x", *c++);
|
|
|
-#else
|
|
|
- sprintf(buf, "%.*s", key->mv_size, key->mv_data);
|
|
|
-#endif
|
|
|
- return buf;
|
|
|
-}
|
|
|
-
|
|
|
-static const char *
|
|
|
-mdb_leafnode_type(MDB_node *n)
|
|
|
-{
|
|
|
- static char *const tp[2][2] = {{"", ": DB"}, {": sub-page", ": sub-DB"}};
|
|
|
- return F_ISSET(n->mn_flags, F_BIGDATA) ? ": overflow page" :
|
|
|
- tp[F_ISSET(n->mn_flags, F_DUPDATA)][F_ISSET(n->mn_flags, F_SUBDATA)];
|
|
|
-}
|
|
|
-
|
|
|
-/** Display all the keys in the page. */
|
|
|
-void
|
|
|
-mdb_page_list(MDB_page *mp)
|
|
|
-{
|
|
|
- pgno_t pgno = mdb_dbg_pgno(mp);
|
|
|
- const char *type, *state = (mp->mp_flags & P_DIRTY) ? ", dirty" : "";
|
|
|
- MDB_node *node;
|
|
|
- unsigned int i, nkeys, nsize, total = 0;
|
|
|
- MDB_val key;
|
|
|
- DKBUF;
|
|
|
-
|
|
|
- switch (mp->mp_flags & (P_BRANCH|P_LEAF|P_LEAF2|P_META|P_OVERFLOW|P_SUBP)) {
|
|
|
- case P_BRANCH: type = "Branch page"; break;
|
|
|
- case P_LEAF: type = "Leaf page"; break;
|
|
|
- case P_LEAF|P_SUBP: type = "Sub-page"; break;
|
|
|
- case P_LEAF|P_LEAF2: type = "LEAF2 page"; break;
|
|
|
- case P_LEAF|P_LEAF2|P_SUBP: type = "LEAF2 sub-page"; break;
|
|
|
- case P_OVERFLOW:
|
|
|
- fprintf(stderr, "Overflow page %"Z"u pages %u%s\n",
|
|
|
- pgno, mp->mp_pages, state);
|
|
|
- return;
|
|
|
- case P_META:
|
|
|
- fprintf(stderr, "Meta-page %"Z"u txnid %"Z"u\n",
|
|
|
- pgno, ((MDB_meta *)METADATA(mp))->mm_txnid);
|
|
|
- return;
|
|
|
- default:
|
|
|
- fprintf(stderr, "Bad page %"Z"u flags 0x%X\n", pgno, mp->mp_flags);
|
|
|
- return;
|
|
|
- }
|
|
|
-
|
|
|
- nkeys = NUMKEYS(mp);
|
|
|
- fprintf(stderr, "%s %"Z"u numkeys %d%s\n", type, pgno, nkeys, state);
|
|
|
-
|
|
|
- for (i=0; i<nkeys; i++) {
|
|
|
- if (IS_LEAF2(mp)) { /* LEAF2 pages have no mp_ptrs[] or node headers */
|
|
|
- key.mv_size = nsize = mp->mp_pad;
|
|
|
- key.mv_data = LEAF2KEY(mp, i, nsize);
|
|
|
- total += nsize;
|
|
|
- fprintf(stderr, "key %d: nsize %d, %s\n", i, nsize, DKEY(&key));
|
|
|
- continue;
|
|
|
- }
|
|
|
- node = NODEPTR(mp, i);
|
|
|
- key.mv_size = node->mn_ksize;
|
|
|
- key.mv_data = node->mn_data;
|
|
|
- nsize = NODESIZE + key.mv_size;
|
|
|
- if (IS_BRANCH(mp)) {
|
|
|
- fprintf(stderr, "key %d: page %"Z"u, %s\n", i, NODEPGNO(node),
|
|
|
- DKEY(&key));
|
|
|
- total += nsize;
|
|
|
- } else {
|
|
|
- if (F_ISSET(node->mn_flags, F_BIGDATA))
|
|
|
- nsize += sizeof(pgno_t);
|
|
|
- else
|
|
|
- nsize += NODEDSZ(node);
|
|
|
- total += nsize;
|
|
|
- nsize += sizeof(indx_t);
|
|
|
- fprintf(stderr, "key %d: nsize %d, %s%s\n",
|
|
|
- i, nsize, DKEY(&key), mdb_leafnode_type(node));
|
|
|
- }
|
|
|
- total = EVEN(total);
|
|
|
- }
|
|
|
- fprintf(stderr, "Total: header %d + contents %d + unused %d\n",
|
|
|
- IS_LEAF2(mp) ? PAGEHDRSZ : PAGEBASE + mp->mp_lower, total, SIZELEFT(mp));
|
|
|
-}
|
|
|
-
|
|
|
-void
|
|
|
-mdb_cursor_chk(MDB_cursor *mc)
|
|
|
-{
|
|
|
- unsigned int i;
|
|
|
- MDB_node *node;
|
|
|
- MDB_page *mp;
|
|
|
-
|
|
|
- if (!mc->mc_snum || !(mc->mc_flags & C_INITIALIZED)) return;
|
|
|
- for (i=0; i<mc->mc_top; i++) {
|
|
|
- mp = mc->mc_pg[i];
|
|
|
- node = NODEPTR(mp, mc->mc_ki[i]);
|
|
|
- if (NODEPGNO(node) != mc->mc_pg[i+1]->mp_pgno)
|
|
|
- printf("oops!\n");
|
|
|
- }
|
|
|
- if (mc->mc_ki[i] >= NUMKEYS(mc->mc_pg[i]))
|
|
|
- printf("ack!\n");
|
|
|
- if (XCURSOR_INITED(mc)) {
|
|
|
- node = NODEPTR(mc->mc_pg[mc->mc_top], mc->mc_ki[mc->mc_top]);
|
|
|
- if (((node->mn_flags & (F_DUPDATA|F_SUBDATA)) == F_DUPDATA) &&
|
|
|
- mc->mc_xcursor->mx_cursor.mc_pg[0] != NODEDATA(node)) {
|
|
|
- printf("blah!\n");
|
|
|
- }
|
|
|
- }
|
|
|
-}
|
|
|
-#endif
|
|
|
-
|
|
|
-#if (MDB_DEBUG) > 2
|
|
|
-/** Count all the pages in each DB and in the freelist
|
|
|
- * and make sure it matches the actual number of pages
|
|
|
- * being used.
|
|
|
- * All named DBs must be open for a correct count.
|
|
|
- */
|
|
|
-static void mdb_audit(MDB_txn *txn)
|
|
|
-{
|
|
|
- MDB_cursor mc;
|
|
|
- MDB_val key, data;
|
|
|
- MDB_ID freecount, count;
|
|
|
- MDB_dbi i;
|
|
|
- int rc;
|
|
|
-
|
|
|
- freecount = 0;
|
|
|
- mdb_cursor_init(&mc, txn, FREE_DBI, NULL);
|
|
|
- while ((rc = mdb_cursor_get(&mc, &key, &data, MDB_NEXT)) == 0)
|
|
|
- freecount += *(MDB_ID *)data.mv_data;
|
|
|
- mdb_tassert(txn, rc == MDB_NOTFOUND);
|
|
|
-
|
|
|
- count = 0;
|
|
|
- for (i = 0; i<txn->mt_numdbs; i++) {
|
|
|
- MDB_xcursor mx;
|
|
|
- if (!(txn->mt_dbflags[i] & DB_VALID))
|
|
|
- continue;
|
|
|
- mdb_cursor_init(&mc, txn, i, &mx);
|
|
|
- if (txn->mt_dbs[i].md_root == P_INVALID)
|
|
|
- continue;
|
|
|
- count += txn->mt_dbs[i].md_branch_pages +
|
|
|
- txn->mt_dbs[i].md_leaf_pages +
|
|
|
- txn->mt_dbs[i].md_overflow_pages;
|
|
|
- if (txn->mt_dbs[i].md_flags & MDB_DUPSORT) {
|
|
|
- rc = mdb_page_search(&mc, NULL, MDB_PS_FIRST);
|
|
|
- for (; rc == MDB_SUCCESS; rc = mdb_cursor_sibling(&mc, 1)) {
|
|
|
- unsigned j;
|
|
|
- MDB_page *mp;
|
|
|
- mp = mc.mc_pg[mc.mc_top];
|
|
|
- for (j=0; j<NUMKEYS(mp); j++) {
|
|
|
- MDB_node *leaf = NODEPTR(mp, j);
|
|
|
- if (leaf->mn_flags & F_SUBDATA) {
|
|
|
- MDB_db db;
|
|
|
- memcpy(&db, NODEDATA(leaf), sizeof(db));
|
|
|
- count += db.md_branch_pages + db.md_leaf_pages +
|
|
|
- db.md_overflow_pages;
|
|
|
- }
|
|
|
- }
|
|
|
- }
|
|
|
- mdb_tassert(txn, rc == MDB_NOTFOUND);
|
|
|
- }
|
|
|
- }
|
|
|
- if (freecount + count + NUM_METAS != txn->mt_next_pgno) {
|
|
|
- fprintf(stderr, "audit: %"Z"u freecount: %"Z"u count: %"Z"u total: %"Z"u next_pgno: %"Z"u\n",
|
|
|
- txn->mt_txnid, freecount, count+NUM_METAS,
|
|
|
- freecount+count+NUM_METAS, txn->mt_next_pgno);
|
|
|
- }
|
|
|
-}
|
|
|
-#endif
|
|
|
-
|
|
|
-int
|
|
|
-mdb_cmp(MDB_txn *txn, MDB_dbi dbi, const MDB_val *a, const MDB_val *b)
|
|
|
-{
|
|
|
- return txn->mt_dbxs[dbi].md_cmp(a, b);
|
|
|
-}
|
|
|
-
|
|
|
-int
|
|
|
-mdb_dcmp(MDB_txn *txn, MDB_dbi dbi, const MDB_val *a, const MDB_val *b)
|
|
|
-{
|
|
|
- MDB_cmp_func *dcmp = txn->mt_dbxs[dbi].md_dcmp;
|
|
|
-#if UINT_MAX < SIZE_MAX
|
|
|
- if (dcmp == mdb_cmp_int && a->mv_size == sizeof(size_t))
|
|
|
- dcmp = mdb_cmp_clong;
|
|
|
-#endif
|
|
|
- return dcmp(a, b);
|
|
|
-}
|
|
|
-
|
|
|
-/** Allocate memory for a page.
|
|
|
- * Re-use old malloc'd pages first for singletons, otherwise just malloc.
|
|
|
- * Set #MDB_TXN_ERROR on failure.
|
|
|
- */
|
|
|
-static MDB_page *
|
|
|
-mdb_page_malloc(MDB_txn *txn, unsigned num)
|
|
|
-{
|
|
|
- MDB_env *env = txn->mt_env;
|
|
|
- MDB_page *ret = env->me_dpages;
|
|
|
- size_t psize = env->me_psize, sz = psize, off;
|
|
|
- /* For ! #MDB_NOMEMINIT, psize counts how much to init.
|
|
|
- * For a single page alloc, we init everything after the page header.
|
|
|
- * For multi-page, we init the final page; if the caller needed that
|
|
|
- * many pages they will be filling in at least up to the last page.
|
|
|
- */
|
|
|
- if (num == 1) {
|
|
|
- if (ret) {
|
|
|
- VGMEMP_ALLOC(env, ret, sz);
|
|
|
- VGMEMP_DEFINED(ret, sizeof(ret->mp_next));
|
|
|
- env->me_dpages = ret->mp_next;
|
|
|
- return ret;
|
|
|
- }
|
|
|
- psize -= off = PAGEHDRSZ;
|
|
|
- } else {
|
|
|
- sz *= num;
|
|
|
- off = sz - psize;
|
|
|
- }
|
|
|
- if ((ret = malloc(sz)) != NULL) {
|
|
|
- VGMEMP_ALLOC(env, ret, sz);
|
|
|
- if (!(env->me_flags & MDB_NOMEMINIT)) {
|
|
|
- memset((char *)ret + off, 0, psize);
|
|
|
- ret->mp_pad = 0;
|
|
|
- }
|
|
|
- } else {
|
|
|
- txn->mt_flags |= MDB_TXN_ERROR;
|
|
|
- }
|
|
|
- return ret;
|
|
|
-}
|
|
|
-/** Free a single page.
|
|
|
- * Saves single pages to a list, for future reuse.
|
|
|
- * (This is not used for multi-page overflow pages.)
|
|
|
- */
|
|
|
-static void
|
|
|
-mdb_page_free(MDB_env *env, MDB_page *mp)
|
|
|
-{
|
|
|
- mp->mp_next = env->me_dpages;
|
|
|
- VGMEMP_FREE(env, mp);
|
|
|
- env->me_dpages = mp;
|
|
|
-}
|
|
|
-
|
|
|
-/** Free a dirty page */
|
|
|
-static void
|
|
|
-mdb_dpage_free(MDB_env *env, MDB_page *dp)
|
|
|
-{
|
|
|
- if (!IS_OVERFLOW(dp) || dp->mp_pages == 1) {
|
|
|
- mdb_page_free(env, dp);
|
|
|
- } else {
|
|
|
- /* large pages just get freed directly */
|
|
|
- VGMEMP_FREE(env, dp);
|
|
|
- free(dp);
|
|
|
- }
|
|
|
-}
|
|
|
-
|
|
|
-/** Return all dirty pages to dpage list */
|
|
|
-static void
|
|
|
-mdb_dlist_free(MDB_txn *txn)
|
|
|
-{
|
|
|
- MDB_env *env = txn->mt_env;
|
|
|
- MDB_ID2L dl = txn->mt_u.dirty_list;
|
|
|
- unsigned i, n = dl[0].mid;
|
|
|
-
|
|
|
- for (i = 1; i <= n; i++) {
|
|
|
- mdb_dpage_free(env, dl[i].mptr);
|
|
|
- }
|
|
|
- dl[0].mid = 0;
|
|
|
-}
|
|
|
-
|
|
|
-/** Loosen or free a single page.
|
|
|
- * Saves single pages to a list for future reuse
|
|
|
- * in this same txn. It has been pulled from the freeDB
|
|
|
- * and already resides on the dirty list, but has been
|
|
|
- * deleted. Use these pages first before pulling again
|
|
|
- * from the freeDB.
|
|
|
- *
|
|
|
- * If the page wasn't dirtied in this txn, just add it
|
|
|
- * to this txn's free list.
|
|
|
- */
|
|
|
-static int
|
|
|
-mdb_page_loose(MDB_cursor *mc, MDB_page *mp)
|
|
|
-{
|
|
|
- int loose = 0;
|
|
|
- pgno_t pgno = mp->mp_pgno;
|
|
|
- MDB_txn *txn = mc->mc_txn;
|
|
|
-
|
|
|
- if ((mp->mp_flags & P_DIRTY) && mc->mc_dbi != FREE_DBI) {
|
|
|
- if (txn->mt_parent) {
|
|
|
- MDB_ID2 *dl = txn->mt_u.dirty_list;
|
|
|
- /* If txn has a parent, make sure the page is in our
|
|
|
- * dirty list.
|
|
|
- */
|
|
|
- if (dl[0].mid) {
|
|
|
- unsigned x = mdb_mid2l_search(dl, pgno);
|
|
|
- if (x <= dl[0].mid && dl[x].mid == pgno) {
|
|
|
- if (mp != dl[x].mptr) { /* bad cursor? */
|
|
|
- mc->mc_flags &= ~(C_INITIALIZED|C_EOF);
|
|
|
- txn->mt_flags |= MDB_TXN_ERROR;
|
|
|
- return MDB_CORRUPTED;
|
|
|
- }
|
|
|
- /* ok, it's ours */
|
|
|
- loose = 1;
|
|
|
- }
|
|
|
- }
|
|
|
- } else {
|
|
|
- /* no parent txn, so it's just ours */
|
|
|
- loose = 1;
|
|
|
- }
|
|
|
- }
|
|
|
- if (loose) {
|
|
|
- DPRINTF(("loosen db %d page %"Z"u", DDBI(mc),
|
|
|
- mp->mp_pgno));
|
|
|
- NEXT_LOOSE_PAGE(mp) = txn->mt_loose_pgs;
|
|
|
- txn->mt_loose_pgs = mp;
|
|
|
- txn->mt_loose_count++;
|
|
|
- mp->mp_flags |= P_LOOSE;
|
|
|
- } else {
|
|
|
- int rc = mdb_midl_append(&txn->mt_free_pgs, pgno);
|
|
|
- if (rc)
|
|
|
- return rc;
|
|
|
- }
|
|
|
-
|
|
|
- return MDB_SUCCESS;
|
|
|
-}
|
|
|
-
|
|
|
-/** Set or clear P_KEEP in dirty, non-overflow, non-sub pages watched by txn.
|
|
|
- * @param[in] mc A cursor handle for the current operation.
|
|
|
- * @param[in] pflags Flags of the pages to update:
|
|
|
- * P_DIRTY to set P_KEEP, P_DIRTY|P_KEEP to clear it.
|
|
|
- * @param[in] all No shortcuts. Needed except after a full #mdb_page_flush().
|
|
|
- * @return 0 on success, non-zero on failure.
|
|
|
- */
|
|
|
-static int
|
|
|
-mdb_pages_xkeep(MDB_cursor *mc, unsigned pflags, int all)
|
|
|
-{
|
|
|
- enum { Mask = P_SUBP|P_DIRTY|P_LOOSE|P_KEEP };
|
|
|
- MDB_txn *txn = mc->mc_txn;
|
|
|
- MDB_cursor *m3, *m0 = mc;
|
|
|
- MDB_xcursor *mx;
|
|
|
- MDB_page *dp, *mp;
|
|
|
- MDB_node *leaf;
|
|
|
- unsigned i, j;
|
|
|
- int rc = MDB_SUCCESS, level;
|
|
|
-
|
|
|
- /* Mark pages seen by cursors */
|
|
|
- if (mc->mc_flags & C_UNTRACK)
|
|
|
- mc = NULL; /* will find mc in mt_cursors */
|
|
|
- for (i = txn->mt_numdbs;; mc = txn->mt_cursors[--i]) {
|
|
|
- for (; mc; mc=mc->mc_next) {
|
|
|
- if (!(mc->mc_flags & C_INITIALIZED))
|
|
|
- continue;
|
|
|
- for (m3 = mc;; m3 = &mx->mx_cursor) {
|
|
|
- mp = NULL;
|
|
|
- for (j=0; j<m3->mc_snum; j++) {
|
|
|
- mp = m3->mc_pg[j];
|
|
|
- if ((mp->mp_flags & Mask) == pflags)
|
|
|
- mp->mp_flags ^= P_KEEP;
|
|
|
- }
|
|
|
- mx = m3->mc_xcursor;
|
|
|
- /* Proceed to mx if it is at a sub-database */
|
|
|
- if (! (mx && (mx->mx_cursor.mc_flags & C_INITIALIZED)))
|
|
|
- break;
|
|
|
- if (! (mp && (mp->mp_flags & P_LEAF)))
|
|
|
- break;
|
|
|
- leaf = NODEPTR(mp, m3->mc_ki[j-1]);
|
|
|
- if (!(leaf->mn_flags & F_SUBDATA))
|
|
|
- break;
|
|
|
- }
|
|
|
- }
|
|
|
- if (i == 0)
|
|
|
- break;
|
|
|
- }
|
|
|
-
|
|
|
- if (all) {
|
|
|
- /* Mark dirty root pages */
|
|
|
- for (i=0; i<txn->mt_numdbs; i++) {
|
|
|
- if (txn->mt_dbflags[i] & DB_DIRTY) {
|
|
|
- pgno_t pgno = txn->mt_dbs[i].md_root;
|
|
|
- if (pgno == P_INVALID)
|
|
|
- continue;
|
|
|
- if ((rc = mdb_page_get(m0, pgno, &dp, &level)) != MDB_SUCCESS)
|
|
|
- break;
|
|
|
- if ((dp->mp_flags & Mask) == pflags && level <= 1)
|
|
|
- dp->mp_flags ^= P_KEEP;
|
|
|
- }
|
|
|
- }
|
|
|
- }
|
|
|
-
|
|
|
- return rc;
|
|
|
-}
|
|
|
-
|
|
|
-static int mdb_page_flush(MDB_txn *txn, int keep);
|
|
|
-
|
|
|
-/** Spill pages from the dirty list back to disk.
|
|
|
- * This is intended to prevent running into #MDB_TXN_FULL situations,
|
|
|
- * but note that they may still occur in a few cases:
|
|
|
- * 1) our estimate of the txn size could be too small. Currently this
|
|
|
- * seems unlikely, except with a large number of #MDB_MULTIPLE items.
|
|
|
- * 2) child txns may run out of space if their parents dirtied a
|
|
|
- * lot of pages and never spilled them. TODO: we probably should do
|
|
|
- * a preemptive spill during #mdb_txn_begin() of a child txn, if
|
|
|
- * the parent's dirty_room is below a given threshold.
|
|
|
- *
|
|
|
- * Otherwise, if not using nested txns, it is expected that apps will
|
|
|
- * not run into #MDB_TXN_FULL any more. The pages are flushed to disk
|
|
|
- * the same way as for a txn commit, e.g. their P_DIRTY flag is cleared.
|
|
|
- * If the txn never references them again, they can be left alone.
|
|
|
- * If the txn only reads them, they can be used without any fuss.
|
|
|
- * If the txn writes them again, they can be dirtied immediately without
|
|
|
- * going thru all of the work of #mdb_page_touch(). Such references are
|
|
|
- * handled by #mdb_page_unspill().
|
|
|
- *
|
|
|
- * Also note, we never spill DB root pages, nor pages of active cursors,
|
|
|
- * because we'll need these back again soon anyway. And in nested txns,
|
|
|
- * we can't spill a page in a child txn if it was already spilled in a
|
|
|
- * parent txn. That would alter the parent txns' data even though
|
|
|
- * the child hasn't committed yet, and we'd have no way to undo it if
|
|
|
- * the child aborted.
|
|
|
- *
|
|
|
- * @param[in] m0 cursor A cursor handle identifying the transaction and
|
|
|
- * database for which we are checking space.
|
|
|
- * @param[in] key For a put operation, the key being stored.
|
|
|
- * @param[in] data For a put operation, the data being stored.
|
|
|
- * @return 0 on success, non-zero on failure.
|
|
|
- */
|
|
|
-static int
|
|
|
-mdb_page_spill(MDB_cursor *m0, MDB_val *key, MDB_val *data)
|
|
|
-{
|
|
|
- MDB_txn *txn = m0->mc_txn;
|
|
|
- MDB_page *dp;
|
|
|
- MDB_ID2L dl = txn->mt_u.dirty_list;
|
|
|
- unsigned int i, j, need;
|
|
|
- int rc;
|
|
|
-
|
|
|
- if (m0->mc_flags & C_SUB)
|
|
|
- return MDB_SUCCESS;
|
|
|
-
|
|
|
- /* Estimate how much space this op will take */
|
|
|
- i = m0->mc_db->md_depth;
|
|
|
- /* Named DBs also dirty the main DB */
|
|
|
- if (m0->mc_dbi >= CORE_DBS)
|
|
|
- i += txn->mt_dbs[MAIN_DBI].md_depth;
|
|
|
- /* For puts, roughly factor in the key+data size */
|
|
|
- if (key)
|
|
|
- i += (LEAFSIZE(key, data) + txn->mt_env->me_psize) / txn->mt_env->me_psize;
|
|
|
- i += i; /* double it for good measure */
|
|
|
- need = i;
|
|
|
-
|
|
|
- if (txn->mt_dirty_room > i)
|
|
|
- return MDB_SUCCESS;
|
|
|
-
|
|
|
- if (!txn->mt_spill_pgs) {
|
|
|
- txn->mt_spill_pgs = mdb_midl_alloc(MDB_IDL_UM_MAX);
|
|
|
- if (!txn->mt_spill_pgs)
|
|
|
- return ENOMEM;
|
|
|
- } else {
|
|
|
- /* purge deleted slots */
|
|
|
- MDB_IDL sl = txn->mt_spill_pgs;
|
|
|
- unsigned int num = sl[0];
|
|
|
- j=0;
|
|
|
- for (i=1; i<=num; i++) {
|
|
|
- if (!(sl[i] & 1))
|
|
|
- sl[++j] = sl[i];
|
|
|
- }
|
|
|
- sl[0] = j;
|
|
|
- }
|
|
|
-
|
|
|
- /* Preserve pages which may soon be dirtied again */
|
|
|
- if ((rc = mdb_pages_xkeep(m0, P_DIRTY, 1)) != MDB_SUCCESS)
|
|
|
- goto done;
|
|
|
-
|
|
|
- /* Less aggressive spill - we originally spilled the entire dirty list,
|
|
|
- * with a few exceptions for cursor pages and DB root pages. But this
|
|
|
- * turns out to be a lot of wasted effort because in a large txn many
|
|
|
- * of those pages will need to be used again. So now we spill only 1/8th
|
|
|
- * of the dirty pages. Testing revealed this to be a good tradeoff,
|
|
|
- * better than 1/2, 1/4, or 1/10.
|
|
|
- */
|
|
|
- if (need < MDB_IDL_UM_MAX / 8)
|
|
|
- need = MDB_IDL_UM_MAX / 8;
|
|
|
-
|
|
|
- /* Save the page IDs of all the pages we're flushing */
|
|
|
- /* flush from the tail forward, this saves a lot of shifting later on. */
|
|
|
- for (i=dl[0].mid; i && need; i--) {
|
|
|
- MDB_ID pn = dl[i].mid << 1;
|
|
|
- dp = dl[i].mptr;
|
|
|
- if (dp->mp_flags & (P_LOOSE|P_KEEP))
|
|
|
- continue;
|
|
|
- /* Can't spill twice, make sure it's not already in a parent's
|
|
|
- * spill list.
|
|
|
- */
|
|
|
- if (txn->mt_parent) {
|
|
|
- MDB_txn *tx2;
|
|
|
- for (tx2 = txn->mt_parent; tx2; tx2 = tx2->mt_parent) {
|
|
|
- if (tx2->mt_spill_pgs) {
|
|
|
- j = mdb_midl_search(tx2->mt_spill_pgs, pn);
|
|
|
- if (j <= tx2->mt_spill_pgs[0] && tx2->mt_spill_pgs[j] == pn) {
|
|
|
- dp->mp_flags |= P_KEEP;
|
|
|
- break;
|
|
|
- }
|
|
|
- }
|
|
|
- }
|
|
|
- if (tx2)
|
|
|
- continue;
|
|
|
- }
|
|
|
- if ((rc = mdb_midl_append(&txn->mt_spill_pgs, pn)))
|
|
|
- goto done;
|
|
|
- need--;
|
|
|
- }
|
|
|
- mdb_midl_sort(txn->mt_spill_pgs);
|
|
|
-
|
|
|
- /* Flush the spilled part of dirty list */
|
|
|
- if ((rc = mdb_page_flush(txn, i)) != MDB_SUCCESS)
|
|
|
- goto done;
|
|
|
-
|
|
|
- /* Reset any dirty pages we kept that page_flush didn't see */
|
|
|
- rc = mdb_pages_xkeep(m0, P_DIRTY|P_KEEP, i);
|
|
|
-
|
|
|
-done:
|
|
|
- txn->mt_flags |= rc ? MDB_TXN_ERROR : MDB_TXN_SPILLS;
|
|
|
- return rc;
|
|
|
-}
|
|
|
-
|
|
|
-/** Find oldest txnid still referenced. Expects txn->mt_txnid > 0. */
|
|
|
-static txnid_t
|
|
|
-mdb_find_oldest(MDB_txn *txn)
|
|
|
-{
|
|
|
- int i;
|
|
|
- txnid_t mr, oldest = txn->mt_txnid - 1;
|
|
|
- if (txn->mt_env->me_txns) {
|
|
|
- MDB_reader *r = txn->mt_env->me_txns->mti_readers;
|
|
|
- for (i = txn->mt_env->me_txns->mti_numreaders; --i >= 0; ) {
|
|
|
- if (r[i].mr_pid) {
|
|
|
- mr = r[i].mr_txnid;
|
|
|
- if (oldest > mr)
|
|
|
- oldest = mr;
|
|
|
- }
|
|
|
- }
|
|
|
- }
|
|
|
- return oldest;
|
|
|
-}
|
|
|
-
|
|
|
-/** Add a page to the txn's dirty list */
|
|
|
-static void
|
|
|
-mdb_page_dirty(MDB_txn *txn, MDB_page *mp)
|
|
|
-{
|
|
|
- MDB_ID2 mid;
|
|
|
- int rc, (*insert)(MDB_ID2L, MDB_ID2 *);
|
|
|
-
|
|
|
- if (txn->mt_flags & MDB_TXN_WRITEMAP) {
|
|
|
- insert = mdb_mid2l_append;
|
|
|
- } else {
|
|
|
- insert = mdb_mid2l_insert;
|
|
|
- }
|
|
|
- mid.mid = mp->mp_pgno;
|
|
|
- mid.mptr = mp;
|
|
|
- rc = insert(txn->mt_u.dirty_list, &mid);
|
|
|
- mdb_tassert(txn, rc == 0);
|
|
|
- txn->mt_dirty_room--;
|
|
|
-}
|
|
|
-
|
|
|
-/** Allocate page numbers and memory for writing. Maintain me_pglast,
|
|
|
- * me_pghead and mt_next_pgno. Set #MDB_TXN_ERROR on failure.
|
|
|
- *
|
|
|
- * If there are free pages available from older transactions, they
|
|
|
- * are re-used first. Otherwise allocate a new page at mt_next_pgno.
|
|
|
- * Do not modify the freedB, just merge freeDB records into me_pghead[]
|
|
|
- * and move me_pglast to say which records were consumed. Only this
|
|
|
- * function can create me_pghead and move me_pglast/mt_next_pgno.
|
|
|
- * @param[in] mc cursor A cursor handle identifying the transaction and
|
|
|
- * database for which we are allocating.
|
|
|
- * @param[in] num the number of pages to allocate.
|
|
|
- * @param[out] mp Address of the allocated page(s). Requests for multiple pages
|
|
|
- * will always be satisfied by a single contiguous chunk of memory.
|
|
|
- * @return 0 on success, non-zero on failure.
|
|
|
- */
|
|
|
-static int
|
|
|
-mdb_page_alloc(MDB_cursor *mc, int num, MDB_page **mp)
|
|
|
-{
|
|
|
-#ifdef MDB_PARANOID /* Seems like we can ignore this now */
|
|
|
- /* Get at most <Max_retries> more freeDB records once me_pghead
|
|
|
- * has enough pages. If not enough, use new pages from the map.
|
|
|
- * If <Paranoid> and mc is updating the freeDB, only get new
|
|
|
- * records if me_pghead is empty. Then the freelist cannot play
|
|
|
- * catch-up with itself by growing while trying to save it.
|
|
|
- */
|
|
|
- enum { Paranoid = 1, Max_retries = 500 };
|
|
|
-#else
|
|
|
- enum { Paranoid = 0, Max_retries = INT_MAX /*infinite*/ };
|
|
|
-#endif
|
|
|
- int rc, retry = num * 60;
|
|
|
- MDB_txn *txn = mc->mc_txn;
|
|
|
- MDB_env *env = txn->mt_env;
|
|
|
- pgno_t pgno, *mop = env->me_pghead;
|
|
|
- unsigned i, j, mop_len = mop ? mop[0] : 0, n2 = num-1;
|
|
|
- MDB_page *np;
|
|
|
- txnid_t oldest = 0, last;
|
|
|
- MDB_cursor_op op;
|
|
|
- MDB_cursor m2;
|
|
|
- int found_old = 0;
|
|
|
-
|
|
|
- /* If there are any loose pages, just use them */
|
|
|
- if (num == 1 && txn->mt_loose_pgs) {
|
|
|
- np = txn->mt_loose_pgs;
|
|
|
- txn->mt_loose_pgs = NEXT_LOOSE_PAGE(np);
|
|
|
- txn->mt_loose_count--;
|
|
|
- DPRINTF(("db %d use loose page %"Z"u", DDBI(mc),
|
|
|
- np->mp_pgno));
|
|
|
- *mp = np;
|
|
|
- return MDB_SUCCESS;
|
|
|
- }
|
|
|
-
|
|
|
- *mp = NULL;
|
|
|
-
|
|
|
- /* If our dirty list is already full, we can't do anything */
|
|
|
- if (txn->mt_dirty_room == 0) {
|
|
|
- rc = MDB_TXN_FULL;
|
|
|
- goto fail;
|
|
|
- }
|
|
|
-
|
|
|
- for (op = MDB_FIRST;; op = MDB_NEXT) {
|
|
|
- MDB_val key, data;
|
|
|
- MDB_node *leaf;
|
|
|
- pgno_t *idl;
|
|
|
-
|
|
|
- /* Seek a big enough contiguous page range. Prefer
|
|
|
- * pages at the tail, just truncating the list.
|
|
|
- */
|
|
|
- if (mop_len > n2) {
|
|
|
- i = mop_len;
|
|
|
- do {
|
|
|
- pgno = mop[i];
|
|
|
- if (mop[i-n2] == pgno+n2)
|
|
|
- goto search_done;
|
|
|
- } while (--i > n2);
|
|
|
- if (--retry < 0)
|
|
|
- break;
|
|
|
- }
|
|
|
-
|
|
|
- if (op == MDB_FIRST) { /* 1st iteration */
|
|
|
- /* Prepare to fetch more and coalesce */
|
|
|
- last = env->me_pglast;
|
|
|
- oldest = env->me_pgoldest;
|
|
|
- mdb_cursor_init(&m2, txn, FREE_DBI, NULL);
|
|
|
- if (last) {
|
|
|
- op = MDB_SET_RANGE;
|
|
|
- key.mv_data = &last; /* will look up last+1 */
|
|
|
- key.mv_size = sizeof(last);
|
|
|
- }
|
|
|
- if (Paranoid && mc->mc_dbi == FREE_DBI)
|
|
|
- retry = -1;
|
|
|
- }
|
|
|
- if (Paranoid && retry < 0 && mop_len)
|
|
|
- break;
|
|
|
-
|
|
|
- last++;
|
|
|
- /* Do not fetch more if the record will be too recent */
|
|
|
- if (oldest <= last) {
|
|
|
- if (!found_old) {
|
|
|
- oldest = mdb_find_oldest(txn);
|
|
|
- env->me_pgoldest = oldest;
|
|
|
- found_old = 1;
|
|
|
- }
|
|
|
- if (oldest <= last)
|
|
|
- break;
|
|
|
- }
|
|
|
- rc = mdb_cursor_get(&m2, &key, NULL, op);
|
|
|
- if (rc) {
|
|
|
- if (rc == MDB_NOTFOUND)
|
|
|
- break;
|
|
|
- goto fail;
|
|
|
- }
|
|
|
- last = *(txnid_t*)key.mv_data;
|
|
|
- if (oldest <= last) {
|
|
|
- if (!found_old) {
|
|
|
- oldest = mdb_find_oldest(txn);
|
|
|
- env->me_pgoldest = oldest;
|
|
|
- found_old = 1;
|
|
|
- }
|
|
|
- if (oldest <= last)
|
|
|
- break;
|
|
|
- }
|
|
|
- np = m2.mc_pg[m2.mc_top];
|
|
|
- leaf = NODEPTR(np, m2.mc_ki[m2.mc_top]);
|
|
|
- if ((rc = mdb_node_read(&m2, leaf, &data)) != MDB_SUCCESS)
|
|
|
- goto fail;
|
|
|
-
|
|
|
- idl = (MDB_ID *) data.mv_data;
|
|
|
- i = idl[0];
|
|
|
- if (!mop) {
|
|
|
- if (!(env->me_pghead = mop = mdb_midl_alloc(i))) {
|
|
|
- rc = ENOMEM;
|
|
|
- goto fail;
|
|
|
- }
|
|
|
- } else {
|
|
|
- if ((rc = mdb_midl_need(&env->me_pghead, i)) != 0)
|
|
|
- goto fail;
|
|
|
- mop = env->me_pghead;
|
|
|
- }
|
|
|
- env->me_pglast = last;
|
|
|
-#if (MDB_DEBUG) > 1
|
|
|
- DPRINTF(("IDL read txn %"Z"u root %"Z"u num %u",
|
|
|
- last, txn->mt_dbs[FREE_DBI].md_root, i));
|
|
|
- for (j = i; j; j--)
|
|
|
- DPRINTF(("IDL %"Z"u", idl[j]));
|
|
|
-#endif
|
|
|
- /* Merge in descending sorted order */
|
|
|
- mdb_midl_xmerge(mop, idl);
|
|
|
- mop_len = mop[0];
|
|
|
- }
|
|
|
-
|
|
|
- /* Use new pages from the map when nothing suitable in the freeDB */
|
|
|
- i = 0;
|
|
|
- pgno = txn->mt_next_pgno;
|
|
|
- if (pgno + num >= env->me_maxpg) {
|
|
|
- DPUTS("DB size maxed out");
|
|
|
- rc = MDB_MAP_FULL;
|
|
|
- goto fail;
|
|
|
- }
|
|
|
-
|
|
|
-search_done:
|
|
|
- if (env->me_flags & MDB_WRITEMAP) {
|
|
|
- np = (MDB_page *)(env->me_map + env->me_psize * pgno);
|
|
|
- } else {
|
|
|
- if (!(np = mdb_page_malloc(txn, num))) {
|
|
|
- rc = ENOMEM;
|
|
|
- goto fail;
|
|
|
- }
|
|
|
- }
|
|
|
- if (i) {
|
|
|
- mop[0] = mop_len -= num;
|
|
|
- /* Move any stragglers down */
|
|
|
- for (j = i-num; j < mop_len; )
|
|
|
- mop[++j] = mop[++i];
|
|
|
- } else {
|
|
|
- txn->mt_next_pgno = pgno + num;
|
|
|
- }
|
|
|
- np->mp_pgno = pgno;
|
|
|
- mdb_page_dirty(txn, np);
|
|
|
- *mp = np;
|
|
|
-
|
|
|
- return MDB_SUCCESS;
|
|
|
-
|
|
|
-fail:
|
|
|
- txn->mt_flags |= MDB_TXN_ERROR;
|
|
|
- return rc;
|
|
|
-}
|
|
|
-
|
|
|
-/** Copy the used portions of a non-overflow page.
|
|
|
- * @param[in] dst page to copy into
|
|
|
- * @param[in] src page to copy from
|
|
|
- * @param[in] psize size of a page
|
|
|
- */
|
|
|
-static void
|
|
|
-mdb_page_copy(MDB_page *dst, MDB_page *src, unsigned int psize)
|
|
|
-{
|
|
|
- enum { Align = sizeof(pgno_t) };
|
|
|
- indx_t upper = src->mp_upper, lower = src->mp_lower, unused = upper-lower;
|
|
|
-
|
|
|
- /* If page isn't full, just copy the used portion. Adjust
|
|
|
- * alignment so memcpy may copy words instead of bytes.
|
|
|
- */
|
|
|
- if ((unused &= -Align) && !IS_LEAF2(src)) {
|
|
|
- upper = (upper + PAGEBASE) & -Align;
|
|
|
- memcpy(dst, src, (lower + PAGEBASE + (Align-1)) & -Align);
|
|
|
- memcpy((pgno_t *)((char *)dst+upper), (pgno_t *)((char *)src+upper),
|
|
|
- psize - upper);
|
|
|
- } else {
|
|
|
- memcpy(dst, src, psize - unused);
|
|
|
- }
|
|
|
-}
|
|
|
-
|
|
|
-/** Pull a page off the txn's spill list, if present.
|
|
|
- * If a page being referenced was spilled to disk in this txn, bring
|
|
|
- * it back and make it dirty/writable again.
|
|
|
- * @param[in] txn the transaction handle.
|
|
|
- * @param[in] mp the page being referenced. It must not be dirty.
|
|
|
- * @param[out] ret the writable page, if any. ret is unchanged if
|
|
|
- * mp wasn't spilled.
|
|
|
- */
|
|
|
-static int
|
|
|
-mdb_page_unspill(MDB_txn *txn, MDB_page *mp, MDB_page **ret)
|
|
|
-{
|
|
|
- MDB_env *env = txn->mt_env;
|
|
|
- const MDB_txn *tx2;
|
|
|
- unsigned x;
|
|
|
- pgno_t pgno = mp->mp_pgno, pn = pgno << 1;
|
|
|
-
|
|
|
- for (tx2 = txn; tx2; tx2=tx2->mt_parent) {
|
|
|
- if (!tx2->mt_spill_pgs)
|
|
|
- continue;
|
|
|
- x = mdb_midl_search(tx2->mt_spill_pgs, pn);
|
|
|
- if (x <= tx2->mt_spill_pgs[0] && tx2->mt_spill_pgs[x] == pn) {
|
|
|
- MDB_page *np;
|
|
|
- int num;
|
|
|
- if (txn->mt_dirty_room == 0)
|
|
|
- return MDB_TXN_FULL;
|
|
|
- if (IS_OVERFLOW(mp))
|
|
|
- num = mp->mp_pages;
|
|
|
- else
|
|
|
- num = 1;
|
|
|
- if (env->me_flags & MDB_WRITEMAP) {
|
|
|
- np = mp;
|
|
|
- } else {
|
|
|
- np = mdb_page_malloc(txn, num);
|
|
|
- if (!np)
|
|
|
- return ENOMEM;
|
|
|
- if (num > 1)
|
|
|
- memcpy(np, mp, num * env->me_psize);
|
|
|
- else
|
|
|
- mdb_page_copy(np, mp, env->me_psize);
|
|
|
- }
|
|
|
- if (tx2 == txn) {
|
|
|
- /* If in current txn, this page is no longer spilled.
|
|
|
- * If it happens to be the last page, truncate the spill list.
|
|
|
- * Otherwise mark it as deleted by setting the LSB.
|
|
|
- */
|
|
|
- if (x == txn->mt_spill_pgs[0])
|
|
|
- txn->mt_spill_pgs[0]--;
|
|
|
- else
|
|
|
- txn->mt_spill_pgs[x] |= 1;
|
|
|
- } /* otherwise, if belonging to a parent txn, the
|
|
|
- * page remains spilled until child commits
|
|
|
- */
|
|
|
-
|
|
|
- mdb_page_dirty(txn, np);
|
|
|
- np->mp_flags |= P_DIRTY;
|
|
|
- *ret = np;
|
|
|
- break;
|
|
|
- }
|
|
|
- }
|
|
|
- return MDB_SUCCESS;
|
|
|
-}
|
|
|
-
|
|
|
-/** Touch a page: make it dirty and re-insert into tree with updated pgno.
|
|
|
- * Set #MDB_TXN_ERROR on failure.
|
|
|
- * @param[in] mc cursor pointing to the page to be touched
|
|
|
- * @return 0 on success, non-zero on failure.
|
|
|
- */
|
|
|
-static int
|
|
|
-mdb_page_touch(MDB_cursor *mc)
|
|
|
-{
|
|
|
- MDB_page *mp = mc->mc_pg[mc->mc_top], *np;
|
|
|
- MDB_txn *txn = mc->mc_txn;
|
|
|
- MDB_cursor *m2, *m3;
|
|
|
- pgno_t pgno;
|
|
|
- int rc;
|
|
|
-
|
|
|
- if (!F_ISSET(mp->mp_flags, P_DIRTY)) {
|
|
|
- if (txn->mt_flags & MDB_TXN_SPILLS) {
|
|
|
- np = NULL;
|
|
|
- rc = mdb_page_unspill(txn, mp, &np);
|
|
|
- if (rc)
|
|
|
- goto fail;
|
|
|
- if (np)
|
|
|
- goto done;
|
|
|
- }
|
|
|
- if ((rc = mdb_midl_need(&txn->mt_free_pgs, 1)) ||
|
|
|
- (rc = mdb_page_alloc(mc, 1, &np)))
|
|
|
- goto fail;
|
|
|
- pgno = np->mp_pgno;
|
|
|
- DPRINTF(("touched db %d page %"Z"u -> %"Z"u", DDBI(mc),
|
|
|
- mp->mp_pgno, pgno));
|
|
|
- mdb_cassert(mc, mp->mp_pgno != pgno);
|
|
|
- mdb_midl_xappend(txn->mt_free_pgs, mp->mp_pgno);
|
|
|
- /* Update the parent page, if any, to point to the new page */
|
|
|
- if (mc->mc_top) {
|
|
|
- MDB_page *parent = mc->mc_pg[mc->mc_top-1];
|
|
|
- MDB_node *node = NODEPTR(parent, mc->mc_ki[mc->mc_top-1]);
|
|
|
- SETPGNO(node, pgno);
|
|
|
- } else {
|
|
|
- mc->mc_db->md_root = pgno;
|
|
|
- }
|
|
|
- } else if (txn->mt_parent && !IS_SUBP(mp)) {
|
|
|
- MDB_ID2 mid, *dl = txn->mt_u.dirty_list;
|
|
|
- pgno = mp->mp_pgno;
|
|
|
- /* If txn has a parent, make sure the page is in our
|
|
|
- * dirty list.
|
|
|
- */
|
|
|
- if (dl[0].mid) {
|
|
|
- unsigned x = mdb_mid2l_search(dl, pgno);
|
|
|
- if (x <= dl[0].mid && dl[x].mid == pgno) {
|
|
|
- if (mp != dl[x].mptr) { /* bad cursor? */
|
|
|
- mc->mc_flags &= ~(C_INITIALIZED|C_EOF);
|
|
|
- txn->mt_flags |= MDB_TXN_ERROR;
|
|
|
- return MDB_CORRUPTED;
|
|
|
- }
|
|
|
- return 0;
|
|
|
- }
|
|
|
- }
|
|
|
- mdb_cassert(mc, dl[0].mid < MDB_IDL_UM_MAX);
|
|
|
- /* No - copy it */
|
|
|
- np = mdb_page_malloc(txn, 1);
|
|
|
- if (!np)
|
|
|
- return ENOMEM;
|
|
|
- mid.mid = pgno;
|
|
|
- mid.mptr = np;
|
|
|
- rc = mdb_mid2l_insert(dl, &mid);
|
|
|
- mdb_cassert(mc, rc == 0);
|
|
|
- } else {
|
|
|
- return 0;
|
|
|
- }
|
|
|
-
|
|
|
- mdb_page_copy(np, mp, txn->mt_env->me_psize);
|
|
|
- np->mp_pgno = pgno;
|
|
|
- np->mp_flags |= P_DIRTY;
|
|
|
-
|
|
|
-done:
|
|
|
- /* Adjust cursors pointing to mp */
|
|
|
- mc->mc_pg[mc->mc_top] = np;
|
|
|
- m2 = txn->mt_cursors[mc->mc_dbi];
|
|
|
- if (mc->mc_flags & C_SUB) {
|
|
|
- for (; m2; m2=m2->mc_next) {
|
|
|
- m3 = &m2->mc_xcursor->mx_cursor;
|
|
|
- if (m3->mc_snum < mc->mc_snum) continue;
|
|
|
- if (m3->mc_pg[mc->mc_top] == mp)
|
|
|
- m3->mc_pg[mc->mc_top] = np;
|
|
|
- }
|
|
|
- } else {
|
|
|
- for (; m2; m2=m2->mc_next) {
|
|
|
- if (m2->mc_snum < mc->mc_snum) continue;
|
|
|
- if (m2 == mc) continue;
|
|
|
- if (m2->mc_pg[mc->mc_top] == mp) {
|
|
|
- m2->mc_pg[mc->mc_top] = np;
|
|
|
- if (IS_LEAF(np))
|
|
|
- XCURSOR_REFRESH(m2, mc->mc_top, np);
|
|
|
- }
|
|
|
- }
|
|
|
- }
|
|
|
- return 0;
|
|
|
-
|
|
|
-fail:
|
|
|
- txn->mt_flags |= MDB_TXN_ERROR;
|
|
|
- return rc;
|
|
|
-}
|
|
|
-
|
|
|
-int
|
|
|
-mdb_env_sync(MDB_env *env, int force)
|
|
|
-{
|
|
|
- int rc = 0;
|
|
|
- if (env->me_flags & MDB_RDONLY)
|
|
|
- return EACCES;
|
|
|
- if (force || !F_ISSET(env->me_flags, MDB_NOSYNC)) {
|
|
|
- if (env->me_flags & MDB_WRITEMAP) {
|
|
|
- int flags = ((env->me_flags & MDB_MAPASYNC) && !force)
|
|
|
- ? MS_ASYNC : MS_SYNC;
|
|
|
- if (MDB_MSYNC(env->me_map, env->me_mapsize, flags))
|
|
|
- rc = ErrCode();
|
|
|
-#ifdef _WIN32
|
|
|
- else if (flags == MS_SYNC && MDB_FDATASYNC(env->me_fd))
|
|
|
- rc = ErrCode();
|
|
|
-#endif
|
|
|
- } else {
|
|
|
-#ifdef BROKEN_FDATASYNC
|
|
|
- if (env->me_flags & MDB_FSYNCONLY) {
|
|
|
- if (fsync(env->me_fd))
|
|
|
- rc = ErrCode();
|
|
|
- } else
|
|
|
-#endif
|
|
|
- if (MDB_FDATASYNC(env->me_fd))
|
|
|
- rc = ErrCode();
|
|
|
- }
|
|
|
- }
|
|
|
- return rc;
|
|
|
-}
|
|
|
-
|
|
|
-/** Back up parent txn's cursors, then grab the originals for tracking */
|
|
|
-static int
|
|
|
-mdb_cursor_shadow(MDB_txn *src, MDB_txn *dst)
|
|
|
-{
|
|
|
- MDB_cursor *mc, *bk;
|
|
|
- MDB_xcursor *mx;
|
|
|
- size_t size;
|
|
|
- int i;
|
|
|
-
|
|
|
- for (i = src->mt_numdbs; --i >= 0; ) {
|
|
|
- if ((mc = src->mt_cursors[i]) != NULL) {
|
|
|
- size = sizeof(MDB_cursor);
|
|
|
- if (mc->mc_xcursor)
|
|
|
- size += sizeof(MDB_xcursor);
|
|
|
- for (; mc; mc = bk->mc_next) {
|
|
|
- bk = malloc(size);
|
|
|
- if (!bk)
|
|
|
- return ENOMEM;
|
|
|
- *bk = *mc;
|
|
|
- mc->mc_backup = bk;
|
|
|
- mc->mc_db = &dst->mt_dbs[i];
|
|
|
- /* Kill pointers into src to reduce abuse: The
|
|
|
- * user may not use mc until dst ends. But we need a valid
|
|
|
- * txn pointer here for cursor fixups to keep working.
|
|
|
- */
|
|
|
- mc->mc_txn = dst;
|
|
|
- mc->mc_dbflag = &dst->mt_dbflags[i];
|
|
|
- if ((mx = mc->mc_xcursor) != NULL) {
|
|
|
- *(MDB_xcursor *)(bk+1) = *mx;
|
|
|
- mx->mx_cursor.mc_txn = dst;
|
|
|
- }
|
|
|
- mc->mc_next = dst->mt_cursors[i];
|
|
|
- dst->mt_cursors[i] = mc;
|
|
|
- }
|
|
|
- }
|
|
|
- }
|
|
|
- return MDB_SUCCESS;
|
|
|
-}
|
|
|
-
|
|
|
-/** Close this write txn's cursors, give parent txn's cursors back to parent.
|
|
|
- * @param[in] txn the transaction handle.
|
|
|
- * @param[in] merge true to keep changes to parent cursors, false to revert.
|
|
|
- * @return 0 on success, non-zero on failure.
|
|
|
- */
|
|
|
-static void
|
|
|
-mdb_cursors_close(MDB_txn *txn, unsigned merge)
|
|
|
-{
|
|
|
- MDB_cursor **cursors = txn->mt_cursors, *mc, *next, *bk;
|
|
|
- MDB_xcursor *mx;
|
|
|
- int i;
|
|
|
-
|
|
|
- for (i = txn->mt_numdbs; --i >= 0; ) {
|
|
|
- for (mc = cursors[i]; mc; mc = next) {
|
|
|
- next = mc->mc_next;
|
|
|
- if ((bk = mc->mc_backup) != NULL) {
|
|
|
- if (merge) {
|
|
|
- /* Commit changes to parent txn */
|
|
|
- mc->mc_next = bk->mc_next;
|
|
|
- mc->mc_backup = bk->mc_backup;
|
|
|
- mc->mc_txn = bk->mc_txn;
|
|
|
- mc->mc_db = bk->mc_db;
|
|
|
- mc->mc_dbflag = bk->mc_dbflag;
|
|
|
- if ((mx = mc->mc_xcursor) != NULL)
|
|
|
- mx->mx_cursor.mc_txn = bk->mc_txn;
|
|
|
- } else {
|
|
|
- /* Abort nested txn */
|
|
|
- *mc = *bk;
|
|
|
- if ((mx = mc->mc_xcursor) != NULL)
|
|
|
- *mx = *(MDB_xcursor *)(bk+1);
|
|
|
- }
|
|
|
- mc = bk;
|
|
|
- }
|
|
|
- /* Only malloced cursors are permanently tracked. */
|
|
|
- free(mc);
|
|
|
- }
|
|
|
- cursors[i] = NULL;
|
|
|
- }
|
|
|
-}
|
|
|
-
|
|
|
-#if !(MDB_PIDLOCK) /* Currently the same as defined(_WIN32) */
|
|
|
-enum Pidlock_op {
|
|
|
- Pidset, Pidcheck
|
|
|
-};
|
|
|
-#else
|
|
|
-enum Pidlock_op {
|
|
|
- Pidset = F_SETLK, Pidcheck = F_GETLK
|
|
|
-};
|
|
|
-#endif
|
|
|
-
|
|
|
-/** Set or check a pid lock. Set returns 0 on success.
|
|
|
- * Check returns 0 if the process is certainly dead, nonzero if it may
|
|
|
- * be alive (the lock exists or an error happened so we do not know).
|
|
|
- *
|
|
|
- * On Windows Pidset is a no-op, we merely check for the existence
|
|
|
- * of the process with the given pid. On POSIX we use a single byte
|
|
|
- * lock on the lockfile, set at an offset equal to the pid.
|
|
|
- */
|
|
|
-static int
|
|
|
-mdb_reader_pid(MDB_env *env, enum Pidlock_op op, MDB_PID_T pid)
|
|
|
-{
|
|
|
-#if !(MDB_PIDLOCK) /* Currently the same as defined(_WIN32) */
|
|
|
- int ret = 0;
|
|
|
- HANDLE h;
|
|
|
- if (op == Pidcheck) {
|
|
|
- h = OpenProcess(env->me_pidquery, FALSE, pid);
|
|
|
- /* No documented "no such process" code, but other program use this: */
|
|
|
- if (!h)
|
|
|
- return ErrCode() != ERROR_INVALID_PARAMETER;
|
|
|
- /* A process exists until all handles to it close. Has it exited? */
|
|
|
- ret = WaitForSingleObject(h, 0) != 0;
|
|
|
- CloseHandle(h);
|
|
|
- }
|
|
|
- return ret;
|
|
|
-#else
|
|
|
- for (;;) {
|
|
|
- int rc;
|
|
|
- struct flock lock_info;
|
|
|
- memset(&lock_info, 0, sizeof(lock_info));
|
|
|
- lock_info.l_type = F_WRLCK;
|
|
|
- lock_info.l_whence = SEEK_SET;
|
|
|
- lock_info.l_start = pid;
|
|
|
- lock_info.l_len = 1;
|
|
|
- if ((rc = fcntl(env->me_lfd, op, &lock_info)) == 0) {
|
|
|
- if (op == F_GETLK && lock_info.l_type != F_UNLCK)
|
|
|
- rc = -1;
|
|
|
- } else if ((rc = ErrCode()) == EINTR) {
|
|
|
- continue;
|
|
|
- }
|
|
|
- return rc;
|
|
|
- }
|
|
|
-#endif
|
|
|
-}
|
|
|
-
|
|
|
-/** Common code for #mdb_txn_begin() and #mdb_txn_renew().
|
|
|
- * @param[in] txn the transaction handle to initialize
|
|
|
- * @return 0 on success, non-zero on failure.
|
|
|
- */
|
|
|
-static int
|
|
|
-mdb_txn_renew0(MDB_txn *txn)
|
|
|
-{
|
|
|
- MDB_env *env = txn->mt_env;
|
|
|
- MDB_txninfo *ti = env->me_txns;
|
|
|
- MDB_meta *meta;
|
|
|
- unsigned int i, nr, flags = txn->mt_flags;
|
|
|
- uint16_t x;
|
|
|
- int rc, new_notls = 0;
|
|
|
-
|
|
|
- if ((flags &= MDB_TXN_RDONLY) != 0) {
|
|
|
- if (!ti) {
|
|
|
- meta = mdb_env_pick_meta(env);
|
|
|
- txn->mt_txnid = meta->mm_txnid;
|
|
|
- txn->mt_u.reader = NULL;
|
|
|
- } else {
|
|
|
- MDB_reader *r = (env->me_flags & MDB_NOTLS) ? txn->mt_u.reader :
|
|
|
- pthread_getspecific(env->me_txkey);
|
|
|
- if (r) {
|
|
|
- if (r->mr_pid != env->me_pid || r->mr_txnid != (txnid_t)-1)
|
|
|
- return MDB_BAD_RSLOT;
|
|
|
- } else {
|
|
|
- MDB_PID_T pid = env->me_pid;
|
|
|
- MDB_THR_T tid = pthread_self();
|
|
|
- mdb_mutexref_t rmutex = env->me_rmutex;
|
|
|
-
|
|
|
- if (!env->me_live_reader) {
|
|
|
- rc = mdb_reader_pid(env, Pidset, pid);
|
|
|
- if (rc)
|
|
|
- return rc;
|
|
|
- env->me_live_reader = 1;
|
|
|
- }
|
|
|
-
|
|
|
- if (LOCK_MUTEX(rc, env, rmutex))
|
|
|
- return rc;
|
|
|
- nr = ti->mti_numreaders;
|
|
|
- for (i=0; i<nr; i++)
|
|
|
- if (ti->mti_readers[i].mr_pid == 0)
|
|
|
- break;
|
|
|
- if (i == env->me_maxreaders) {
|
|
|
- UNLOCK_MUTEX(rmutex);
|
|
|
- return MDB_READERS_FULL;
|
|
|
- }
|
|
|
- r = &ti->mti_readers[i];
|
|
|
- /* Claim the reader slot, carefully since other code
|
|
|
- * uses the reader table un-mutexed: First reset the
|
|
|
- * slot, next publish it in mti_numreaders. After
|
|
|
- * that, it is safe for mdb_env_close() to touch it.
|
|
|
- * When it will be closed, we can finally claim it.
|
|
|
- */
|
|
|
- r->mr_pid = 0;
|
|
|
- r->mr_txnid = (txnid_t)-1;
|
|
|
- r->mr_tid = tid;
|
|
|
- if (i == nr)
|
|
|
- ti->mti_numreaders = ++nr;
|
|
|
- env->me_close_readers = nr;
|
|
|
- r->mr_pid = pid;
|
|
|
- UNLOCK_MUTEX(rmutex);
|
|
|
-
|
|
|
- new_notls = (env->me_flags & MDB_NOTLS);
|
|
|
- if (!new_notls && (rc=pthread_setspecific(env->me_txkey, r))) {
|
|
|
- r->mr_pid = 0;
|
|
|
- return rc;
|
|
|
- }
|
|
|
- }
|
|
|
- do /* LY: Retry on a race, ITS#7970. */
|
|
|
- r->mr_txnid = ti->mti_txnid;
|
|
|
- while(r->mr_txnid != ti->mti_txnid);
|
|
|
- txn->mt_txnid = r->mr_txnid;
|
|
|
- txn->mt_u.reader = r;
|
|
|
- meta = env->me_metas[txn->mt_txnid & 1];
|
|
|
- }
|
|
|
-
|
|
|
- } else {
|
|
|
- /* Not yet touching txn == env->me_txn0, it may be active */
|
|
|
- if (ti) {
|
|
|
- if (LOCK_MUTEX(rc, env, env->me_wmutex))
|
|
|
- return rc;
|
|
|
- txn->mt_txnid = ti->mti_txnid;
|
|
|
- meta = env->me_metas[txn->mt_txnid & 1];
|
|
|
- } else {
|
|
|
- meta = mdb_env_pick_meta(env);
|
|
|
- txn->mt_txnid = meta->mm_txnid;
|
|
|
- }
|
|
|
- txn->mt_txnid++;
|
|
|
-#if MDB_DEBUG
|
|
|
- if (txn->mt_txnid == mdb_debug_start)
|
|
|
- mdb_debug = 1;
|
|
|
-#endif
|
|
|
- txn->mt_child = NULL;
|
|
|
- txn->mt_loose_pgs = NULL;
|
|
|
- txn->mt_loose_count = 0;
|
|
|
- txn->mt_dirty_room = MDB_IDL_UM_MAX;
|
|
|
- txn->mt_u.dirty_list = env->me_dirty_list;
|
|
|
- txn->mt_u.dirty_list[0].mid = 0;
|
|
|
- txn->mt_free_pgs = env->me_free_pgs;
|
|
|
- txn->mt_free_pgs[0] = 0;
|
|
|
- txn->mt_spill_pgs = NULL;
|
|
|
- env->me_txn = txn;
|
|
|
- memcpy(txn->mt_dbiseqs, env->me_dbiseqs, env->me_maxdbs * sizeof(unsigned int));
|
|
|
- }
|
|
|
-
|
|
|
- /* Copy the DB info and flags */
|
|
|
- memcpy(txn->mt_dbs, meta->mm_dbs, CORE_DBS * sizeof(MDB_db));
|
|
|
-
|
|
|
- /* Moved to here to avoid a data race in read TXNs */
|
|
|
- txn->mt_next_pgno = meta->mm_last_pg+1;
|
|
|
-
|
|
|
- txn->mt_flags = flags;
|
|
|
-
|
|
|
- /* Setup db info */
|
|
|
- txn->mt_numdbs = env->me_numdbs;
|
|
|
- for (i=CORE_DBS; i<txn->mt_numdbs; i++) {
|
|
|
- x = env->me_dbflags[i];
|
|
|
- txn->mt_dbs[i].md_flags = x & PERSISTENT_FLAGS;
|
|
|
- txn->mt_dbflags[i] = (x & MDB_VALID) ? DB_VALID|DB_USRVALID|DB_STALE : 0;
|
|
|
- }
|
|
|
- txn->mt_dbflags[MAIN_DBI] = DB_VALID|DB_USRVALID;
|
|
|
- txn->mt_dbflags[FREE_DBI] = DB_VALID;
|
|
|
-
|
|
|
- if (env->me_flags & MDB_FATAL_ERROR) {
|
|
|
- DPUTS("environment had fatal error, must shutdown!");
|
|
|
- rc = MDB_PANIC;
|
|
|
- } else if (env->me_maxpg < txn->mt_next_pgno) {
|
|
|
- rc = MDB_MAP_RESIZED;
|
|
|
- } else {
|
|
|
- return MDB_SUCCESS;
|
|
|
- }
|
|
|
- mdb_txn_end(txn, new_notls /*0 or MDB_END_SLOT*/ | MDB_END_FAIL_BEGIN);
|
|
|
- return rc;
|
|
|
-}
|
|
|
-
|
|
|
-int
|
|
|
-mdb_txn_renew(MDB_txn *txn)
|
|
|
-{
|
|
|
- int rc;
|
|
|
-
|
|
|
- if (!txn || !F_ISSET(txn->mt_flags, MDB_TXN_RDONLY|MDB_TXN_FINISHED))
|
|
|
- return EINVAL;
|
|
|
-
|
|
|
- rc = mdb_txn_renew0(txn);
|
|
|
- if (rc == MDB_SUCCESS) {
|
|
|
- DPRINTF(("renew txn %"Z"u%c %p on mdbenv %p, root page %"Z"u",
|
|
|
- txn->mt_txnid, (txn->mt_flags & MDB_TXN_RDONLY) ? 'r' : 'w',
|
|
|
- (void *)txn, (void *)txn->mt_env, txn->mt_dbs[MAIN_DBI].md_root));
|
|
|
- }
|
|
|
- return rc;
|
|
|
-}
|
|
|
-
|
|
|
-int
|
|
|
-mdb_txn_begin(MDB_env *env, MDB_txn *parent, unsigned int flags, MDB_txn **ret)
|
|
|
-{
|
|
|
- MDB_txn *txn;
|
|
|
- MDB_ntxn *ntxn;
|
|
|
- int rc, size, tsize;
|
|
|
-
|
|
|
- flags &= MDB_TXN_BEGIN_FLAGS;
|
|
|
- flags |= env->me_flags & MDB_WRITEMAP;
|
|
|
-
|
|
|
- if (env->me_flags & MDB_RDONLY & ~flags) /* write txn in RDONLY env */
|
|
|
- return EACCES;
|
|
|
-
|
|
|
- if (parent) {
|
|
|
- /* Nested transactions: Max 1 child, write txns only, no writemap */
|
|
|
- flags |= parent->mt_flags;
|
|
|
- if (flags & (MDB_RDONLY|MDB_WRITEMAP|MDB_TXN_BLOCKED)) {
|
|
|
- return (parent->mt_flags & MDB_TXN_RDONLY) ? EINVAL : MDB_BAD_TXN;
|
|
|
- }
|
|
|
- /* Child txns save MDB_pgstate and use own copy of cursors */
|
|
|
- size = env->me_maxdbs * (sizeof(MDB_db)+sizeof(MDB_cursor *)+1);
|
|
|
- size += tsize = sizeof(MDB_ntxn);
|
|
|
- } else if (flags & MDB_RDONLY) {
|
|
|
- size = env->me_maxdbs * (sizeof(MDB_db)+1);
|
|
|
- size += tsize = sizeof(MDB_txn);
|
|
|
- } else {
|
|
|
- /* Reuse preallocated write txn. However, do not touch it until
|
|
|
- * mdb_txn_renew0() succeeds, since it currently may be active.
|
|
|
- */
|
|
|
- txn = env->me_txn0;
|
|
|
- goto renew;
|
|
|
- }
|
|
|
- if ((txn = calloc(1, size)) == NULL) {
|
|
|
- DPRINTF(("calloc: %s", strerror(errno)));
|
|
|
- return ENOMEM;
|
|
|
- }
|
|
|
- txn->mt_dbxs = env->me_dbxs; /* static */
|
|
|
- txn->mt_dbs = (MDB_db *) ((char *)txn + tsize);
|
|
|
- txn->mt_dbflags = (unsigned char *)txn + size - env->me_maxdbs;
|
|
|
- txn->mt_flags = flags;
|
|
|
- txn->mt_env = env;
|
|
|
-
|
|
|
- if (parent) {
|
|
|
- unsigned int i;
|
|
|
- txn->mt_cursors = (MDB_cursor **)(txn->mt_dbs + env->me_maxdbs);
|
|
|
- txn->mt_dbiseqs = parent->mt_dbiseqs;
|
|
|
- txn->mt_u.dirty_list = malloc(sizeof(MDB_ID2)*MDB_IDL_UM_SIZE);
|
|
|
- if (!txn->mt_u.dirty_list ||
|
|
|
- !(txn->mt_free_pgs = mdb_midl_alloc(MDB_IDL_UM_MAX)))
|
|
|
- {
|
|
|
- free(txn->mt_u.dirty_list);
|
|
|
- free(txn);
|
|
|
- return ENOMEM;
|
|
|
- }
|
|
|
- txn->mt_txnid = parent->mt_txnid;
|
|
|
- txn->mt_dirty_room = parent->mt_dirty_room;
|
|
|
- txn->mt_u.dirty_list[0].mid = 0;
|
|
|
- txn->mt_spill_pgs = NULL;
|
|
|
- txn->mt_next_pgno = parent->mt_next_pgno;
|
|
|
- parent->mt_flags |= MDB_TXN_HAS_CHILD;
|
|
|
- parent->mt_child = txn;
|
|
|
- txn->mt_parent = parent;
|
|
|
- txn->mt_numdbs = parent->mt_numdbs;
|
|
|
- memcpy(txn->mt_dbs, parent->mt_dbs, txn->mt_numdbs * sizeof(MDB_db));
|
|
|
- /* Copy parent's mt_dbflags, but clear DB_NEW */
|
|
|
- for (i=0; i<txn->mt_numdbs; i++)
|
|
|
- txn->mt_dbflags[i] = parent->mt_dbflags[i] & ~DB_NEW;
|
|
|
- rc = 0;
|
|
|
- ntxn = (MDB_ntxn *)txn;
|
|
|
- ntxn->mnt_pgstate = env->me_pgstate; /* save parent me_pghead & co */
|
|
|
- if (env->me_pghead) {
|
|
|
- size = MDB_IDL_SIZEOF(env->me_pghead);
|
|
|
- env->me_pghead = mdb_midl_alloc(env->me_pghead[0]);
|
|
|
- if (env->me_pghead)
|
|
|
- memcpy(env->me_pghead, ntxn->mnt_pgstate.mf_pghead, size);
|
|
|
- else
|
|
|
- rc = ENOMEM;
|
|
|
- }
|
|
|
- if (!rc)
|
|
|
- rc = mdb_cursor_shadow(parent, txn);
|
|
|
- if (rc)
|
|
|
- mdb_txn_end(txn, MDB_END_FAIL_BEGINCHILD);
|
|
|
- } else { /* MDB_RDONLY */
|
|
|
- txn->mt_dbiseqs = env->me_dbiseqs;
|
|
|
-renew:
|
|
|
- rc = mdb_txn_renew0(txn);
|
|
|
- }
|
|
|
- if (rc) {
|
|
|
- if (txn != env->me_txn0)
|
|
|
- free(txn);
|
|
|
- } else {
|
|
|
- txn->mt_flags |= flags; /* could not change txn=me_txn0 earlier */
|
|
|
- *ret = txn;
|
|
|
- DPRINTF(("begin txn %"Z"u%c %p on mdbenv %p, root page %"Z"u",
|
|
|
- txn->mt_txnid, (flags & MDB_RDONLY) ? 'r' : 'w',
|
|
|
- (void *) txn, (void *) env, txn->mt_dbs[MAIN_DBI].md_root));
|
|
|
- }
|
|
|
-
|
|
|
- return rc;
|
|
|
-}
|
|
|
-
|
|
|
-MDB_env *
|
|
|
-mdb_txn_env(MDB_txn *txn)
|
|
|
-{
|
|
|
- if(!txn) return NULL;
|
|
|
- return txn->mt_env;
|
|
|
-}
|
|
|
-
|
|
|
-size_t
|
|
|
-mdb_txn_id(MDB_txn *txn)
|
|
|
-{
|
|
|
- if(!txn) return 0;
|
|
|
- return txn->mt_txnid;
|
|
|
-}
|
|
|
-
|
|
|
-/** Export or close DBI handles opened in this txn. */
|
|
|
-static void
|
|
|
-mdb_dbis_update(MDB_txn *txn, int keep)
|
|
|
-{
|
|
|
- int i;
|
|
|
- MDB_dbi n = txn->mt_numdbs;
|
|
|
- MDB_env *env = txn->mt_env;
|
|
|
- unsigned char *tdbflags = txn->mt_dbflags;
|
|
|
-
|
|
|
- for (i = n; --i >= CORE_DBS;) {
|
|
|
- if (tdbflags[i] & DB_NEW) {
|
|
|
- if (keep) {
|
|
|
- env->me_dbflags[i] = txn->mt_dbs[i].md_flags | MDB_VALID;
|
|
|
- } else {
|
|
|
- char *ptr = env->me_dbxs[i].md_name.mv_data;
|
|
|
- if (ptr) {
|
|
|
- env->me_dbxs[i].md_name.mv_data = NULL;
|
|
|
- env->me_dbxs[i].md_name.mv_size = 0;
|
|
|
- env->me_dbflags[i] = 0;
|
|
|
- env->me_dbiseqs[i]++;
|
|
|
- free(ptr);
|
|
|
- }
|
|
|
- }
|
|
|
- }
|
|
|
- }
|
|
|
- if (keep && env->me_numdbs < n)
|
|
|
- env->me_numdbs = n;
|
|
|
-}
|
|
|
-
|
|
|
-/** End a transaction, except successful commit of a nested transaction.
|
|
|
- * May be called twice for readonly txns: First reset it, then abort.
|
|
|
- * @param[in] txn the transaction handle to end
|
|
|
- * @param[in] mode why and how to end the transaction
|
|
|
- */
|
|
|
-static void
|
|
|
-mdb_txn_end(MDB_txn *txn, unsigned mode)
|
|
|
-{
|
|
|
- MDB_env *env = txn->mt_env;
|
|
|
-#if MDB_DEBUG
|
|
|
- static const char *const names[] = MDB_END_NAMES;
|
|
|
-#endif
|
|
|
-
|
|
|
- /* Export or close DBI handles opened in this txn */
|
|
|
- mdb_dbis_update(txn, mode & MDB_END_UPDATE);
|
|
|
-
|
|
|
- DPRINTF(("%s txn %"Z"u%c %p on mdbenv %p, root page %"Z"u",
|
|
|
- names[mode & MDB_END_OPMASK],
|
|
|
- txn->mt_txnid, (txn->mt_flags & MDB_TXN_RDONLY) ? 'r' : 'w',
|
|
|
- (void *) txn, (void *)env, txn->mt_dbs[MAIN_DBI].md_root));
|
|
|
-
|
|
|
- if (F_ISSET(txn->mt_flags, MDB_TXN_RDONLY)) {
|
|
|
- if (txn->mt_u.reader) {
|
|
|
- txn->mt_u.reader->mr_txnid = (txnid_t)-1;
|
|
|
- if (!(env->me_flags & MDB_NOTLS)) {
|
|
|
- txn->mt_u.reader = NULL; /* txn does not own reader */
|
|
|
- } else if (mode & MDB_END_SLOT) {
|
|
|
- txn->mt_u.reader->mr_pid = 0;
|
|
|
- txn->mt_u.reader = NULL;
|
|
|
- } /* else txn owns the slot until it does MDB_END_SLOT */
|
|
|
- }
|
|
|
- txn->mt_numdbs = 0; /* prevent further DBI activity */
|
|
|
- txn->mt_flags |= MDB_TXN_FINISHED;
|
|
|
-
|
|
|
- } else if (!F_ISSET(txn->mt_flags, MDB_TXN_FINISHED)) {
|
|
|
- pgno_t *pghead = env->me_pghead;
|
|
|
-
|
|
|
- if (!(mode & MDB_END_UPDATE)) /* !(already closed cursors) */
|
|
|
- mdb_cursors_close(txn, 0);
|
|
|
- if (!(env->me_flags & MDB_WRITEMAP)) {
|
|
|
- mdb_dlist_free(txn);
|
|
|
- }
|
|
|
-
|
|
|
- txn->mt_numdbs = 0;
|
|
|
- txn->mt_flags = MDB_TXN_FINISHED;
|
|
|
-
|
|
|
- if (!txn->mt_parent) {
|
|
|
- mdb_midl_shrink(&txn->mt_free_pgs);
|
|
|
- env->me_free_pgs = txn->mt_free_pgs;
|
|
|
- /* me_pgstate: */
|
|
|
- env->me_pghead = NULL;
|
|
|
- env->me_pglast = 0;
|
|
|
-
|
|
|
- env->me_txn = NULL;
|
|
|
- mode = 0; /* txn == env->me_txn0, do not free() it */
|
|
|
-
|
|
|
- /* The writer mutex was locked in mdb_txn_begin. */
|
|
|
- if (env->me_txns)
|
|
|
- UNLOCK_MUTEX(env->me_wmutex);
|
|
|
- } else {
|
|
|
- txn->mt_parent->mt_child = NULL;
|
|
|
- txn->mt_parent->mt_flags &= ~MDB_TXN_HAS_CHILD;
|
|
|
- env->me_pgstate = ((MDB_ntxn *)txn)->mnt_pgstate;
|
|
|
- mdb_midl_free(txn->mt_free_pgs);
|
|
|
- mdb_midl_free(txn->mt_spill_pgs);
|
|
|
- free(txn->mt_u.dirty_list);
|
|
|
- }
|
|
|
-
|
|
|
- mdb_midl_free(pghead);
|
|
|
- }
|
|
|
-
|
|
|
- if (mode & MDB_END_FREE)
|
|
|
- free(txn);
|
|
|
-}
|
|
|
-
|
|
|
-void
|
|
|
-mdb_txn_reset(MDB_txn *txn)
|
|
|
-{
|
|
|
- if (txn == NULL)
|
|
|
- return;
|
|
|
-
|
|
|
- /* This call is only valid for read-only txns */
|
|
|
- if (!(txn->mt_flags & MDB_TXN_RDONLY))
|
|
|
- return;
|
|
|
-
|
|
|
- mdb_txn_end(txn, MDB_END_RESET);
|
|
|
-}
|
|
|
-
|
|
|
-void
|
|
|
-mdb_txn_abort(MDB_txn *txn)
|
|
|
-{
|
|
|
- if (txn == NULL)
|
|
|
- return;
|
|
|
-
|
|
|
- if (txn->mt_child)
|
|
|
- mdb_txn_abort(txn->mt_child);
|
|
|
-
|
|
|
- mdb_txn_end(txn, MDB_END_ABORT|MDB_END_SLOT|MDB_END_FREE);
|
|
|
-}
|
|
|
-
|
|
|
-/** Save the freelist as of this transaction to the freeDB.
|
|
|
- * This changes the freelist. Keep trying until it stabilizes.
|
|
|
- */
|
|
|
-static int
|
|
|
-mdb_freelist_save(MDB_txn *txn)
|
|
|
-{
|
|
|
- /* env->me_pghead[] can grow and shrink during this call.
|
|
|
- * env->me_pglast and txn->mt_free_pgs[] can only grow.
|
|
|
- * Page numbers cannot disappear from txn->mt_free_pgs[].
|
|
|
- */
|
|
|
- MDB_cursor mc;
|
|
|
- MDB_env *env = txn->mt_env;
|
|
|
- int rc, maxfree_1pg = env->me_maxfree_1pg, more = 1;
|
|
|
- txnid_t pglast = 0, head_id = 0;
|
|
|
- pgno_t freecnt = 0, *free_pgs, *mop;
|
|
|
- ssize_t head_room = 0, total_room = 0, mop_len, clean_limit;
|
|
|
-
|
|
|
- mdb_cursor_init(&mc, txn, FREE_DBI, NULL);
|
|
|
-
|
|
|
- if (env->me_pghead) {
|
|
|
- /* Make sure first page of freeDB is touched and on freelist */
|
|
|
- rc = mdb_page_search(&mc, NULL, MDB_PS_FIRST|MDB_PS_MODIFY);
|
|
|
- if (rc && rc != MDB_NOTFOUND)
|
|
|
- return rc;
|
|
|
- }
|
|
|
-
|
|
|
- if (!env->me_pghead && txn->mt_loose_pgs) {
|
|
|
- /* Put loose page numbers in mt_free_pgs, since
|
|
|
- * we may be unable to return them to me_pghead.
|
|
|
- */
|
|
|
- MDB_page *mp = txn->mt_loose_pgs;
|
|
|
- if ((rc = mdb_midl_need(&txn->mt_free_pgs, txn->mt_loose_count)) != 0)
|
|
|
- return rc;
|
|
|
- for (; mp; mp = NEXT_LOOSE_PAGE(mp))
|
|
|
- mdb_midl_xappend(txn->mt_free_pgs, mp->mp_pgno);
|
|
|
- txn->mt_loose_pgs = NULL;
|
|
|
- txn->mt_loose_count = 0;
|
|
|
- }
|
|
|
-
|
|
|
- /* MDB_RESERVE cancels meminit in ovpage malloc (when no WRITEMAP) */
|
|
|
- clean_limit = (env->me_flags & (MDB_NOMEMINIT|MDB_WRITEMAP))
|
|
|
- ? SSIZE_MAX : maxfree_1pg;
|
|
|
-
|
|
|
- for (;;) {
|
|
|
- /* Come back here after each Put() in case freelist changed */
|
|
|
- MDB_val key, data;
|
|
|
- pgno_t *pgs;
|
|
|
- ssize_t j;
|
|
|
-
|
|
|
- /* If using records from freeDB which we have not yet
|
|
|
- * deleted, delete them and any we reserved for me_pghead.
|
|
|
- */
|
|
|
- while (pglast < env->me_pglast) {
|
|
|
- rc = mdb_cursor_first(&mc, &key, NULL);
|
|
|
- if (rc)
|
|
|
- return rc;
|
|
|
- pglast = head_id = *(txnid_t *)key.mv_data;
|
|
|
- total_room = head_room = 0;
|
|
|
- mdb_tassert(txn, pglast <= env->me_pglast);
|
|
|
- rc = mdb_cursor_del(&mc, 0);
|
|
|
- if (rc)
|
|
|
- return rc;
|
|
|
- }
|
|
|
-
|
|
|
- /* Save the IDL of pages freed by this txn, to a single record */
|
|
|
- if (freecnt < txn->mt_free_pgs[0]) {
|
|
|
- if (!freecnt) {
|
|
|
- /* Make sure last page of freeDB is touched and on freelist */
|
|
|
- rc = mdb_page_search(&mc, NULL, MDB_PS_LAST|MDB_PS_MODIFY);
|
|
|
- if (rc && rc != MDB_NOTFOUND)
|
|
|
- return rc;
|
|
|
- }
|
|
|
- free_pgs = txn->mt_free_pgs;
|
|
|
- /* Write to last page of freeDB */
|
|
|
- key.mv_size = sizeof(txn->mt_txnid);
|
|
|
- key.mv_data = &txn->mt_txnid;
|
|
|
- do {
|
|
|
- freecnt = free_pgs[0];
|
|
|
- data.mv_size = MDB_IDL_SIZEOF(free_pgs);
|
|
|
- rc = mdb_cursor_put(&mc, &key, &data, MDB_RESERVE);
|
|
|
- if (rc)
|
|
|
- return rc;
|
|
|
- /* Retry if mt_free_pgs[] grew during the Put() */
|
|
|
- free_pgs = txn->mt_free_pgs;
|
|
|
- } while (freecnt < free_pgs[0]);
|
|
|
- mdb_midl_sort(free_pgs);
|
|
|
- memcpy(data.mv_data, free_pgs, data.mv_size);
|
|
|
-#if (MDB_DEBUG) > 1
|
|
|
- {
|
|
|
- unsigned int i = free_pgs[0];
|
|
|
- DPRINTF(("IDL write txn %"Z"u root %"Z"u num %u",
|
|
|
- txn->mt_txnid, txn->mt_dbs[FREE_DBI].md_root, i));
|
|
|
- for (; i; i--)
|
|
|
- DPRINTF(("IDL %"Z"u", free_pgs[i]));
|
|
|
- }
|
|
|
-#endif
|
|
|
- continue;
|
|
|
- }
|
|
|
-
|
|
|
- mop = env->me_pghead;
|
|
|
- mop_len = (mop ? mop[0] : 0) + txn->mt_loose_count;
|
|
|
-
|
|
|
- /* Reserve records for me_pghead[]. Split it if multi-page,
|
|
|
- * to avoid searching freeDB for a page range. Use keys in
|
|
|
- * range [1,me_pglast]: Smaller than txnid of oldest reader.
|
|
|
- */
|
|
|
- if (total_room >= mop_len) {
|
|
|
- if (total_room == mop_len || --more < 0)
|
|
|
- break;
|
|
|
- } else if (head_room >= maxfree_1pg && head_id > 1) {
|
|
|
- /* Keep current record (overflow page), add a new one */
|
|
|
- head_id--;
|
|
|
- head_room = 0;
|
|
|
- }
|
|
|
- /* (Re)write {key = head_id, IDL length = head_room} */
|
|
|
- total_room -= head_room;
|
|
|
- head_room = mop_len - total_room;
|
|
|
- if (head_room > maxfree_1pg && head_id > 1) {
|
|
|
- /* Overflow multi-page for part of me_pghead */
|
|
|
- head_room /= head_id; /* amortize page sizes */
|
|
|
- head_room += maxfree_1pg - head_room % (maxfree_1pg + 1);
|
|
|
- } else if (head_room < 0) {
|
|
|
- /* Rare case, not bothering to delete this record */
|
|
|
- head_room = 0;
|
|
|
- }
|
|
|
- key.mv_size = sizeof(head_id);
|
|
|
- key.mv_data = &head_id;
|
|
|
- data.mv_size = (head_room + 1) * sizeof(pgno_t);
|
|
|
- rc = mdb_cursor_put(&mc, &key, &data, MDB_RESERVE);
|
|
|
- if (rc)
|
|
|
- return rc;
|
|
|
- /* IDL is initially empty, zero out at least the length */
|
|
|
- pgs = (pgno_t *)data.mv_data;
|
|
|
- j = head_room > clean_limit ? head_room : 0;
|
|
|
- do {
|
|
|
- pgs[j] = 0;
|
|
|
- } while (--j >= 0);
|
|
|
- total_room += head_room;
|
|
|
- }
|
|
|
-
|
|
|
- /* Return loose page numbers to me_pghead, though usually none are
|
|
|
- * left at this point. The pages themselves remain in dirty_list.
|
|
|
- */
|
|
|
- if (txn->mt_loose_pgs) {
|
|
|
- MDB_page *mp = txn->mt_loose_pgs;
|
|
|
- unsigned count = txn->mt_loose_count;
|
|
|
- MDB_IDL loose;
|
|
|
- /* Room for loose pages + temp IDL with same */
|
|
|
- if ((rc = mdb_midl_need(&env->me_pghead, 2*count+1)) != 0)
|
|
|
- return rc;
|
|
|
- mop = env->me_pghead;
|
|
|
- loose = mop + MDB_IDL_ALLOCLEN(mop) - count;
|
|
|
- for (count = 0; mp; mp = NEXT_LOOSE_PAGE(mp))
|
|
|
- loose[ ++count ] = mp->mp_pgno;
|
|
|
- loose[0] = count;
|
|
|
- mdb_midl_sort(loose);
|
|
|
- mdb_midl_xmerge(mop, loose);
|
|
|
- txn->mt_loose_pgs = NULL;
|
|
|
- txn->mt_loose_count = 0;
|
|
|
- mop_len = mop[0];
|
|
|
- }
|
|
|
-
|
|
|
- /* Fill in the reserved me_pghead records */
|
|
|
- rc = MDB_SUCCESS;
|
|
|
- if (mop_len) {
|
|
|
- MDB_val key, data;
|
|
|
-
|
|
|
- mop += mop_len;
|
|
|
- rc = mdb_cursor_first(&mc, &key, &data);
|
|
|
- for (; !rc; rc = mdb_cursor_next(&mc, &key, &data, MDB_NEXT)) {
|
|
|
- txnid_t id = *(txnid_t *)key.mv_data;
|
|
|
- ssize_t len = (ssize_t)(data.mv_size / sizeof(MDB_ID)) - 1;
|
|
|
- MDB_ID save;
|
|
|
-
|
|
|
- mdb_tassert(txn, len >= 0 && id <= env->me_pglast);
|
|
|
- key.mv_data = &id;
|
|
|
- if (len > mop_len) {
|
|
|
- len = mop_len;
|
|
|
- data.mv_size = (len + 1) * sizeof(MDB_ID);
|
|
|
- }
|
|
|
- data.mv_data = mop -= len;
|
|
|
- save = mop[0];
|
|
|
- mop[0] = len;
|
|
|
- rc = mdb_cursor_put(&mc, &key, &data, MDB_CURRENT);
|
|
|
- mop[0] = save;
|
|
|
- if (rc || !(mop_len -= len))
|
|
|
- break;
|
|
|
- }
|
|
|
- }
|
|
|
- return rc;
|
|
|
-}
|
|
|
-
|
|
|
-/** Flush (some) dirty pages to the map, after clearing their dirty flag.
|
|
|
- * @param[in] txn the transaction that's being committed
|
|
|
- * @param[in] keep number of initial pages in dirty_list to keep dirty.
|
|
|
- * @return 0 on success, non-zero on failure.
|
|
|
- */
|
|
|
-static int
|
|
|
-mdb_page_flush(MDB_txn *txn, int keep)
|
|
|
-{
|
|
|
- MDB_env *env = txn->mt_env;
|
|
|
- MDB_ID2L dl = txn->mt_u.dirty_list;
|
|
|
- unsigned psize = env->me_psize, j;
|
|
|
- int i, pagecount = dl[0].mid, rc;
|
|
|
- size_t size = 0, pos = 0;
|
|
|
- pgno_t pgno = 0;
|
|
|
- MDB_page *dp = NULL;
|
|
|
-#ifdef _WIN32
|
|
|
- OVERLAPPED ov;
|
|
|
-#else
|
|
|
- struct iovec iov[MDB_COMMIT_PAGES];
|
|
|
- ssize_t wpos = 0, wsize = 0, wres;
|
|
|
- size_t next_pos = 1; /* impossible pos, so pos != next_pos */
|
|
|
- int n = 0;
|
|
|
-#endif
|
|
|
-
|
|
|
- j = i = keep;
|
|
|
-
|
|
|
- if (env->me_flags & MDB_WRITEMAP) {
|
|
|
- /* Clear dirty flags */
|
|
|
- while (++i <= pagecount) {
|
|
|
- dp = dl[i].mptr;
|
|
|
- /* Don't flush this page yet */
|
|
|
- if (dp->mp_flags & (P_LOOSE|P_KEEP)) {
|
|
|
- dp->mp_flags &= ~P_KEEP;
|
|
|
- dl[++j] = dl[i];
|
|
|
- continue;
|
|
|
- }
|
|
|
- dp->mp_flags &= ~P_DIRTY;
|
|
|
- }
|
|
|
- goto done;
|
|
|
- }
|
|
|
-
|
|
|
- /* Write the pages */
|
|
|
- for (;;) {
|
|
|
- if (++i <= pagecount) {
|
|
|
- dp = dl[i].mptr;
|
|
|
- /* Don't flush this page yet */
|
|
|
- if (dp->mp_flags & (P_LOOSE|P_KEEP)) {
|
|
|
- dp->mp_flags &= ~P_KEEP;
|
|
|
- dl[i].mid = 0;
|
|
|
- continue;
|
|
|
- }
|
|
|
- pgno = dl[i].mid;
|
|
|
- /* clear dirty flag */
|
|
|
- dp->mp_flags &= ~P_DIRTY;
|
|
|
- pos = pgno * psize;
|
|
|
- size = psize;
|
|
|
- if (IS_OVERFLOW(dp)) size *= dp->mp_pages;
|
|
|
- }
|
|
|
-#ifdef _WIN32
|
|
|
- else break;
|
|
|
-
|
|
|
- /* Windows actually supports scatter/gather I/O, but only on
|
|
|
- * unbuffered file handles. Since we're relying on the OS page
|
|
|
- * cache for all our data, that's self-defeating. So we just
|
|
|
- * write pages one at a time. We use the ov structure to set
|
|
|
- * the write offset, to at least save the overhead of a Seek
|
|
|
- * system call.
|
|
|
- */
|
|
|
- DPRINTF(("committing page %"Z"u", pgno));
|
|
|
- memset(&ov, 0, sizeof(ov));
|
|
|
- ov.Offset = pos & 0xffffffff;
|
|
|
- ov.OffsetHigh = pos >> 16 >> 16;
|
|
|
- if (!WriteFile(env->me_fd, dp, size, NULL, &ov)) {
|
|
|
- rc = ErrCode();
|
|
|
- DPRINTF(("WriteFile: %d", rc));
|
|
|
- return rc;
|
|
|
- }
|
|
|
-#else
|
|
|
- /* Write up to MDB_COMMIT_PAGES dirty pages at a time. */
|
|
|
- if (pos!=next_pos || n==MDB_COMMIT_PAGES || wsize+size>MAX_WRITE) {
|
|
|
- if (n) {
|
|
|
-retry_write:
|
|
|
- /* Write previous page(s) */
|
|
|
-#ifdef MDB_USE_PWRITEV
|
|
|
- wres = pwritev(env->me_fd, iov, n, wpos);
|
|
|
-#else
|
|
|
- if (n == 1) {
|
|
|
- wres = pwrite(env->me_fd, iov[0].iov_base, wsize, wpos);
|
|
|
- } else {
|
|
|
-retry_seek:
|
|
|
- if (lseek(env->me_fd, wpos, SEEK_SET) == -1) {
|
|
|
- rc = ErrCode();
|
|
|
- if (rc == EINTR)
|
|
|
- goto retry_seek;
|
|
|
- DPRINTF(("lseek: %s", strerror(rc)));
|
|
|
- return rc;
|
|
|
- }
|
|
|
- wres = writev(env->me_fd, iov, n);
|
|
|
- }
|
|
|
-#endif
|
|
|
- if (wres != wsize) {
|
|
|
- if (wres < 0) {
|
|
|
- rc = ErrCode();
|
|
|
- if (rc == EINTR)
|
|
|
- goto retry_write;
|
|
|
- DPRINTF(("Write error: %s", strerror(rc)));
|
|
|
- } else {
|
|
|
- rc = EIO; /* TODO: Use which error code? */
|
|
|
- DPUTS("short write, filesystem full?");
|
|
|
- }
|
|
|
- return rc;
|
|
|
- }
|
|
|
- n = 0;
|
|
|
- }
|
|
|
- if (i > pagecount)
|
|
|
- break;
|
|
|
- wpos = pos;
|
|
|
- wsize = 0;
|
|
|
- }
|
|
|
- DPRINTF(("committing page %"Z"u", pgno));
|
|
|
- next_pos = pos + size;
|
|
|
- iov[n].iov_len = size;
|
|
|
- iov[n].iov_base = (char *)dp;
|
|
|
- wsize += size;
|
|
|
- n++;
|
|
|
-#endif /* _WIN32 */
|
|
|
- }
|
|
|
-
|
|
|
- /* MIPS has cache coherency issues, this is a no-op everywhere else
|
|
|
- * Note: for any size >= on-chip cache size, entire on-chip cache is
|
|
|
- * flushed.
|
|
|
- */
|
|
|
- CACHEFLUSH(env->me_map, txn->mt_next_pgno * env->me_psize, DCACHE);
|
|
|
-
|
|
|
- for (i = keep; ++i <= pagecount; ) {
|
|
|
- dp = dl[i].mptr;
|
|
|
- /* This is a page we skipped above */
|
|
|
- if (!dl[i].mid) {
|
|
|
- dl[++j] = dl[i];
|
|
|
- dl[j].mid = dp->mp_pgno;
|
|
|
- continue;
|
|
|
- }
|
|
|
- mdb_dpage_free(env, dp);
|
|
|
- }
|
|
|
-
|
|
|
-done:
|
|
|
- i--;
|
|
|
- txn->mt_dirty_room += i - j;
|
|
|
- dl[0].mid = j;
|
|
|
- return MDB_SUCCESS;
|
|
|
-}
|
|
|
-
|
|
|
-int
|
|
|
-mdb_txn_commit(MDB_txn *txn)
|
|
|
-{
|
|
|
- int rc;
|
|
|
- unsigned int i, end_mode;
|
|
|
- MDB_env *env;
|
|
|
-
|
|
|
- if (txn == NULL)
|
|
|
- return EINVAL;
|
|
|
-
|
|
|
- /* mdb_txn_end() mode for a commit which writes nothing */
|
|
|
- end_mode = MDB_END_EMPTY_COMMIT|MDB_END_UPDATE|MDB_END_SLOT|MDB_END_FREE;
|
|
|
-
|
|
|
- if (txn->mt_child) {
|
|
|
- rc = mdb_txn_commit(txn->mt_child);
|
|
|
- if (rc)
|
|
|
- goto fail;
|
|
|
- }
|
|
|
-
|
|
|
- env = txn->mt_env;
|
|
|
-
|
|
|
- if (F_ISSET(txn->mt_flags, MDB_TXN_RDONLY)) {
|
|
|
- goto done;
|
|
|
- }
|
|
|
-
|
|
|
- if (txn->mt_flags & (MDB_TXN_FINISHED|MDB_TXN_ERROR)) {
|
|
|
- DPUTS("txn has failed/finished, can't commit");
|
|
|
- if (txn->mt_parent)
|
|
|
- txn->mt_parent->mt_flags |= MDB_TXN_ERROR;
|
|
|
- rc = MDB_BAD_TXN;
|
|
|
- goto fail;
|
|
|
- }
|
|
|
-
|
|
|
- if (txn->mt_parent) {
|
|
|
- MDB_txn *parent = txn->mt_parent;
|
|
|
- MDB_page **lp;
|
|
|
- MDB_ID2L dst, src;
|
|
|
- MDB_IDL pspill;
|
|
|
- unsigned x, y, len, ps_len;
|
|
|
-
|
|
|
- /* Append our free list to parent's */
|
|
|
- rc = mdb_midl_append_list(&parent->mt_free_pgs, txn->mt_free_pgs);
|
|
|
- if (rc)
|
|
|
- goto fail;
|
|
|
- mdb_midl_free(txn->mt_free_pgs);
|
|
|
- /* Failures after this must either undo the changes
|
|
|
- * to the parent or set MDB_TXN_ERROR in the parent.
|
|
|
- */
|
|
|
-
|
|
|
- parent->mt_next_pgno = txn->mt_next_pgno;
|
|
|
- parent->mt_flags = txn->mt_flags;
|
|
|
-
|
|
|
- /* Merge our cursors into parent's and close them */
|
|
|
- mdb_cursors_close(txn, 1);
|
|
|
-
|
|
|
- /* Update parent's DB table. */
|
|
|
- memcpy(parent->mt_dbs, txn->mt_dbs, txn->mt_numdbs * sizeof(MDB_db));
|
|
|
- parent->mt_numdbs = txn->mt_numdbs;
|
|
|
- parent->mt_dbflags[FREE_DBI] = txn->mt_dbflags[FREE_DBI];
|
|
|
- parent->mt_dbflags[MAIN_DBI] = txn->mt_dbflags[MAIN_DBI];
|
|
|
- for (i=CORE_DBS; i<txn->mt_numdbs; i++) {
|
|
|
- /* preserve parent's DB_NEW status */
|
|
|
- x = parent->mt_dbflags[i] & DB_NEW;
|
|
|
- parent->mt_dbflags[i] = txn->mt_dbflags[i] | x;
|
|
|
- }
|
|
|
-
|
|
|
- dst = parent->mt_u.dirty_list;
|
|
|
- src = txn->mt_u.dirty_list;
|
|
|
- /* Remove anything in our dirty list from parent's spill list */
|
|
|
- if ((pspill = parent->mt_spill_pgs) && (ps_len = pspill[0])) {
|
|
|
- x = y = ps_len;
|
|
|
- pspill[0] = (pgno_t)-1;
|
|
|
- /* Mark our dirty pages as deleted in parent spill list */
|
|
|
- for (i=0, len=src[0].mid; ++i <= len; ) {
|
|
|
- MDB_ID pn = src[i].mid << 1;
|
|
|
- while (pn > pspill[x])
|
|
|
- x--;
|
|
|
- if (pn == pspill[x]) {
|
|
|
- pspill[x] = 1;
|
|
|
- y = --x;
|
|
|
- }
|
|
|
- }
|
|
|
- /* Squash deleted pagenums if we deleted any */
|
|
|
- for (x=y; ++x <= ps_len; )
|
|
|
- if (!(pspill[x] & 1))
|
|
|
- pspill[++y] = pspill[x];
|
|
|
- pspill[0] = y;
|
|
|
- }
|
|
|
-
|
|
|
- /* Remove anything in our spill list from parent's dirty list */
|
|
|
- if (txn->mt_spill_pgs && txn->mt_spill_pgs[0]) {
|
|
|
- for (i=1; i<=txn->mt_spill_pgs[0]; i++) {
|
|
|
- MDB_ID pn = txn->mt_spill_pgs[i];
|
|
|
- if (pn & 1)
|
|
|
- continue; /* deleted spillpg */
|
|
|
- pn >>= 1;
|
|
|
- y = mdb_mid2l_search(dst, pn);
|
|
|
- if (y <= dst[0].mid && dst[y].mid == pn) {
|
|
|
- free(dst[y].mptr);
|
|
|
- while (y < dst[0].mid) {
|
|
|
- dst[y] = dst[y+1];
|
|
|
- y++;
|
|
|
- }
|
|
|
- dst[0].mid--;
|
|
|
- }
|
|
|
- }
|
|
|
- }
|
|
|
-
|
|
|
- /* Find len = length of merging our dirty list with parent's */
|
|
|
- x = dst[0].mid;
|
|
|
- dst[0].mid = 0; /* simplify loops */
|
|
|
- if (parent->mt_parent) {
|
|
|
- len = x + src[0].mid;
|
|
|
- y = mdb_mid2l_search(src, dst[x].mid + 1) - 1;
|
|
|
- for (i = x; y && i; y--) {
|
|
|
- pgno_t yp = src[y].mid;
|
|
|
- while (yp < dst[i].mid)
|
|
|
- i--;
|
|
|
- if (yp == dst[i].mid) {
|
|
|
- i--;
|
|
|
- len--;
|
|
|
- }
|
|
|
- }
|
|
|
- } else { /* Simplify the above for single-ancestor case */
|
|
|
- len = MDB_IDL_UM_MAX - txn->mt_dirty_room;
|
|
|
- }
|
|
|
- /* Merge our dirty list with parent's */
|
|
|
- y = src[0].mid;
|
|
|
- for (i = len; y; dst[i--] = src[y--]) {
|
|
|
- pgno_t yp = src[y].mid;
|
|
|
- while (yp < dst[x].mid)
|
|
|
- dst[i--] = dst[x--];
|
|
|
- if (yp == dst[x].mid)
|
|
|
- free(dst[x--].mptr);
|
|
|
- }
|
|
|
- mdb_tassert(txn, i == x);
|
|
|
- dst[0].mid = len;
|
|
|
- free(txn->mt_u.dirty_list);
|
|
|
- parent->mt_dirty_room = txn->mt_dirty_room;
|
|
|
- if (txn->mt_spill_pgs) {
|
|
|
- if (parent->mt_spill_pgs) {
|
|
|
- /* TODO: Prevent failure here, so parent does not fail */
|
|
|
- rc = mdb_midl_append_list(&parent->mt_spill_pgs, txn->mt_spill_pgs);
|
|
|
- if (rc)
|
|
|
- parent->mt_flags |= MDB_TXN_ERROR;
|
|
|
- mdb_midl_free(txn->mt_spill_pgs);
|
|
|
- mdb_midl_sort(parent->mt_spill_pgs);
|
|
|
- } else {
|
|
|
- parent->mt_spill_pgs = txn->mt_spill_pgs;
|
|
|
- }
|
|
|
- }
|
|
|
-
|
|
|
- /* Append our loose page list to parent's */
|
|
|
- for (lp = &parent->mt_loose_pgs; *lp; lp = &NEXT_LOOSE_PAGE(*lp))
|
|
|
- ;
|
|
|
- *lp = txn->mt_loose_pgs;
|
|
|
- parent->mt_loose_count += txn->mt_loose_count;
|
|
|
-
|
|
|
- parent->mt_child = NULL;
|
|
|
- mdb_midl_free(((MDB_ntxn *)txn)->mnt_pgstate.mf_pghead);
|
|
|
- free(txn);
|
|
|
- return rc;
|
|
|
- }
|
|
|
-
|
|
|
- if (txn != env->me_txn) {
|
|
|
- DPUTS("attempt to commit unknown transaction");
|
|
|
- rc = EINVAL;
|
|
|
- goto fail;
|
|
|
- }
|
|
|
-
|
|
|
- mdb_cursors_close(txn, 0);
|
|
|
-
|
|
|
- if (!txn->mt_u.dirty_list[0].mid &&
|
|
|
- !(txn->mt_flags & (MDB_TXN_DIRTY|MDB_TXN_SPILLS)))
|
|
|
- goto done;
|
|
|
-
|
|
|
- DPRINTF(("committing txn %"Z"u %p on mdbenv %p, root page %"Z"u",
|
|
|
- txn->mt_txnid, (void*)txn, (void*)env, txn->mt_dbs[MAIN_DBI].md_root));
|
|
|
-
|
|
|
- /* Update DB root pointers */
|
|
|
- if (txn->mt_numdbs > CORE_DBS) {
|
|
|
- MDB_cursor mc;
|
|
|
- MDB_dbi i;
|
|
|
- MDB_val data;
|
|
|
- data.mv_size = sizeof(MDB_db);
|
|
|
-
|
|
|
- mdb_cursor_init(&mc, txn, MAIN_DBI, NULL);
|
|
|
- for (i = CORE_DBS; i < txn->mt_numdbs; i++) {
|
|
|
- if (txn->mt_dbflags[i] & DB_DIRTY) {
|
|
|
- if (TXN_DBI_CHANGED(txn, i)) {
|
|
|
- rc = MDB_BAD_DBI;
|
|
|
- goto fail;
|
|
|
- }
|
|
|
- data.mv_data = &txn->mt_dbs[i];
|
|
|
- rc = mdb_cursor_put(&mc, &txn->mt_dbxs[i].md_name, &data,
|
|
|
- F_SUBDATA);
|
|
|
- if (rc)
|
|
|
- goto fail;
|
|
|
- }
|
|
|
- }
|
|
|
- }
|
|
|
-
|
|
|
- rc = mdb_freelist_save(txn);
|
|
|
- if (rc)
|
|
|
- goto fail;
|
|
|
-
|
|
|
- mdb_midl_free(env->me_pghead);
|
|
|
- env->me_pghead = NULL;
|
|
|
- mdb_midl_shrink(&txn->mt_free_pgs);
|
|
|
-
|
|
|
-#if (MDB_DEBUG) > 2
|
|
|
- mdb_audit(txn);
|
|
|
-#endif
|
|
|
-
|
|
|
- if ((rc = mdb_page_flush(txn, 0)) ||
|
|
|
- (rc = mdb_env_sync(env, 0)) ||
|
|
|
- (rc = mdb_env_write_meta(txn)))
|
|
|
- goto fail;
|
|
|
- end_mode = MDB_END_COMMITTED|MDB_END_UPDATE;
|
|
|
-
|
|
|
-done:
|
|
|
- mdb_txn_end(txn, end_mode);
|
|
|
- return MDB_SUCCESS;
|
|
|
-
|
|
|
-fail:
|
|
|
- mdb_txn_abort(txn);
|
|
|
- return rc;
|
|
|
-}
|
|
|
-
|
|
|
-/** Read the environment parameters of a DB environment before
|
|
|
- * mapping it into memory.
|
|
|
- * @param[in] env the environment handle
|
|
|
- * @param[out] meta address of where to store the meta information
|
|
|
- * @return 0 on success, non-zero on failure.
|
|
|
- */
|
|
|
-static int ESECT
|
|
|
-mdb_env_read_header(MDB_env *env, MDB_meta *meta)
|
|
|
-{
|
|
|
- MDB_metabuf pbuf;
|
|
|
- MDB_page *p;
|
|
|
- MDB_meta *m;
|
|
|
- int i, rc, off;
|
|
|
- enum { Size = sizeof(pbuf) };
|
|
|
-
|
|
|
- /* We don't know the page size yet, so use a minimum value.
|
|
|
- * Read both meta pages so we can use the latest one.
|
|
|
- */
|
|
|
-
|
|
|
- for (i=off=0; i<NUM_METAS; i++, off += meta->mm_psize) {
|
|
|
-#ifdef _WIN32
|
|
|
- DWORD len;
|
|
|
- OVERLAPPED ov;
|
|
|
- memset(&ov, 0, sizeof(ov));
|
|
|
- ov.Offset = off;
|
|
|
- rc = ReadFile(env->me_fd, &pbuf, Size, &len, &ov) ? (int)len : -1;
|
|
|
- if (rc == -1 && ErrCode() == ERROR_HANDLE_EOF)
|
|
|
- rc = 0;
|
|
|
-#else
|
|
|
- rc = pread(env->me_fd, &pbuf, Size, off);
|
|
|
-#endif
|
|
|
- if (rc != Size) {
|
|
|
- if (rc == 0 && off == 0)
|
|
|
- return ENOENT;
|
|
|
- rc = rc < 0 ? (int) ErrCode() : MDB_INVALID;
|
|
|
- DPRINTF(("read: %s", mdb_strerror(rc)));
|
|
|
- return rc;
|
|
|
- }
|
|
|
-
|
|
|
- p = (MDB_page *)&pbuf;
|
|
|
-
|
|
|
- if (!F_ISSET(p->mp_flags, P_META)) {
|
|
|
- DPRINTF(("page %"Z"u not a meta page", p->mp_pgno));
|
|
|
- return MDB_INVALID;
|
|
|
- }
|
|
|
-
|
|
|
- m = METADATA(p);
|
|
|
- if (m->mm_magic != MDB_MAGIC) {
|
|
|
- DPUTS("meta has invalid magic");
|
|
|
- return MDB_INVALID;
|
|
|
- }
|
|
|
-
|
|
|
- if (m->mm_version != MDB_DATA_VERSION) {
|
|
|
- DPRINTF(("database is version %u, expected version %u",
|
|
|
- m->mm_version, MDB_DATA_VERSION));
|
|
|
- return MDB_VERSION_MISMATCH;
|
|
|
- }
|
|
|
-
|
|
|
- if (off == 0 || m->mm_txnid > meta->mm_txnid)
|
|
|
- *meta = *m;
|
|
|
- }
|
|
|
- return 0;
|
|
|
-}
|
|
|
-
|
|
|
-/** Fill in most of the zeroed #MDB_meta for an empty database environment */
|
|
|
-static void ESECT
|
|
|
-mdb_env_init_meta0(MDB_env *env, MDB_meta *meta)
|
|
|
-{
|
|
|
- meta->mm_magic = MDB_MAGIC;
|
|
|
- meta->mm_version = MDB_DATA_VERSION;
|
|
|
- meta->mm_mapsize = env->me_mapsize;
|
|
|
- meta->mm_psize = env->me_psize;
|
|
|
- meta->mm_last_pg = NUM_METAS-1;
|
|
|
- meta->mm_flags = env->me_flags & 0xffff;
|
|
|
- meta->mm_flags |= MDB_INTEGERKEY; /* this is mm_dbs[FREE_DBI].md_flags */
|
|
|
- meta->mm_dbs[FREE_DBI].md_root = P_INVALID;
|
|
|
- meta->mm_dbs[MAIN_DBI].md_root = P_INVALID;
|
|
|
-}
|
|
|
-
|
|
|
-/** Write the environment parameters of a freshly created DB environment.
|
|
|
- * @param[in] env the environment handle
|
|
|
- * @param[in] meta the #MDB_meta to write
|
|
|
- * @return 0 on success, non-zero on failure.
|
|
|
- */
|
|
|
-static int ESECT
|
|
|
-mdb_env_init_meta(MDB_env *env, MDB_meta *meta)
|
|
|
-{
|
|
|
- MDB_page *p, *q;
|
|
|
- int rc;
|
|
|
- unsigned int psize;
|
|
|
-#ifdef _WIN32
|
|
|
- DWORD len;
|
|
|
- OVERLAPPED ov;
|
|
|
- memset(&ov, 0, sizeof(ov));
|
|
|
-#define DO_PWRITE(rc, fd, ptr, size, len, pos) do { \
|
|
|
- ov.Offset = pos; \
|
|
|
- rc = WriteFile(fd, ptr, size, &len, &ov); } while(0)
|
|
|
-#else
|
|
|
- int len;
|
|
|
-#define DO_PWRITE(rc, fd, ptr, size, len, pos) do { \
|
|
|
- len = pwrite(fd, ptr, size, pos); \
|
|
|
- if (len == -1 && ErrCode() == EINTR) continue; \
|
|
|
- rc = (len >= 0); break; } while(1)
|
|
|
-#endif
|
|
|
-
|
|
|
- DPUTS("writing new meta page");
|
|
|
-
|
|
|
- psize = env->me_psize;
|
|
|
-
|
|
|
- p = calloc(NUM_METAS, psize);
|
|
|
- if (!p)
|
|
|
- return ENOMEM;
|
|
|
-
|
|
|
- p->mp_pgno = 0;
|
|
|
- p->mp_flags = P_META;
|
|
|
- *(MDB_meta *)METADATA(p) = *meta;
|
|
|
-
|
|
|
- q = (MDB_page *)((char *)p + psize);
|
|
|
- q->mp_pgno = 1;
|
|
|
- q->mp_flags = P_META;
|
|
|
- *(MDB_meta *)METADATA(q) = *meta;
|
|
|
-
|
|
|
- DO_PWRITE(rc, env->me_fd, p, psize * NUM_METAS, len, 0);
|
|
|
- if (!rc)
|
|
|
- rc = ErrCode();
|
|
|
- else if ((unsigned) len == psize * NUM_METAS)
|
|
|
- rc = MDB_SUCCESS;
|
|
|
- else
|
|
|
- rc = ENOSPC;
|
|
|
- free(p);
|
|
|
- return rc;
|
|
|
-}
|
|
|
-
|
|
|
-/** Update the environment info to commit a transaction.
|
|
|
- * @param[in] txn the transaction that's being committed
|
|
|
- * @return 0 on success, non-zero on failure.
|
|
|
- */
|
|
|
-static int
|
|
|
-mdb_env_write_meta(MDB_txn *txn)
|
|
|
-{
|
|
|
- MDB_env *env;
|
|
|
- MDB_meta meta, metab, *mp;
|
|
|
- unsigned flags;
|
|
|
- size_t mapsize;
|
|
|
- off_t off;
|
|
|
- int rc, len, toggle;
|
|
|
- char *ptr;
|
|
|
- HANDLE mfd;
|
|
|
-#ifdef _WIN32
|
|
|
- OVERLAPPED ov;
|
|
|
-#else
|
|
|
- int r2;
|
|
|
-#endif
|
|
|
-
|
|
|
- toggle = txn->mt_txnid & 1;
|
|
|
- DPRINTF(("writing meta page %d for root page %"Z"u",
|
|
|
- toggle, txn->mt_dbs[MAIN_DBI].md_root));
|
|
|
-
|
|
|
- env = txn->mt_env;
|
|
|
- flags = env->me_flags;
|
|
|
- mp = env->me_metas[toggle];
|
|
|
- mapsize = env->me_metas[toggle ^ 1]->mm_mapsize;
|
|
|
- /* Persist any increases of mapsize config */
|
|
|
- if (mapsize < env->me_mapsize)
|
|
|
- mapsize = env->me_mapsize;
|
|
|
-
|
|
|
- if (flags & MDB_WRITEMAP) {
|
|
|
- mp->mm_mapsize = mapsize;
|
|
|
- mp->mm_dbs[FREE_DBI] = txn->mt_dbs[FREE_DBI];
|
|
|
- mp->mm_dbs[MAIN_DBI] = txn->mt_dbs[MAIN_DBI];
|
|
|
- mp->mm_last_pg = txn->mt_next_pgno - 1;
|
|
|
-#if (__GNUC__ * 100 + __GNUC_MINOR__ >= 404) && /* TODO: portability */ \
|
|
|
- !(defined(__i386__) || defined(__x86_64__))
|
|
|
- /* LY: issue a memory barrier, if not x86. ITS#7969 */
|
|
|
- __sync_synchronize();
|
|
|
-#endif
|
|
|
- mp->mm_txnid = txn->mt_txnid;
|
|
|
- if (!(flags & (MDB_NOMETASYNC|MDB_NOSYNC))) {
|
|
|
- unsigned meta_size = env->me_psize;
|
|
|
- rc = (env->me_flags & MDB_MAPASYNC) ? MS_ASYNC : MS_SYNC;
|
|
|
- ptr = (char *)mp - PAGEHDRSZ;
|
|
|
-#ifndef _WIN32 /* POSIX msync() requires ptr = start of OS page */
|
|
|
- r2 = (ptr - env->me_map) & (env->me_os_psize - 1);
|
|
|
- ptr -= r2;
|
|
|
- meta_size += r2;
|
|
|
-#endif
|
|
|
- if (MDB_MSYNC(ptr, meta_size, rc)) {
|
|
|
- rc = ErrCode();
|
|
|
- goto fail;
|
|
|
- }
|
|
|
- }
|
|
|
- goto done;
|
|
|
- }
|
|
|
- metab.mm_txnid = mp->mm_txnid;
|
|
|
- metab.mm_last_pg = mp->mm_last_pg;
|
|
|
-
|
|
|
- meta.mm_mapsize = mapsize;
|
|
|
- meta.mm_dbs[FREE_DBI] = txn->mt_dbs[FREE_DBI];
|
|
|
- meta.mm_dbs[MAIN_DBI] = txn->mt_dbs[MAIN_DBI];
|
|
|
- meta.mm_last_pg = txn->mt_next_pgno - 1;
|
|
|
- meta.mm_txnid = txn->mt_txnid;
|
|
|
-
|
|
|
- off = offsetof(MDB_meta, mm_mapsize);
|
|
|
- ptr = (char *)&meta + off;
|
|
|
- len = sizeof(MDB_meta) - off;
|
|
|
- off += (char *)mp - env->me_map;
|
|
|
-
|
|
|
- /* Write to the SYNC fd unless MDB_NOSYNC/MDB_NOMETASYNC.
|
|
|
- * (me_mfd goes to the same file as me_fd, but writing to it
|
|
|
- * also syncs to disk. Avoids a separate fdatasync() call.)
|
|
|
- */
|
|
|
- mfd = (flags & (MDB_NOSYNC|MDB_NOMETASYNC)) ? env->me_fd : env->me_mfd;
|
|
|
-#ifdef _WIN32
|
|
|
- {
|
|
|
- memset(&ov, 0, sizeof(ov));
|
|
|
- ov.Offset = off;
|
|
|
- if (!WriteFile(mfd, ptr, len, (DWORD *)&rc, &ov))
|
|
|
- rc = -1;
|
|
|
- }
|
|
|
-#else
|
|
|
-retry_write:
|
|
|
- rc = pwrite(mfd, ptr, len, off);
|
|
|
-#endif
|
|
|
- if (rc != len) {
|
|
|
- rc = rc < 0 ? ErrCode() : EIO;
|
|
|
-#ifndef _WIN32
|
|
|
- if (rc == EINTR)
|
|
|
- goto retry_write;
|
|
|
-#endif
|
|
|
- DPUTS("write failed, disk error?");
|
|
|
- /* On a failure, the pagecache still contains the new data.
|
|
|
- * Write some old data back, to prevent it from being used.
|
|
|
- * Use the non-SYNC fd; we know it will fail anyway.
|
|
|
- */
|
|
|
- meta.mm_last_pg = metab.mm_last_pg;
|
|
|
- meta.mm_txnid = metab.mm_txnid;
|
|
|
-#ifdef _WIN32
|
|
|
- memset(&ov, 0, sizeof(ov));
|
|
|
- ov.Offset = off;
|
|
|
- WriteFile(env->me_fd, ptr, len, NULL, &ov);
|
|
|
-#else
|
|
|
- r2 = pwrite(env->me_fd, ptr, len, off);
|
|
|
- (void)r2; /* Silence warnings. We don't care about pwrite's return value */
|
|
|
-#endif
|
|
|
-fail:
|
|
|
- env->me_flags |= MDB_FATAL_ERROR;
|
|
|
- return rc;
|
|
|
- }
|
|
|
- /* MIPS has cache coherency issues, this is a no-op everywhere else */
|
|
|
- CACHEFLUSH(env->me_map + off, len, DCACHE);
|
|
|
-done:
|
|
|
- /* Memory ordering issues are irrelevant; since the entire writer
|
|
|
- * is wrapped by wmutex, all of these changes will become visible
|
|
|
- * after the wmutex is unlocked. Since the DB is multi-version,
|
|
|
- * readers will get consistent data regardless of how fresh or
|
|
|
- * how stale their view of these values is.
|
|
|
- */
|
|
|
- if (env->me_txns)
|
|
|
- env->me_txns->mti_txnid = txn->mt_txnid;
|
|
|
-
|
|
|
- return MDB_SUCCESS;
|
|
|
-}
|
|
|
-
|
|
|
-/** Check both meta pages to see which one is newer.
|
|
|
- * @param[in] env the environment handle
|
|
|
- * @return newest #MDB_meta.
|
|
|
- */
|
|
|
-static MDB_meta *
|
|
|
-mdb_env_pick_meta(const MDB_env *env)
|
|
|
-{
|
|
|
- MDB_meta *const *metas = env->me_metas;
|
|
|
- return metas[ metas[0]->mm_txnid < metas[1]->mm_txnid ];
|
|
|
-}
|
|
|
-
|
|
|
-int ESECT
|
|
|
-mdb_env_create(MDB_env **env)
|
|
|
-{
|
|
|
- MDB_env *e;
|
|
|
-
|
|
|
- e = calloc(1, sizeof(MDB_env));
|
|
|
- if (!e)
|
|
|
- return ENOMEM;
|
|
|
-
|
|
|
- e->me_maxreaders = DEFAULT_READERS;
|
|
|
- e->me_maxdbs = e->me_numdbs = CORE_DBS;
|
|
|
- e->me_fd = INVALID_HANDLE_VALUE;
|
|
|
- e->me_lfd = INVALID_HANDLE_VALUE;
|
|
|
- e->me_mfd = INVALID_HANDLE_VALUE;
|
|
|
-#ifdef MDB_USE_POSIX_SEM
|
|
|
- e->me_rmutex = SEM_FAILED;
|
|
|
- e->me_wmutex = SEM_FAILED;
|
|
|
-#endif
|
|
|
- e->me_pid = getpid();
|
|
|
- GET_PAGESIZE(e->me_os_psize);
|
|
|
- VGMEMP_CREATE(e,0,0);
|
|
|
- *env = e;
|
|
|
- return MDB_SUCCESS;
|
|
|
-}
|
|
|
-
|
|
|
-static int ESECT
|
|
|
-mdb_env_map(MDB_env *env, void *addr)
|
|
|
-{
|
|
|
- MDB_page *p;
|
|
|
- unsigned int flags = env->me_flags;
|
|
|
-#ifdef _WIN32
|
|
|
- int rc;
|
|
|
- HANDLE mh;
|
|
|
- LONG sizelo, sizehi;
|
|
|
- size_t msize;
|
|
|
-
|
|
|
- if (flags & MDB_RDONLY) {
|
|
|
- /* Don't set explicit map size, use whatever exists */
|
|
|
- msize = 0;
|
|
|
- sizelo = 0;
|
|
|
- sizehi = 0;
|
|
|
- } else {
|
|
|
- msize = env->me_mapsize;
|
|
|
- sizelo = msize & 0xffffffff;
|
|
|
- sizehi = msize >> 16 >> 16; /* only needed on Win64 */
|
|
|
-
|
|
|
- /* Windows won't create mappings for zero length files.
|
|
|
- * and won't map more than the file size.
|
|
|
- * Just set the maxsize right now.
|
|
|
- */
|
|
|
- if (SetFilePointer(env->me_fd, sizelo, &sizehi, 0) != (DWORD)sizelo
|
|
|
- || !SetEndOfFile(env->me_fd)
|
|
|
- || SetFilePointer(env->me_fd, 0, NULL, 0) != 0)
|
|
|
- return ErrCode();
|
|
|
- }
|
|
|
-
|
|
|
- mh = CreateFileMapping(env->me_fd, NULL, flags & MDB_WRITEMAP ?
|
|
|
- PAGE_READWRITE : PAGE_READONLY,
|
|
|
- sizehi, sizelo, NULL);
|
|
|
- if (!mh)
|
|
|
- return ErrCode();
|
|
|
- env->me_map = MapViewOfFileEx(mh, flags & MDB_WRITEMAP ?
|
|
|
- FILE_MAP_WRITE : FILE_MAP_READ,
|
|
|
- 0, 0, msize, addr);
|
|
|
- rc = env->me_map ? 0 : ErrCode();
|
|
|
- CloseHandle(mh);
|
|
|
- if (rc)
|
|
|
- return rc;
|
|
|
-#else
|
|
|
- int prot = PROT_READ;
|
|
|
- if (flags & MDB_WRITEMAP) {
|
|
|
- prot |= PROT_WRITE;
|
|
|
- if (ftruncate(env->me_fd, env->me_mapsize) < 0)
|
|
|
- return ErrCode();
|
|
|
- }
|
|
|
- env->me_map = mmap(addr, env->me_mapsize, prot, MAP_SHARED,
|
|
|
- env->me_fd, 0);
|
|
|
- if (env->me_map == MAP_FAILED) {
|
|
|
- env->me_map = NULL;
|
|
|
- return ErrCode();
|
|
|
- }
|
|
|
-
|
|
|
- if (flags & MDB_NORDAHEAD) {
|
|
|
- /* Turn off readahead. It's harmful when the DB is larger than RAM. */
|
|
|
-#ifdef MADV_RANDOM
|
|
|
- madvise(env->me_map, env->me_mapsize, MADV_RANDOM);
|
|
|
-#else
|
|
|
-#ifdef POSIX_MADV_RANDOM
|
|
|
- posix_madvise(env->me_map, env->me_mapsize, POSIX_MADV_RANDOM);
|
|
|
-#endif /* POSIX_MADV_RANDOM */
|
|
|
-#endif /* MADV_RANDOM */
|
|
|
- }
|
|
|
-#endif /* _WIN32 */
|
|
|
-
|
|
|
- /* Can happen because the address argument to mmap() is just a
|
|
|
- * hint. mmap() can pick another, e.g. if the range is in use.
|
|
|
- * The MAP_FIXED flag would prevent that, but then mmap could
|
|
|
- * instead unmap existing pages to make room for the new map.
|
|
|
- */
|
|
|
- if (addr && env->me_map != addr)
|
|
|
- return EBUSY; /* TODO: Make a new MDB_* error code? */
|
|
|
-
|
|
|
- p = (MDB_page *)env->me_map;
|
|
|
- env->me_metas[0] = METADATA(p);
|
|
|
- env->me_metas[1] = (MDB_meta *)((char *)env->me_metas[0] + env->me_psize);
|
|
|
-
|
|
|
- return MDB_SUCCESS;
|
|
|
-}
|
|
|
-
|
|
|
-int ESECT
|
|
|
-mdb_env_set_mapsize(MDB_env *env, size_t size)
|
|
|
-{
|
|
|
- /* If env is already open, caller is responsible for making
|
|
|
- * sure there are no active txns.
|
|
|
- */
|
|
|
- if (env->me_map) {
|
|
|
- int rc;
|
|
|
- MDB_meta *meta;
|
|
|
- void *old;
|
|
|
- if (env->me_txn)
|
|
|
- return EINVAL;
|
|
|
- meta = mdb_env_pick_meta(env);
|
|
|
- if (!size)
|
|
|
- size = meta->mm_mapsize;
|
|
|
- {
|
|
|
- /* Silently round up to minimum if the size is too small */
|
|
|
- size_t minsize = (meta->mm_last_pg + 1) * env->me_psize;
|
|
|
- if (size < minsize)
|
|
|
- size = minsize;
|
|
|
- }
|
|
|
- munmap(env->me_map, env->me_mapsize);
|
|
|
- env->me_mapsize = size;
|
|
|
- old = (env->me_flags & MDB_FIXEDMAP) ? env->me_map : NULL;
|
|
|
- rc = mdb_env_map(env, old);
|
|
|
- if (rc)
|
|
|
- return rc;
|
|
|
- }
|
|
|
- env->me_mapsize = size;
|
|
|
- if (env->me_psize)
|
|
|
- env->me_maxpg = env->me_mapsize / env->me_psize;
|
|
|
- return MDB_SUCCESS;
|
|
|
-}
|
|
|
-
|
|
|
-int ESECT
|
|
|
-mdb_env_set_maxdbs(MDB_env *env, MDB_dbi dbs)
|
|
|
-{
|
|
|
- if (env->me_map)
|
|
|
- return EINVAL;
|
|
|
- env->me_maxdbs = dbs + CORE_DBS;
|
|
|
- return MDB_SUCCESS;
|
|
|
-}
|
|
|
-
|
|
|
-int ESECT
|
|
|
-mdb_env_set_maxreaders(MDB_env *env, unsigned int readers)
|
|
|
-{
|
|
|
- if (env->me_map || readers < 1)
|
|
|
- return EINVAL;
|
|
|
- env->me_maxreaders = readers;
|
|
|
- return MDB_SUCCESS;
|
|
|
-}
|
|
|
-
|
|
|
-int ESECT
|
|
|
-mdb_env_get_maxreaders(MDB_env *env, unsigned int *readers)
|
|
|
-{
|
|
|
- if (!env || !readers)
|
|
|
- return EINVAL;
|
|
|
- *readers = env->me_maxreaders;
|
|
|
- return MDB_SUCCESS;
|
|
|
-}
|
|
|
-
|
|
|
-static int ESECT
|
|
|
-mdb_fsize(HANDLE fd, size_t *size)
|
|
|
-{
|
|
|
-#ifdef _WIN32
|
|
|
- LARGE_INTEGER fsize;
|
|
|
-
|
|
|
- if (!GetFileSizeEx(fd, &fsize))
|
|
|
- return ErrCode();
|
|
|
-
|
|
|
- *size = fsize.QuadPart;
|
|
|
-#else
|
|
|
- struct stat st;
|
|
|
-
|
|
|
- if (fstat(fd, &st))
|
|
|
- return ErrCode();
|
|
|
-
|
|
|
- *size = st.st_size;
|
|
|
-#endif
|
|
|
- return MDB_SUCCESS;
|
|
|
-}
|
|
|
-
|
|
|
-
|
|
|
-#ifdef _WIN32
|
|
|
-typedef wchar_t mdb_nchar_t;
|
|
|
-# define MDB_NAME(str) L##str
|
|
|
-# define mdb_name_cpy wcscpy
|
|
|
-#else
|
|
|
-/** Character type for file names: char on Unix, wchar_t on Windows */
|
|
|
-typedef char mdb_nchar_t;
|
|
|
-# define MDB_NAME(str) str /**< #mdb_nchar_t[] string literal */
|
|
|
-# define mdb_name_cpy strcpy /**< Copy name (#mdb_nchar_t string) */
|
|
|
-#endif
|
|
|
-
|
|
|
-/** Filename - string of #mdb_nchar_t[] */
|
|
|
-typedef struct MDB_name {
|
|
|
- int mn_len; /**< Length */
|
|
|
- int mn_alloced; /**< True if #mn_val was malloced */
|
|
|
- mdb_nchar_t *mn_val; /**< Contents */
|
|
|
-} MDB_name;
|
|
|
-
|
|
|
-/** Filename suffixes [datafile,lockfile][without,with MDB_NOSUBDIR] */
|
|
|
-static const mdb_nchar_t *const mdb_suffixes[2][2] = {
|
|
|
- { MDB_NAME("/data.mdb"), MDB_NAME("") },
|
|
|
- { MDB_NAME("/lock.mdb"), MDB_NAME("-lock") }
|
|
|
-};
|
|
|
-
|
|
|
-#define MDB_SUFFLEN 9 /**< Max string length in #mdb_suffixes[] */
|
|
|
-
|
|
|
-/** Set up filename + scratch area for filename suffix, for opening files.
|
|
|
- * It should be freed with #mdb_fname_destroy().
|
|
|
- * On Windows, paths are converted from char *UTF-8 to wchar_t *UTF-16.
|
|
|
- *
|
|
|
- * @param[in] path Pathname for #mdb_env_open().
|
|
|
- * @param[in] envflags Whether a subdir and/or lockfile will be used.
|
|
|
- * @param[out] fname Resulting filename, with room for a suffix if necessary.
|
|
|
- */
|
|
|
-static int ESECT
|
|
|
-mdb_fname_init(const char *path, unsigned envflags, MDB_name *fname)
|
|
|
-{
|
|
|
- int no_suffix = F_ISSET(envflags, MDB_NOSUBDIR|MDB_NOLOCK);
|
|
|
- fname->mn_alloced = 0;
|
|
|
-#ifdef _WIN32
|
|
|
- return utf8_to_utf16(path, fname, no_suffix ? 0 : MDB_SUFFLEN);
|
|
|
-#else
|
|
|
- fname->mn_len = strlen(path);
|
|
|
- if (no_suffix)
|
|
|
- fname->mn_val = (char *) path;
|
|
|
- else if ((fname->mn_val = malloc(fname->mn_len + MDB_SUFFLEN+1)) != NULL) {
|
|
|
- fname->mn_alloced = 1;
|
|
|
- strcpy(fname->mn_val, path);
|
|
|
- }
|
|
|
- else
|
|
|
- return ENOMEM;
|
|
|
- return MDB_SUCCESS;
|
|
|
-#endif
|
|
|
-}
|
|
|
-
|
|
|
-/** Destroy \b fname from #mdb_fname_init() */
|
|
|
-#define mdb_fname_destroy(fname) \
|
|
|
- do { if ((fname).mn_alloced) free((fname).mn_val); } while (0)
|
|
|
-
|
|
|
-#ifdef O_CLOEXEC /* POSIX.1-2008: Set FD_CLOEXEC atomically at open() */
|
|
|
-# define MDB_CLOEXEC O_CLOEXEC
|
|
|
-#else
|
|
|
-# define MDB_CLOEXEC 0
|
|
|
-#endif
|
|
|
-
|
|
|
-/** File type, access mode etc. for #mdb_fopen() */
|
|
|
-enum mdb_fopen_type {
|
|
|
-#ifdef _WIN32
|
|
|
- MDB_O_RDONLY, MDB_O_RDWR, MDB_O_META, MDB_O_COPY, MDB_O_LOCKS
|
|
|
-#else
|
|
|
- /* A comment in mdb_fopen() explains some O_* flag choices. */
|
|
|
- MDB_O_RDONLY= O_RDONLY, /**< for RDONLY me_fd */
|
|
|
- MDB_O_RDWR = O_RDWR |O_CREAT, /**< for me_fd */
|
|
|
- MDB_O_META = O_WRONLY|MDB_DSYNC |MDB_CLOEXEC, /**< for me_mfd */
|
|
|
- MDB_O_COPY = O_WRONLY|O_CREAT|O_EXCL|MDB_CLOEXEC, /**< for #mdb_env_copy() */
|
|
|
- /** Bitmask for open() flags in enum #mdb_fopen_type. The other bits
|
|
|
- * distinguish otherwise-equal MDB_O_* constants from each other.
|
|
|
- */
|
|
|
- MDB_O_MASK = MDB_O_RDWR|MDB_CLOEXEC | MDB_O_RDONLY|MDB_O_META|MDB_O_COPY,
|
|
|
- MDB_O_LOCKS = MDB_O_RDWR|MDB_CLOEXEC | ((MDB_O_MASK+1) & ~MDB_O_MASK) /**< for me_lfd */
|
|
|
-#endif
|
|
|
-};
|
|
|
-
|
|
|
-/** Open an LMDB file.
|
|
|
- * @param[in] env The LMDB environment.
|
|
|
- * @param[in,out] fname Path from from #mdb_fname_init(). A suffix is
|
|
|
- * appended if necessary to create the filename, without changing mn_len.
|
|
|
- * @param[in] which Determines file type, access mode, etc.
|
|
|
- * @param[in] mode The Unix permissions for the file, if we create it.
|
|
|
- * @param[out] res Resulting file handle.
|
|
|
- * @return 0 on success, non-zero on failure.
|
|
|
- */
|
|
|
-static int ESECT
|
|
|
-mdb_fopen(const MDB_env *env, MDB_name *fname,
|
|
|
- enum mdb_fopen_type which, mdb_mode_t mode,
|
|
|
- HANDLE *res)
|
|
|
-{
|
|
|
- int rc = MDB_SUCCESS;
|
|
|
- HANDLE fd;
|
|
|
-#ifdef _WIN32
|
|
|
- DWORD acc, share, disp, attrs;
|
|
|
-#else
|
|
|
- int flags;
|
|
|
-#endif
|
|
|
-
|
|
|
- if (fname->mn_alloced) /* modifiable copy */
|
|
|
- mdb_name_cpy(fname->mn_val + fname->mn_len,
|
|
|
- mdb_suffixes[which==MDB_O_LOCKS][F_ISSET(env->me_flags, MDB_NOSUBDIR)]);
|
|
|
-
|
|
|
- /* The directory must already exist. Usually the file need not.
|
|
|
- * MDB_O_META requires the file because we already created it using
|
|
|
- * MDB_O_RDWR. MDB_O_COPY must not overwrite an existing file.
|
|
|
- *
|
|
|
- * With MDB_O_COPY we do not want the OS to cache the writes, since
|
|
|
- * the source data is already in the OS cache.
|
|
|
- *
|
|
|
- * The lockfile needs FD_CLOEXEC (close file descriptor on exec*())
|
|
|
- * to avoid the flock() issues noted under Caveats in lmdb.h.
|
|
|
- * Also set it for other filehandles which the user cannot get at
|
|
|
- * and close himself, which he may need after fork(). I.e. all but
|
|
|
- * me_fd, which programs do use via mdb_env_get_fd().
|
|
|
- */
|
|
|
-
|
|
|
-#ifdef _WIN32
|
|
|
- acc = GENERIC_READ|GENERIC_WRITE;
|
|
|
- share = FILE_SHARE_READ|FILE_SHARE_WRITE;
|
|
|
- disp = OPEN_ALWAYS;
|
|
|
- attrs = FILE_ATTRIBUTE_NORMAL;
|
|
|
- switch (which) {
|
|
|
- case MDB_O_RDONLY: /* read-only datafile */
|
|
|
- acc = GENERIC_READ;
|
|
|
- disp = OPEN_EXISTING;
|
|
|
- break;
|
|
|
- case MDB_O_META: /* for writing metapages */
|
|
|
- acc = GENERIC_WRITE;
|
|
|
- disp = OPEN_EXISTING;
|
|
|
- attrs = FILE_ATTRIBUTE_NORMAL|FILE_FLAG_WRITE_THROUGH;
|
|
|
- break;
|
|
|
- case MDB_O_COPY: /* mdb_env_copy() & co */
|
|
|
- acc = GENERIC_WRITE;
|
|
|
- share = 0;
|
|
|
- disp = CREATE_NEW;
|
|
|
- attrs = FILE_FLAG_NO_BUFFERING|FILE_FLAG_WRITE_THROUGH;
|
|
|
- break;
|
|
|
- default: break; /* silence gcc -Wswitch (not all enum values handled) */
|
|
|
- }
|
|
|
- fd = CreateFileW(fname->mn_val, acc, share, NULL, disp, attrs, NULL);
|
|
|
-#else
|
|
|
- fd = open(fname->mn_val, which & MDB_O_MASK, mode);
|
|
|
-#endif
|
|
|
-
|
|
|
- if (fd == INVALID_HANDLE_VALUE)
|
|
|
- rc = ErrCode();
|
|
|
-#ifndef _WIN32
|
|
|
- else {
|
|
|
- if (which != MDB_O_RDONLY && which != MDB_O_RDWR) {
|
|
|
- /* Set CLOEXEC if we could not pass it to open() */
|
|
|
- if (!MDB_CLOEXEC && (flags = fcntl(fd, F_GETFD)) != -1)
|
|
|
- (void) fcntl(fd, F_SETFD, flags | FD_CLOEXEC);
|
|
|
- }
|
|
|
- if (which == MDB_O_COPY && env->me_psize >= env->me_os_psize) {
|
|
|
- /* This may require buffer alignment. There is no portable
|
|
|
- * way to ask how much, so we require OS pagesize alignment.
|
|
|
- */
|
|
|
-# ifdef F_NOCACHE /* __APPLE__ */
|
|
|
- (void) fcntl(fd, F_NOCACHE, 1);
|
|
|
-# elif defined O_DIRECT
|
|
|
- /* open(...O_DIRECT...) would break on filesystems without
|
|
|
- * O_DIRECT support (ITS#7682). Try to set it here instead.
|
|
|
- */
|
|
|
- if ((flags = fcntl(fd, F_GETFL)) != -1)
|
|
|
- (void) fcntl(fd, F_SETFL, flags | O_DIRECT);
|
|
|
-# endif
|
|
|
- }
|
|
|
- }
|
|
|
-#endif /* !_WIN32 */
|
|
|
-
|
|
|
- *res = fd;
|
|
|
- return rc;
|
|
|
-}
|
|
|
-
|
|
|
-
|
|
|
-#ifdef BROKEN_FDATASYNC
|
|
|
-#include <sys/utsname.h>
|
|
|
-#include <sys/vfs.h>
|
|
|
-#endif
|
|
|
-
|
|
|
-/** Further setup required for opening an LMDB environment
|
|
|
- */
|
|
|
-static int ESECT
|
|
|
-mdb_env_open2(MDB_env *env)
|
|
|
-{
|
|
|
- unsigned int flags = env->me_flags;
|
|
|
- int i, newenv = 0, rc;
|
|
|
- MDB_meta meta;
|
|
|
-
|
|
|
-#ifdef _WIN32
|
|
|
- /* See if we should use QueryLimited */
|
|
|
- rc = GetVersion();
|
|
|
- if ((rc & 0xff) > 5)
|
|
|
- env->me_pidquery = MDB_PROCESS_QUERY_LIMITED_INFORMATION;
|
|
|
- else
|
|
|
- env->me_pidquery = PROCESS_QUERY_INFORMATION;
|
|
|
-#endif /* _WIN32 */
|
|
|
-
|
|
|
-#ifdef BROKEN_FDATASYNC
|
|
|
- /* ext3/ext4 fdatasync is broken on some older Linux kernels.
|
|
|
- * https://lkml.org/lkml/2012/9/3/83
|
|
|
- * Kernels after 3.6-rc6 are known good.
|
|
|
- * https://lkml.org/lkml/2012/9/10/556
|
|
|
- * See if the DB is on ext3/ext4, then check for new enough kernel
|
|
|
- * Kernels 2.6.32.60, 2.6.34.15, 3.2.30, and 3.5.4 are also known
|
|
|
- * to be patched.
|
|
|
- */
|
|
|
- {
|
|
|
- struct statfs st;
|
|
|
- fstatfs(env->me_fd, &st);
|
|
|
- while (st.f_type == 0xEF53) {
|
|
|
- struct utsname uts;
|
|
|
- int i;
|
|
|
- uname(&uts);
|
|
|
- if (uts.release[0] < '3') {
|
|
|
- if (!strncmp(uts.release, "2.6.32.", 7)) {
|
|
|
- i = atoi(uts.release+7);
|
|
|
- if (i >= 60)
|
|
|
- break; /* 2.6.32.60 and newer is OK */
|
|
|
- } else if (!strncmp(uts.release, "2.6.34.", 7)) {
|
|
|
- i = atoi(uts.release+7);
|
|
|
- if (i >= 15)
|
|
|
- break; /* 2.6.34.15 and newer is OK */
|
|
|
- }
|
|
|
- } else if (uts.release[0] == '3') {
|
|
|
- i = atoi(uts.release+2);
|
|
|
- if (i > 5)
|
|
|
- break; /* 3.6 and newer is OK */
|
|
|
- if (i == 5) {
|
|
|
- i = atoi(uts.release+4);
|
|
|
- if (i >= 4)
|
|
|
- break; /* 3.5.4 and newer is OK */
|
|
|
- } else if (i == 2) {
|
|
|
- i = atoi(uts.release+4);
|
|
|
- if (i >= 30)
|
|
|
- break; /* 3.2.30 and newer is OK */
|
|
|
- }
|
|
|
- } else { /* 4.x and newer is OK */
|
|
|
- break;
|
|
|
- }
|
|
|
- env->me_flags |= MDB_FSYNCONLY;
|
|
|
- break;
|
|
|
- }
|
|
|
- }
|
|
|
-#endif
|
|
|
-
|
|
|
- if ((i = mdb_env_read_header(env, &meta)) != 0) {
|
|
|
- if (i != ENOENT)
|
|
|
- return i;
|
|
|
- DPUTS("new mdbenv");
|
|
|
- newenv = 1;
|
|
|
- env->me_psize = env->me_os_psize;
|
|
|
- if (env->me_psize > MAX_PAGESIZE)
|
|
|
- env->me_psize = MAX_PAGESIZE;
|
|
|
- memset(&meta, 0, sizeof(meta));
|
|
|
- mdb_env_init_meta0(env, &meta);
|
|
|
- meta.mm_mapsize = DEFAULT_MAPSIZE;
|
|
|
- } else {
|
|
|
- env->me_psize = meta.mm_psize;
|
|
|
- }
|
|
|
-
|
|
|
- /* Was a mapsize configured? */
|
|
|
- if (!env->me_mapsize) {
|
|
|
- env->me_mapsize = meta.mm_mapsize;
|
|
|
- }
|
|
|
- {
|
|
|
- /* Make sure mapsize >= committed data size. Even when using
|
|
|
- * mm_mapsize, which could be broken in old files (ITS#7789).
|
|
|
- */
|
|
|
- size_t minsize = (meta.mm_last_pg + 1) * meta.mm_psize;
|
|
|
- if (env->me_mapsize < minsize)
|
|
|
- env->me_mapsize = minsize;
|
|
|
- }
|
|
|
- meta.mm_mapsize = env->me_mapsize;
|
|
|
-
|
|
|
- if (newenv && !(flags & MDB_FIXEDMAP)) {
|
|
|
- /* mdb_env_map() may grow the datafile. Write the metapages
|
|
|
- * first, so the file will be valid if initialization fails.
|
|
|
- * Except with FIXEDMAP, since we do not yet know mm_address.
|
|
|
- * We could fill in mm_address later, but then a different
|
|
|
- * program might end up doing that - one with a memory layout
|
|
|
- * and map address which does not suit the main program.
|
|
|
- */
|
|
|
- rc = mdb_env_init_meta(env, &meta);
|
|
|
- if (rc)
|
|
|
- return rc;
|
|
|
- newenv = 0;
|
|
|
- }
|
|
|
-
|
|
|
- rc = mdb_env_map(env, (flags & MDB_FIXEDMAP) ? meta.mm_address : NULL);
|
|
|
- if (rc)
|
|
|
- return rc;
|
|
|
-
|
|
|
- if (newenv) {
|
|
|
- if (flags & MDB_FIXEDMAP)
|
|
|
- meta.mm_address = env->me_map;
|
|
|
- i = mdb_env_init_meta(env, &meta);
|
|
|
- if (i != MDB_SUCCESS) {
|
|
|
- return i;
|
|
|
- }
|
|
|
- }
|
|
|
-
|
|
|
- env->me_maxfree_1pg = (env->me_psize - PAGEHDRSZ) / sizeof(pgno_t) - 1;
|
|
|
- env->me_nodemax = (((env->me_psize - PAGEHDRSZ) / MDB_MINKEYS) & -2)
|
|
|
- - sizeof(indx_t);
|
|
|
-#if !(MDB_MAXKEYSIZE)
|
|
|
- env->me_maxkey = env->me_nodemax - (NODESIZE + sizeof(MDB_db));
|
|
|
-#endif
|
|
|
- env->me_maxpg = env->me_mapsize / env->me_psize;
|
|
|
-
|
|
|
-#if MDB_DEBUG
|
|
|
- {
|
|
|
- MDB_meta *meta = mdb_env_pick_meta(env);
|
|
|
- MDB_db *db = &meta->mm_dbs[MAIN_DBI];
|
|
|
-
|
|
|
- DPRINTF(("opened database version %u, pagesize %u",
|
|
|
- meta->mm_version, env->me_psize));
|
|
|
- DPRINTF(("using meta page %d", (int) (meta->mm_txnid & 1)));
|
|
|
- DPRINTF(("depth: %u", db->md_depth));
|
|
|
- DPRINTF(("entries: %"Z"u", db->md_entries));
|
|
|
- DPRINTF(("branch pages: %"Z"u", db->md_branch_pages));
|
|
|
- DPRINTF(("leaf pages: %"Z"u", db->md_leaf_pages));
|
|
|
- DPRINTF(("overflow pages: %"Z"u", db->md_overflow_pages));
|
|
|
- DPRINTF(("root: %"Z"u", db->md_root));
|
|
|
- }
|
|
|
-#endif
|
|
|
-
|
|
|
- return MDB_SUCCESS;
|
|
|
-}
|
|
|
-
|
|
|
-
|
|
|
-/** Release a reader thread's slot in the reader lock table.
|
|
|
- * This function is called automatically when a thread exits.
|
|
|
- * @param[in] ptr This points to the slot in the reader lock table.
|
|
|
- */
|
|
|
-static void
|
|
|
-mdb_env_reader_dest(void *ptr)
|
|
|
-{
|
|
|
- MDB_reader *reader = ptr;
|
|
|
-
|
|
|
-#ifndef _WIN32
|
|
|
- if (reader->mr_pid == getpid()) /* catch pthread_exit() in child process */
|
|
|
-#endif
|
|
|
- /* We omit the mutex, so do this atomically (i.e. skip mr_txnid) */
|
|
|
- reader->mr_pid = 0;
|
|
|
-}
|
|
|
-
|
|
|
-#ifdef _WIN32
|
|
|
-/** Junk for arranging thread-specific callbacks on Windows. This is
|
|
|
- * necessarily platform and compiler-specific. Windows supports up
|
|
|
- * to 1088 keys. Let's assume nobody opens more than 64 environments
|
|
|
- * in a single process, for now. They can override this if needed.
|
|
|
- */
|
|
|
-#ifndef MAX_TLS_KEYS
|
|
|
-#define MAX_TLS_KEYS 64
|
|
|
-#endif
|
|
|
-static pthread_key_t mdb_tls_keys[MAX_TLS_KEYS];
|
|
|
-static int mdb_tls_nkeys;
|
|
|
-
|
|
|
-static void NTAPI mdb_tls_callback(PVOID module, DWORD reason, PVOID ptr)
|
|
|
-{
|
|
|
- int i;
|
|
|
- switch(reason) {
|
|
|
- case DLL_PROCESS_ATTACH: break;
|
|
|
- case DLL_THREAD_ATTACH: break;
|
|
|
- case DLL_THREAD_DETACH:
|
|
|
- for (i=0; i<mdb_tls_nkeys; i++) {
|
|
|
- MDB_reader *r = pthread_getspecific(mdb_tls_keys[i]);
|
|
|
- if (r) {
|
|
|
- mdb_env_reader_dest(r);
|
|
|
- }
|
|
|
- }
|
|
|
- break;
|
|
|
- case DLL_PROCESS_DETACH: break;
|
|
|
- }
|
|
|
-}
|
|
|
-#ifdef __GNUC__
|
|
|
-#ifdef _WIN64
|
|
|
-const PIMAGE_TLS_CALLBACK mdb_tls_cbp __attribute__((section (".CRT$XLB"))) = mdb_tls_callback;
|
|
|
-#else
|
|
|
-PIMAGE_TLS_CALLBACK mdb_tls_cbp __attribute__((section (".CRT$XLB"))) = mdb_tls_callback;
|
|
|
-#endif
|
|
|
-#else
|
|
|
-#ifdef _WIN64
|
|
|
-/* Force some symbol references.
|
|
|
- * _tls_used forces the linker to create the TLS directory if not already done
|
|
|
- * mdb_tls_cbp prevents whole-program-optimizer from dropping the symbol.
|
|
|
- */
|
|
|
-#pragma comment(linker, "/INCLUDE:_tls_used")
|
|
|
-#pragma comment(linker, "/INCLUDE:mdb_tls_cbp")
|
|
|
-#pragma const_seg(".CRT$XLB")
|
|
|
-extern const PIMAGE_TLS_CALLBACK mdb_tls_cbp;
|
|
|
-const PIMAGE_TLS_CALLBACK mdb_tls_cbp = mdb_tls_callback;
|
|
|
-#pragma const_seg()
|
|
|
-#else /* _WIN32 */
|
|
|
-#pragma comment(linker, "/INCLUDE:__tls_used")
|
|
|
-#pragma comment(linker, "/INCLUDE:_mdb_tls_cbp")
|
|
|
-#pragma data_seg(".CRT$XLB")
|
|
|
-PIMAGE_TLS_CALLBACK mdb_tls_cbp = mdb_tls_callback;
|
|
|
-#pragma data_seg()
|
|
|
-#endif /* WIN 32/64 */
|
|
|
-#endif /* !__GNUC__ */
|
|
|
-#endif
|
|
|
-
|
|
|
-/** Downgrade the exclusive lock on the region back to shared */
|
|
|
-static int ESECT
|
|
|
-mdb_env_share_locks(MDB_env *env, int *excl)
|
|
|
-{
|
|
|
- int rc = 0;
|
|
|
- MDB_meta *meta = mdb_env_pick_meta(env);
|
|
|
-
|
|
|
- env->me_txns->mti_txnid = meta->mm_txnid;
|
|
|
-
|
|
|
-#ifdef _WIN32
|
|
|
- {
|
|
|
- OVERLAPPED ov;
|
|
|
- /* First acquire a shared lock. The Unlock will
|
|
|
- * then release the existing exclusive lock.
|
|
|
- */
|
|
|
- memset(&ov, 0, sizeof(ov));
|
|
|
- if (!LockFileEx(env->me_lfd, 0, 0, 1, 0, &ov)) {
|
|
|
- rc = ErrCode();
|
|
|
- } else {
|
|
|
- UnlockFile(env->me_lfd, 0, 0, 1, 0);
|
|
|
- *excl = 0;
|
|
|
- }
|
|
|
- }
|
|
|
-#else
|
|
|
- {
|
|
|
- struct flock lock_info;
|
|
|
- /* The shared lock replaces the existing lock */
|
|
|
- memset((void *)&lock_info, 0, sizeof(lock_info));
|
|
|
- lock_info.l_type = F_RDLCK;
|
|
|
- lock_info.l_whence = SEEK_SET;
|
|
|
- lock_info.l_start = 0;
|
|
|
- lock_info.l_len = 1;
|
|
|
- while ((rc = fcntl(env->me_lfd, F_SETLK, &lock_info)) &&
|
|
|
- (rc = ErrCode()) == EINTR) ;
|
|
|
- *excl = rc ? -1 : 0; /* error may mean we lost the lock */
|
|
|
- }
|
|
|
-#endif
|
|
|
-
|
|
|
- return rc;
|
|
|
-}
|
|
|
-
|
|
|
-/** Try to get exclusive lock, otherwise shared.
|
|
|
- * Maintain *excl = -1: no/unknown lock, 0: shared, 1: exclusive.
|
|
|
- */
|
|
|
-static int ESECT
|
|
|
-mdb_env_excl_lock(MDB_env *env, int *excl)
|
|
|
-{
|
|
|
- int rc = 0;
|
|
|
-#ifdef _WIN32
|
|
|
- if (LockFile(env->me_lfd, 0, 0, 1, 0)) {
|
|
|
- *excl = 1;
|
|
|
- } else {
|
|
|
- OVERLAPPED ov;
|
|
|
- memset(&ov, 0, sizeof(ov));
|
|
|
- if (LockFileEx(env->me_lfd, 0, 0, 1, 0, &ov)) {
|
|
|
- *excl = 0;
|
|
|
- } else {
|
|
|
- rc = ErrCode();
|
|
|
- }
|
|
|
- }
|
|
|
-#else
|
|
|
- struct flock lock_info;
|
|
|
- memset((void *)&lock_info, 0, sizeof(lock_info));
|
|
|
- lock_info.l_type = F_WRLCK;
|
|
|
- lock_info.l_whence = SEEK_SET;
|
|
|
- lock_info.l_start = 0;
|
|
|
- lock_info.l_len = 1;
|
|
|
- while ((rc = fcntl(env->me_lfd, F_SETLK, &lock_info)) &&
|
|
|
- (rc = ErrCode()) == EINTR) ;
|
|
|
- if (!rc) {
|
|
|
- *excl = 1;
|
|
|
- } else
|
|
|
-# ifndef MDB_USE_POSIX_MUTEX
|
|
|
- if (*excl < 0) /* always true when MDB_USE_POSIX_MUTEX */
|
|
|
-# endif
|
|
|
- {
|
|
|
- lock_info.l_type = F_RDLCK;
|
|
|
- while ((rc = fcntl(env->me_lfd, F_SETLKW, &lock_info)) &&
|
|
|
- (rc = ErrCode()) == EINTR) ;
|
|
|
- if (rc == 0)
|
|
|
- *excl = 0;
|
|
|
- }
|
|
|
-#endif
|
|
|
- return rc;
|
|
|
-}
|
|
|
-
|
|
|
-#ifdef MDB_USE_HASH
|
|
|
-/*
|
|
|
- * hash_64 - 64 bit Fowler/Noll/Vo-0 FNV-1a hash code
|
|
|
- *
|
|
|
- * @(#) $Revision: 5.1 $
|
|
|
- * @(#) $Id: hash_64a.c,v 5.1 2009/06/30 09:01:38 chongo Exp $
|
|
|
- * @(#) $Source: /usr/local/src/cmd/fnv/RCS/hash_64a.c,v $
|
|
|
- *
|
|
|
- * http://www.isthe.com/chongo/tech/comp/fnv/index.html
|
|
|
- *
|
|
|
- ***
|
|
|
- *
|
|
|
- * Please do not copyright this code. This code is in the public domain.
|
|
|
- *
|
|
|
- * LANDON CURT NOLL DISCLAIMS ALL WARRANTIES WITH REGARD TO THIS SOFTWARE,
|
|
|
- * INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS. IN NO
|
|
|
- * EVENT SHALL LANDON CURT NOLL BE LIABLE FOR ANY SPECIAL, INDIRECT OR
|
|
|
- * CONSEQUENTIAL DAMAGES OR ANY DAMAGES WHATSOEVER RESULTING FROM LOSS OF
|
|
|
- * USE, DATA OR PROFITS, WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR
|
|
|
- * OTHER TORTIOUS ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR
|
|
|
- * PERFORMANCE OF THIS SOFTWARE.
|
|
|
- *
|
|
|
- * By:
|
|
|
- * chongo <Landon Curt Noll> /\oo/\
|
|
|
- * http://www.isthe.com/chongo/
|
|
|
- *
|
|
|
- * Share and Enjoy! :-)
|
|
|
- */
|
|
|
-
|
|
|
-typedef unsigned long long mdb_hash_t;
|
|
|
-#define MDB_HASH_INIT ((mdb_hash_t)0xcbf29ce484222325ULL)
|
|
|
-
|
|
|
-/** perform a 64 bit Fowler/Noll/Vo FNV-1a hash on a buffer
|
|
|
- * @param[in] val value to hash
|
|
|
- * @param[in] hval initial value for hash
|
|
|
- * @return 64 bit hash
|
|
|
- *
|
|
|
- * NOTE: To use the recommended 64 bit FNV-1a hash, use MDB_HASH_INIT as the
|
|
|
- * hval arg on the first call.
|
|
|
- */
|
|
|
-static mdb_hash_t
|
|
|
-mdb_hash_val(MDB_val *val, mdb_hash_t hval)
|
|
|
-{
|
|
|
- unsigned char *s = (unsigned char *)val->mv_data; /* unsigned string */
|
|
|
- unsigned char *end = s + val->mv_size;
|
|
|
- /*
|
|
|
- * FNV-1a hash each octet of the string
|
|
|
- */
|
|
|
- while (s < end) {
|
|
|
- /* xor the bottom with the current octet */
|
|
|
- hval ^= (mdb_hash_t)*s++;
|
|
|
-
|
|
|
- /* multiply by the 64 bit FNV magic prime mod 2^64 */
|
|
|
- hval += (hval << 1) + (hval << 4) + (hval << 5) +
|
|
|
- (hval << 7) + (hval << 8) + (hval << 40);
|
|
|
- }
|
|
|
- /* return our new hash value */
|
|
|
- return hval;
|
|
|
-}
|
|
|
-
|
|
|
-/** Hash the string and output the encoded hash.
|
|
|
- * This uses modified RFC1924 Ascii85 encoding to accommodate systems with
|
|
|
- * very short name limits. We don't care about the encoding being reversible,
|
|
|
- * we just want to preserve as many bits of the input as possible in a
|
|
|
- * small printable string.
|
|
|
- * @param[in] str string to hash
|
|
|
- * @param[out] encbuf an array of 11 chars to hold the hash
|
|
|
- */
|
|
|
-static const char mdb_a85[]= "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz!#$%&()*+-;<=>?@^_`{|}~";
|
|
|
-
|
|
|
-static void ESECT
|
|
|
-mdb_pack85(unsigned long l, char *out)
|
|
|
-{
|
|
|
- int i;
|
|
|
-
|
|
|
- for (i=0; i<5; i++) {
|
|
|
- *out++ = mdb_a85[l % 85];
|
|
|
- l /= 85;
|
|
|
- }
|
|
|
-}
|
|
|
-
|
|
|
-static void ESECT
|
|
|
-mdb_hash_enc(MDB_val *val, char *encbuf)
|
|
|
-{
|
|
|
- mdb_hash_t h = mdb_hash_val(val, MDB_HASH_INIT);
|
|
|
-
|
|
|
- mdb_pack85(h, encbuf);
|
|
|
- mdb_pack85(h>>32, encbuf+5);
|
|
|
- encbuf[10] = '\0';
|
|
|
-}
|
|
|
-#endif
|
|
|
-
|
|
|
-/** Open and/or initialize the lock region for the environment.
|
|
|
- * @param[in] env The LMDB environment.
|
|
|
- * @param[in] fname Filename + scratch area, from #mdb_fname_init().
|
|
|
- * @param[in] mode The Unix permissions for the file, if we create it.
|
|
|
- * @param[in,out] excl In -1, out lock type: -1 none, 0 shared, 1 exclusive
|
|
|
- * @return 0 on success, non-zero on failure.
|
|
|
- */
|
|
|
-static int ESECT
|
|
|
-mdb_env_setup_locks(MDB_env *env, MDB_name *fname, int mode, int *excl)
|
|
|
-{
|
|
|
-#ifdef _WIN32
|
|
|
-# define MDB_ERRCODE_ROFS ERROR_WRITE_PROTECT
|
|
|
-#else
|
|
|
-# define MDB_ERRCODE_ROFS EROFS
|
|
|
-#endif
|
|
|
- int rc;
|
|
|
- off_t size, rsize;
|
|
|
-
|
|
|
- rc = mdb_fopen(env, fname, MDB_O_LOCKS, mode, &env->me_lfd);
|
|
|
- if (rc) {
|
|
|
- /* Omit lockfile if read-only env on read-only filesystem */
|
|
|
- if (rc == MDB_ERRCODE_ROFS && (env->me_flags & MDB_RDONLY)) {
|
|
|
- return MDB_SUCCESS;
|
|
|
- }
|
|
|
- goto fail;
|
|
|
- }
|
|
|
-
|
|
|
- if (!(env->me_flags & MDB_NOTLS)) {
|
|
|
- rc = pthread_key_create(&env->me_txkey, mdb_env_reader_dest);
|
|
|
- if (rc)
|
|
|
- goto fail;
|
|
|
- env->me_flags |= MDB_ENV_TXKEY;
|
|
|
-#ifdef _WIN32
|
|
|
- /* Windows TLS callbacks need help finding their TLS info. */
|
|
|
- if (mdb_tls_nkeys >= MAX_TLS_KEYS) {
|
|
|
- rc = MDB_TLS_FULL;
|
|
|
- goto fail;
|
|
|
- }
|
|
|
- mdb_tls_keys[mdb_tls_nkeys++] = env->me_txkey;
|
|
|
-#endif
|
|
|
- }
|
|
|
-
|
|
|
- /* Try to get exclusive lock. If we succeed, then
|
|
|
- * nobody is using the lock region and we should initialize it.
|
|
|
- */
|
|
|
- if ((rc = mdb_env_excl_lock(env, excl))) goto fail;
|
|
|
-
|
|
|
-#ifdef _WIN32
|
|
|
- size = GetFileSize(env->me_lfd, NULL);
|
|
|
-#else
|
|
|
- size = lseek(env->me_lfd, 0, SEEK_END);
|
|
|
- if (size == -1) goto fail_errno;
|
|
|
-#endif
|
|
|
- rsize = (env->me_maxreaders-1) * sizeof(MDB_reader) + sizeof(MDB_txninfo);
|
|
|
- if (size < rsize && *excl > 0) {
|
|
|
-#ifdef _WIN32
|
|
|
- if (SetFilePointer(env->me_lfd, rsize, NULL, FILE_BEGIN) != (DWORD)rsize
|
|
|
- || !SetEndOfFile(env->me_lfd))
|
|
|
- goto fail_errno;
|
|
|
-#else
|
|
|
- if (ftruncate(env->me_lfd, rsize) != 0) goto fail_errno;
|
|
|
-#endif
|
|
|
- } else {
|
|
|
- rsize = size;
|
|
|
- size = rsize - sizeof(MDB_txninfo);
|
|
|
- env->me_maxreaders = size/sizeof(MDB_reader) + 1;
|
|
|
- }
|
|
|
- {
|
|
|
-#ifdef _WIN32
|
|
|
- HANDLE mh;
|
|
|
- mh = CreateFileMapping(env->me_lfd, NULL, PAGE_READWRITE,
|
|
|
- 0, 0, NULL);
|
|
|
- if (!mh) goto fail_errno;
|
|
|
- env->me_txns = MapViewOfFileEx(mh, FILE_MAP_WRITE, 0, 0, rsize, NULL);
|
|
|
- CloseHandle(mh);
|
|
|
- if (!env->me_txns) goto fail_errno;
|
|
|
-#else
|
|
|
- void *m = mmap(NULL, rsize, PROT_READ|PROT_WRITE, MAP_SHARED,
|
|
|
- env->me_lfd, 0);
|
|
|
- if (m == MAP_FAILED) goto fail_errno;
|
|
|
- env->me_txns = m;
|
|
|
-#endif
|
|
|
- }
|
|
|
- if (*excl > 0) {
|
|
|
-#ifdef _WIN32
|
|
|
- BY_HANDLE_FILE_INFORMATION stbuf;
|
|
|
- struct {
|
|
|
- DWORD volume;
|
|
|
- DWORD nhigh;
|
|
|
- DWORD nlow;
|
|
|
- } idbuf;
|
|
|
- MDB_val val;
|
|
|
- char encbuf[11];
|
|
|
-
|
|
|
- if (!mdb_sec_inited) {
|
|
|
- InitializeSecurityDescriptor(&mdb_null_sd,
|
|
|
- SECURITY_DESCRIPTOR_REVISION);
|
|
|
- SetSecurityDescriptorDacl(&mdb_null_sd, TRUE, 0, FALSE);
|
|
|
- mdb_all_sa.nLength = sizeof(SECURITY_ATTRIBUTES);
|
|
|
- mdb_all_sa.bInheritHandle = FALSE;
|
|
|
- mdb_all_sa.lpSecurityDescriptor = &mdb_null_sd;
|
|
|
- mdb_sec_inited = 1;
|
|
|
- }
|
|
|
- if (!GetFileInformationByHandle(env->me_lfd, &stbuf)) goto fail_errno;
|
|
|
- idbuf.volume = stbuf.dwVolumeSerialNumber;
|
|
|
- idbuf.nhigh = stbuf.nFileIndexHigh;
|
|
|
- idbuf.nlow = stbuf.nFileIndexLow;
|
|
|
- val.mv_data = &idbuf;
|
|
|
- val.mv_size = sizeof(idbuf);
|
|
|
- mdb_hash_enc(&val, encbuf);
|
|
|
- sprintf(env->me_txns->mti_rmname, "Global\\MDBr%s", encbuf);
|
|
|
- sprintf(env->me_txns->mti_wmname, "Global\\MDBw%s", encbuf);
|
|
|
- env->me_rmutex = CreateMutexA(&mdb_all_sa, FALSE, env->me_txns->mti_rmname);
|
|
|
- if (!env->me_rmutex) goto fail_errno;
|
|
|
- env->me_wmutex = CreateMutexA(&mdb_all_sa, FALSE, env->me_txns->mti_wmname);
|
|
|
- if (!env->me_wmutex) goto fail_errno;
|
|
|
-#elif defined(MDB_USE_POSIX_SEM)
|
|
|
- struct stat stbuf;
|
|
|
- struct {
|
|
|
- dev_t dev;
|
|
|
- ino_t ino;
|
|
|
- } idbuf;
|
|
|
- MDB_val val;
|
|
|
- char encbuf[11];
|
|
|
-
|
|
|
-#if defined(__NetBSD__)
|
|
|
-#define MDB_SHORT_SEMNAMES 1 /* limited to 14 chars */
|
|
|
-#endif
|
|
|
- if (fstat(env->me_lfd, &stbuf)) goto fail_errno;
|
|
|
- idbuf.dev = stbuf.st_dev;
|
|
|
- idbuf.ino = stbuf.st_ino;
|
|
|
- val.mv_data = &idbuf;
|
|
|
- val.mv_size = sizeof(idbuf);
|
|
|
- mdb_hash_enc(&val, encbuf);
|
|
|
-#ifdef MDB_SHORT_SEMNAMES
|
|
|
- encbuf[9] = '\0'; /* drop name from 15 chars to 14 chars */
|
|
|
-#endif
|
|
|
- sprintf(env->me_txns->mti_rmname, "/MDBr%s", encbuf);
|
|
|
- sprintf(env->me_txns->mti_wmname, "/MDBw%s", encbuf);
|
|
|
- /* Clean up after a previous run, if needed: Try to
|
|
|
- * remove both semaphores before doing anything else.
|
|
|
- */
|
|
|
- sem_unlink(env->me_txns->mti_rmname);
|
|
|
- sem_unlink(env->me_txns->mti_wmname);
|
|
|
- env->me_rmutex = sem_open(env->me_txns->mti_rmname,
|
|
|
- O_CREAT|O_EXCL, mode, 1);
|
|
|
- if (env->me_rmutex == SEM_FAILED) goto fail_errno;
|
|
|
- env->me_wmutex = sem_open(env->me_txns->mti_wmname,
|
|
|
- O_CREAT|O_EXCL, mode, 1);
|
|
|
- if (env->me_wmutex == SEM_FAILED) goto fail_errno;
|
|
|
-#else /* MDB_USE_POSIX_MUTEX: */
|
|
|
- pthread_mutexattr_t mattr;
|
|
|
-
|
|
|
- /* Solaris needs this before initing a robust mutex. Otherwise
|
|
|
- * it may skip the init and return EBUSY "seems someone already
|
|
|
- * inited" or EINVAL "it was inited differently".
|
|
|
- */
|
|
|
- memset(env->me_txns->mti_rmutex, 0, sizeof(*env->me_txns->mti_rmutex));
|
|
|
- memset(env->me_txns->mti_wmutex, 0, sizeof(*env->me_txns->mti_wmutex));
|
|
|
-
|
|
|
- if ((rc = pthread_mutexattr_init(&mattr)))
|
|
|
- goto fail;
|
|
|
-
|
|
|
- rc = pthread_mutexattr_setpshared(&mattr, PTHREAD_PROCESS_SHARED);
|
|
|
-#ifdef MDB_ROBUST_SUPPORTED
|
|
|
- if (!rc) rc = pthread_mutexattr_setrobust(&mattr, PTHREAD_MUTEX_ROBUST);
|
|
|
-#endif
|
|
|
- if (!rc) rc = pthread_mutex_init(env->me_txns->mti_rmutex, &mattr);
|
|
|
- if (!rc) rc = pthread_mutex_init(env->me_txns->mti_wmutex, &mattr);
|
|
|
- pthread_mutexattr_destroy(&mattr);
|
|
|
- if (rc)
|
|
|
- goto fail;
|
|
|
-#endif /* _WIN32 || MDB_USE_POSIX_SEM */
|
|
|
-
|
|
|
- env->me_txns->mti_magic = MDB_MAGIC;
|
|
|
- env->me_txns->mti_format = MDB_LOCK_FORMAT;
|
|
|
- env->me_txns->mti_txnid = 0;
|
|
|
- env->me_txns->mti_numreaders = 0;
|
|
|
-
|
|
|
- } else {
|
|
|
- if (env->me_txns->mti_magic != MDB_MAGIC) {
|
|
|
- DPUTS("lock region has invalid magic");
|
|
|
- rc = MDB_INVALID;
|
|
|
- goto fail;
|
|
|
- }
|
|
|
- if (env->me_txns->mti_format != MDB_LOCK_FORMAT) {
|
|
|
- DPRINTF(("lock region has format+version 0x%x, expected 0x%x",
|
|
|
- env->me_txns->mti_format, MDB_LOCK_FORMAT));
|
|
|
- rc = MDB_VERSION_MISMATCH;
|
|
|
- goto fail;
|
|
|
- }
|
|
|
- rc = ErrCode();
|
|
|
- if (rc && rc != EACCES && rc != EAGAIN) {
|
|
|
- goto fail;
|
|
|
- }
|
|
|
-#ifdef _WIN32
|
|
|
- env->me_rmutex = OpenMutexA(SYNCHRONIZE, FALSE, env->me_txns->mti_rmname);
|
|
|
- if (!env->me_rmutex) goto fail_errno;
|
|
|
- env->me_wmutex = OpenMutexA(SYNCHRONIZE, FALSE, env->me_txns->mti_wmname);
|
|
|
- if (!env->me_wmutex) goto fail_errno;
|
|
|
-#elif defined(MDB_USE_POSIX_SEM)
|
|
|
- env->me_rmutex = sem_open(env->me_txns->mti_rmname, 0);
|
|
|
- if (env->me_rmutex == SEM_FAILED) goto fail_errno;
|
|
|
- env->me_wmutex = sem_open(env->me_txns->mti_wmname, 0);
|
|
|
- if (env->me_wmutex == SEM_FAILED) goto fail_errno;
|
|
|
-#endif
|
|
|
- }
|
|
|
- return MDB_SUCCESS;
|
|
|
-
|
|
|
-fail_errno:
|
|
|
- rc = ErrCode();
|
|
|
-fail:
|
|
|
- return rc;
|
|
|
-}
|
|
|
-
|
|
|
- /** Only a subset of the @ref mdb_env flags can be changed
|
|
|
- * at runtime. Changing other flags requires closing the
|
|
|
- * environment and re-opening it with the new flags.
|
|
|
- */
|
|
|
-#define CHANGEABLE (MDB_NOSYNC|MDB_NOMETASYNC|MDB_MAPASYNC|MDB_NOMEMINIT)
|
|
|
-#define CHANGELESS (MDB_FIXEDMAP|MDB_NOSUBDIR|MDB_RDONLY| \
|
|
|
- MDB_WRITEMAP|MDB_NOTLS|MDB_NOLOCK|MDB_NORDAHEAD)
|
|
|
-
|
|
|
-#if VALID_FLAGS & PERSISTENT_FLAGS & (CHANGEABLE|CHANGELESS)
|
|
|
-# error "Persistent DB flags & env flags overlap, but both go in mm_flags"
|
|
|
-#endif
|
|
|
-
|
|
|
-int ESECT
|
|
|
-mdb_env_open(MDB_env *env, const char *path, unsigned int flags, mdb_mode_t mode)
|
|
|
-{
|
|
|
- int rc, excl = -1;
|
|
|
- MDB_name fname;
|
|
|
-
|
|
|
- if (env->me_fd!=INVALID_HANDLE_VALUE || (flags & ~(CHANGEABLE|CHANGELESS)))
|
|
|
- return EINVAL;
|
|
|
-
|
|
|
- flags |= env->me_flags;
|
|
|
-
|
|
|
- rc = mdb_fname_init(path, flags, &fname);
|
|
|
- if (rc)
|
|
|
- return rc;
|
|
|
-
|
|
|
- if (flags & MDB_RDONLY) {
|
|
|
- /* silently ignore WRITEMAP when we're only getting read access */
|
|
|
- flags &= ~MDB_WRITEMAP;
|
|
|
- } else {
|
|
|
- if (!((env->me_free_pgs = mdb_midl_alloc(MDB_IDL_UM_MAX)) &&
|
|
|
- (env->me_dirty_list = calloc(MDB_IDL_UM_SIZE, sizeof(MDB_ID2)))))
|
|
|
- rc = ENOMEM;
|
|
|
- }
|
|
|
- env->me_flags = flags |= MDB_ENV_ACTIVE;
|
|
|
- if (rc)
|
|
|
- goto leave;
|
|
|
-
|
|
|
- env->me_path = strdup(path);
|
|
|
- env->me_dbxs = calloc(env->me_maxdbs, sizeof(MDB_dbx));
|
|
|
- env->me_dbflags = calloc(env->me_maxdbs, sizeof(uint16_t));
|
|
|
- env->me_dbiseqs = calloc(env->me_maxdbs, sizeof(unsigned int));
|
|
|
- if (!(env->me_dbxs && env->me_path && env->me_dbflags && env->me_dbiseqs)) {
|
|
|
- rc = ENOMEM;
|
|
|
- goto leave;
|
|
|
- }
|
|
|
- env->me_dbxs[FREE_DBI].md_cmp = mdb_cmp_long; /* aligned MDB_INTEGERKEY */
|
|
|
-
|
|
|
- /* For RDONLY, get lockfile after we know datafile exists */
|
|
|
- if (!(flags & (MDB_RDONLY|MDB_NOLOCK))) {
|
|
|
- rc = mdb_env_setup_locks(env, &fname, mode, &excl);
|
|
|
- if (rc)
|
|
|
- goto leave;
|
|
|
- }
|
|
|
-
|
|
|
- rc = mdb_fopen(env, &fname,
|
|
|
- (flags & MDB_RDONLY) ? MDB_O_RDONLY : MDB_O_RDWR,
|
|
|
- mode, &env->me_fd);
|
|
|
- if (rc)
|
|
|
- goto leave;
|
|
|
-
|
|
|
- if ((flags & (MDB_RDONLY|MDB_NOLOCK)) == MDB_RDONLY) {
|
|
|
- rc = mdb_env_setup_locks(env, &fname, mode, &excl);
|
|
|
- if (rc)
|
|
|
- goto leave;
|
|
|
- }
|
|
|
-
|
|
|
- if ((rc = mdb_env_open2(env)) == MDB_SUCCESS) {
|
|
|
- if (!(flags & (MDB_RDONLY|MDB_WRITEMAP))) {
|
|
|
- /* Synchronous fd for meta writes. Needed even with
|
|
|
- * MDB_NOSYNC/MDB_NOMETASYNC, in case these get reset.
|
|
|
- */
|
|
|
- rc = mdb_fopen(env, &fname, MDB_O_META, mode, &env->me_mfd);
|
|
|
- if (rc)
|
|
|
- goto leave;
|
|
|
- }
|
|
|
- DPRINTF(("opened dbenv %p", (void *) env));
|
|
|
- if (excl > 0) {
|
|
|
- rc = mdb_env_share_locks(env, &excl);
|
|
|
- if (rc)
|
|
|
- goto leave;
|
|
|
- }
|
|
|
- if (!(flags & MDB_RDONLY)) {
|
|
|
- MDB_txn *txn;
|
|
|
- int tsize = sizeof(MDB_txn), size = tsize + env->me_maxdbs *
|
|
|
- (sizeof(MDB_db)+sizeof(MDB_cursor *)+sizeof(unsigned int)+1);
|
|
|
- if ((env->me_pbuf = calloc(1, env->me_psize)) &&
|
|
|
- (txn = calloc(1, size)))
|
|
|
- {
|
|
|
- txn->mt_dbs = (MDB_db *)((char *)txn + tsize);
|
|
|
- txn->mt_cursors = (MDB_cursor **)(txn->mt_dbs + env->me_maxdbs);
|
|
|
- txn->mt_dbiseqs = (unsigned int *)(txn->mt_cursors + env->me_maxdbs);
|
|
|
- txn->mt_dbflags = (unsigned char *)(txn->mt_dbiseqs + env->me_maxdbs);
|
|
|
- txn->mt_env = env;
|
|
|
- txn->mt_dbxs = env->me_dbxs;
|
|
|
- txn->mt_flags = MDB_TXN_FINISHED;
|
|
|
- env->me_txn0 = txn;
|
|
|
- } else {
|
|
|
- rc = ENOMEM;
|
|
|
- }
|
|
|
- }
|
|
|
- }
|
|
|
-
|
|
|
-leave:
|
|
|
- if (rc) {
|
|
|
- mdb_env_close0(env, excl);
|
|
|
- }
|
|
|
- mdb_fname_destroy(fname);
|
|
|
- return rc;
|
|
|
-}
|
|
|
-
|
|
|
-/** Destroy resources from mdb_env_open(), clear our readers & DBIs */
|
|
|
-static void ESECT
|
|
|
-mdb_env_close0(MDB_env *env, int excl)
|
|
|
-{
|
|
|
- int i;
|
|
|
-
|
|
|
- if (!(env->me_flags & MDB_ENV_ACTIVE))
|
|
|
- return;
|
|
|
-
|
|
|
- /* Doing this here since me_dbxs may not exist during mdb_env_close */
|
|
|
- if (env->me_dbxs) {
|
|
|
- for (i = env->me_maxdbs; --i >= CORE_DBS; )
|
|
|
- free(env->me_dbxs[i].md_name.mv_data);
|
|
|
- free(env->me_dbxs);
|
|
|
- }
|
|
|
-
|
|
|
- free(env->me_pbuf);
|
|
|
- free(env->me_dbiseqs);
|
|
|
- free(env->me_dbflags);
|
|
|
- free(env->me_path);
|
|
|
- free(env->me_dirty_list);
|
|
|
- free(env->me_txn0);
|
|
|
- mdb_midl_free(env->me_free_pgs);
|
|
|
-
|
|
|
- if (env->me_flags & MDB_ENV_TXKEY) {
|
|
|
- pthread_key_delete(env->me_txkey);
|
|
|
-#ifdef _WIN32
|
|
|
- /* Delete our key from the global list */
|
|
|
- for (i=0; i<mdb_tls_nkeys; i++)
|
|
|
- if (mdb_tls_keys[i] == env->me_txkey) {
|
|
|
- mdb_tls_keys[i] = mdb_tls_keys[mdb_tls_nkeys-1];
|
|
|
- mdb_tls_nkeys--;
|
|
|
- break;
|
|
|
- }
|
|
|
-#endif
|
|
|
- }
|
|
|
-
|
|
|
- if (env->me_map) {
|
|
|
- munmap(env->me_map, env->me_mapsize);
|
|
|
- }
|
|
|
- if (env->me_mfd != INVALID_HANDLE_VALUE)
|
|
|
- (void) close(env->me_mfd);
|
|
|
- if (env->me_fd != INVALID_HANDLE_VALUE)
|
|
|
- (void) close(env->me_fd);
|
|
|
- if (env->me_txns) {
|
|
|
- MDB_PID_T pid = env->me_pid;
|
|
|
- /* Clearing readers is done in this function because
|
|
|
- * me_txkey with its destructor must be disabled first.
|
|
|
- *
|
|
|
- * We skip the the reader mutex, so we touch only
|
|
|
- * data owned by this process (me_close_readers and
|
|
|
- * our readers), and clear each reader atomically.
|
|
|
- */
|
|
|
- for (i = env->me_close_readers; --i >= 0; )
|
|
|
- if (env->me_txns->mti_readers[i].mr_pid == pid)
|
|
|
- env->me_txns->mti_readers[i].mr_pid = 0;
|
|
|
-#ifdef _WIN32
|
|
|
- if (env->me_rmutex) {
|
|
|
- CloseHandle(env->me_rmutex);
|
|
|
- if (env->me_wmutex) CloseHandle(env->me_wmutex);
|
|
|
- }
|
|
|
- /* Windows automatically destroys the mutexes when
|
|
|
- * the last handle closes.
|
|
|
- */
|
|
|
-#elif defined(MDB_USE_POSIX_SEM)
|
|
|
- if (env->me_rmutex != SEM_FAILED) {
|
|
|
- sem_close(env->me_rmutex);
|
|
|
- if (env->me_wmutex != SEM_FAILED)
|
|
|
- sem_close(env->me_wmutex);
|
|
|
- /* If we have the filelock: If we are the
|
|
|
- * only remaining user, clean up semaphores.
|
|
|
- */
|
|
|
- if (excl == 0)
|
|
|
- mdb_env_excl_lock(env, &excl);
|
|
|
- if (excl > 0) {
|
|
|
- sem_unlink(env->me_txns->mti_rmname);
|
|
|
- sem_unlink(env->me_txns->mti_wmname);
|
|
|
- }
|
|
|
- }
|
|
|
-#endif
|
|
|
- munmap((void *)env->me_txns, (env->me_maxreaders-1)*sizeof(MDB_reader)+sizeof(MDB_txninfo));
|
|
|
- }
|
|
|
- if (env->me_lfd != INVALID_HANDLE_VALUE) {
|
|
|
-#ifdef _WIN32
|
|
|
- if (excl >= 0) {
|
|
|
- /* Unlock the lockfile. Windows would have unlocked it
|
|
|
- * after closing anyway, but not necessarily at once.
|
|
|
- */
|
|
|
- UnlockFile(env->me_lfd, 0, 0, 1, 0);
|
|
|
- }
|
|
|
-#endif
|
|
|
- (void) close(env->me_lfd);
|
|
|
- }
|
|
|
-
|
|
|
- env->me_flags &= ~(MDB_ENV_ACTIVE|MDB_ENV_TXKEY);
|
|
|
-}
|
|
|
-
|
|
|
-void ESECT
|
|
|
-mdb_env_close(MDB_env *env)
|
|
|
-{
|
|
|
- MDB_page *dp;
|
|
|
-
|
|
|
- if (env == NULL)
|
|
|
- return;
|
|
|
-
|
|
|
- VGMEMP_DESTROY(env);
|
|
|
- while ((dp = env->me_dpages) != NULL) {
|
|
|
- VGMEMP_DEFINED(&dp->mp_next, sizeof(dp->mp_next));
|
|
|
- env->me_dpages = dp->mp_next;
|
|
|
- free(dp);
|
|
|
- }
|
|
|
-
|
|
|
- mdb_env_close0(env, 0);
|
|
|
- free(env);
|
|
|
-}
|
|
|
-
|
|
|
-/** Compare two items pointing at aligned size_t's */
|
|
|
-static int
|
|
|
-mdb_cmp_long(const MDB_val *a, const MDB_val *b)
|
|
|
-{
|
|
|
- return (*(size_t *)a->mv_data < *(size_t *)b->mv_data) ? -1 :
|
|
|
- *(size_t *)a->mv_data > *(size_t *)b->mv_data;
|
|
|
-}
|
|
|
-
|
|
|
-/** Compare two items pointing at aligned unsigned int's.
|
|
|
- *
|
|
|
- * This is also set as #MDB_INTEGERDUP|#MDB_DUPFIXED's #MDB_dbx.%md_dcmp,
|
|
|
- * but #mdb_cmp_clong() is called instead if the data type is size_t.
|
|
|
- */
|
|
|
-static int
|
|
|
-mdb_cmp_int(const MDB_val *a, const MDB_val *b)
|
|
|
-{
|
|
|
- return (*(unsigned int *)a->mv_data < *(unsigned int *)b->mv_data) ? -1 :
|
|
|
- *(unsigned int *)a->mv_data > *(unsigned int *)b->mv_data;
|
|
|
-}
|
|
|
-
|
|
|
-/** Compare two items pointing at unsigned ints of unknown alignment.
|
|
|
- * Nodes and keys are guaranteed to be 2-byte aligned.
|
|
|
- */
|
|
|
-static int
|
|
|
-mdb_cmp_cint(const MDB_val *a, const MDB_val *b)
|
|
|
-{
|
|
|
-#if BYTE_ORDER == LITTLE_ENDIAN
|
|
|
- unsigned short *u, *c;
|
|
|
- int x;
|
|
|
-
|
|
|
- u = (unsigned short *) ((char *) a->mv_data + a->mv_size);
|
|
|
- c = (unsigned short *) ((char *) b->mv_data + a->mv_size);
|
|
|
- do {
|
|
|
- x = *--u - *--c;
|
|
|
- } while(!x && u > (unsigned short *)a->mv_data);
|
|
|
- return x;
|
|
|
-#else
|
|
|
- unsigned short *u, *c, *end;
|
|
|
- int x;
|
|
|
-
|
|
|
- end = (unsigned short *) ((char *) a->mv_data + a->mv_size);
|
|
|
- u = (unsigned short *)a->mv_data;
|
|
|
- c = (unsigned short *)b->mv_data;
|
|
|
- do {
|
|
|
- x = *u++ - *c++;
|
|
|
- } while(!x && u < end);
|
|
|
- return x;
|
|
|
-#endif
|
|
|
-}
|
|
|
-
|
|
|
-/** Compare two items lexically */
|
|
|
-static int
|
|
|
-mdb_cmp_memn(const MDB_val *a, const MDB_val *b)
|
|
|
-{
|
|
|
- int diff;
|
|
|
- ssize_t len_diff;
|
|
|
- unsigned int len;
|
|
|
-
|
|
|
- len = a->mv_size;
|
|
|
- len_diff = (ssize_t) a->mv_size - (ssize_t) b->mv_size;
|
|
|
- if (len_diff > 0) {
|
|
|
- len = b->mv_size;
|
|
|
- len_diff = 1;
|
|
|
- }
|
|
|
-
|
|
|
- diff = memcmp(a->mv_data, b->mv_data, len);
|
|
|
- return diff ? diff : len_diff<0 ? -1 : len_diff;
|
|
|
-}
|
|
|
-
|
|
|
-/** Compare two items in reverse byte order */
|
|
|
-static int
|
|
|
-mdb_cmp_memnr(const MDB_val *a, const MDB_val *b)
|
|
|
-{
|
|
|
- const unsigned char *p1, *p2, *p1_lim;
|
|
|
- ssize_t len_diff;
|
|
|
- int diff;
|
|
|
-
|
|
|
- p1_lim = (const unsigned char *)a->mv_data;
|
|
|
- p1 = (const unsigned char *)a->mv_data + a->mv_size;
|
|
|
- p2 = (const unsigned char *)b->mv_data + b->mv_size;
|
|
|
-
|
|
|
- len_diff = (ssize_t) a->mv_size - (ssize_t) b->mv_size;
|
|
|
- if (len_diff > 0) {
|
|
|
- p1_lim += len_diff;
|
|
|
- len_diff = 1;
|
|
|
- }
|
|
|
-
|
|
|
- while (p1 > p1_lim) {
|
|
|
- diff = *--p1 - *--p2;
|
|
|
- if (diff)
|
|
|
- return diff;
|
|
|
- }
|
|
|
- return len_diff<0 ? -1 : len_diff;
|
|
|
-}
|
|
|
-
|
|
|
-/** Search for key within a page, using binary search.
|
|
|
- * Returns the smallest entry larger or equal to the key.
|
|
|
- * If exactp is non-null, stores whether the found entry was an exact match
|
|
|
- * in *exactp (1 or 0).
|
|
|
- * Updates the cursor index with the index of the found entry.
|
|
|
- * If no entry larger or equal to the key is found, returns NULL.
|
|
|
- */
|
|
|
-static MDB_node *
|
|
|
-mdb_node_search(MDB_cursor *mc, MDB_val *key, int *exactp)
|
|
|
-{
|
|
|
- unsigned int i = 0, nkeys;
|
|
|
- int low, high;
|
|
|
- int rc = 0;
|
|
|
- MDB_page *mp = mc->mc_pg[mc->mc_top];
|
|
|
- MDB_node *node = NULL;
|
|
|
- MDB_val nodekey;
|
|
|
- MDB_cmp_func *cmp;
|
|
|
- DKBUF;
|
|
|
-
|
|
|
- nkeys = NUMKEYS(mp);
|
|
|
-
|
|
|
- DPRINTF(("searching %u keys in %s %spage %"Z"u",
|
|
|
- nkeys, IS_LEAF(mp) ? "leaf" : "branch", IS_SUBP(mp) ? "sub-" : "",
|
|
|
- mdb_dbg_pgno(mp)));
|
|
|
-
|
|
|
- low = IS_LEAF(mp) ? 0 : 1;
|
|
|
- high = nkeys - 1;
|
|
|
- cmp = mc->mc_dbx->md_cmp;
|
|
|
-
|
|
|
- /* Branch pages have no data, so if using integer keys,
|
|
|
- * alignment is guaranteed. Use faster mdb_cmp_int.
|
|
|
- */
|
|
|
- if (cmp == mdb_cmp_cint && IS_BRANCH(mp)) {
|
|
|
- if (NODEPTR(mp, 1)->mn_ksize == sizeof(size_t))
|
|
|
- cmp = mdb_cmp_long;
|
|
|
- else
|
|
|
- cmp = mdb_cmp_int;
|
|
|
- }
|
|
|
-
|
|
|
- if (IS_LEAF2(mp)) {
|
|
|
- nodekey.mv_size = mc->mc_db->md_pad;
|
|
|
- node = NODEPTR(mp, 0); /* fake */
|
|
|
- while (low <= high) {
|
|
|
- i = (low + high) >> 1;
|
|
|
- nodekey.mv_data = LEAF2KEY(mp, i, nodekey.mv_size);
|
|
|
- rc = cmp(key, &nodekey);
|
|
|
- DPRINTF(("found leaf index %u [%s], rc = %i",
|
|
|
- i, DKEY(&nodekey), rc));
|
|
|
- if (rc == 0)
|
|
|
- break;
|
|
|
- if (rc > 0)
|
|
|
- low = i + 1;
|
|
|
- else
|
|
|
- high = i - 1;
|
|
|
- }
|
|
|
- } else {
|
|
|
- while (low <= high) {
|
|
|
- i = (low + high) >> 1;
|
|
|
-
|
|
|
- node = NODEPTR(mp, i);
|
|
|
- nodekey.mv_size = NODEKSZ(node);
|
|
|
- nodekey.mv_data = NODEKEY(node);
|
|
|
-
|
|
|
- rc = cmp(key, &nodekey);
|
|
|
-#if MDB_DEBUG
|
|
|
- if (IS_LEAF(mp))
|
|
|
- DPRINTF(("found leaf index %u [%s], rc = %i",
|
|
|
- i, DKEY(&nodekey), rc));
|
|
|
- else
|
|
|
- DPRINTF(("found branch index %u [%s -> %"Z"u], rc = %i",
|
|
|
- i, DKEY(&nodekey), NODEPGNO(node), rc));
|
|
|
-#endif
|
|
|
- if (rc == 0)
|
|
|
- break;
|
|
|
- if (rc > 0)
|
|
|
- low = i + 1;
|
|
|
- else
|
|
|
- high = i - 1;
|
|
|
- }
|
|
|
- }
|
|
|
-
|
|
|
- if (rc > 0) { /* Found entry is less than the key. */
|
|
|
- i++; /* Skip to get the smallest entry larger than key. */
|
|
|
- if (!IS_LEAF2(mp))
|
|
|
- node = NODEPTR(mp, i);
|
|
|
- }
|
|
|
- if (exactp)
|
|
|
- *exactp = (rc == 0 && nkeys > 0);
|
|
|
- /* store the key index */
|
|
|
- mc->mc_ki[mc->mc_top] = i;
|
|
|
- if (i >= nkeys)
|
|
|
- /* There is no entry larger or equal to the key. */
|
|
|
- return NULL;
|
|
|
-
|
|
|
- /* nodeptr is fake for LEAF2 */
|
|
|
- return node;
|
|
|
-}
|
|
|
-
|
|
|
-#if 0
|
|
|
-static void
|
|
|
-mdb_cursor_adjust(MDB_cursor *mc, func)
|
|
|
-{
|
|
|
- MDB_cursor *m2;
|
|
|
-
|
|
|
- for (m2 = mc->mc_txn->mt_cursors[mc->mc_dbi]; m2; m2=m2->mc_next) {
|
|
|
- if (m2->mc_pg[m2->mc_top] == mc->mc_pg[mc->mc_top]) {
|
|
|
- func(mc, m2);
|
|
|
- }
|
|
|
- }
|
|
|
-}
|
|
|
-#endif
|
|
|
-
|
|
|
-/** Pop a page off the top of the cursor's stack. */
|
|
|
-static void
|
|
|
-mdb_cursor_pop(MDB_cursor *mc)
|
|
|
-{
|
|
|
- if (mc->mc_snum) {
|
|
|
- DPRINTF(("popping page %"Z"u off db %d cursor %p",
|
|
|
- mc->mc_pg[mc->mc_top]->mp_pgno, DDBI(mc), (void *) mc));
|
|
|
-
|
|
|
- mc->mc_snum--;
|
|
|
- if (mc->mc_snum) {
|
|
|
- mc->mc_top--;
|
|
|
- } else {
|
|
|
- mc->mc_flags &= ~C_INITIALIZED;
|
|
|
- }
|
|
|
- }
|
|
|
-}
|
|
|
-
|
|
|
-/** Push a page onto the top of the cursor's stack.
|
|
|
- * Set #MDB_TXN_ERROR on failure.
|
|
|
- */
|
|
|
-static int
|
|
|
-mdb_cursor_push(MDB_cursor *mc, MDB_page *mp)
|
|
|
-{
|
|
|
- DPRINTF(("pushing page %"Z"u on db %d cursor %p", mp->mp_pgno,
|
|
|
- DDBI(mc), (void *) mc));
|
|
|
-
|
|
|
- if (mc->mc_snum >= CURSOR_STACK) {
|
|
|
- mc->mc_txn->mt_flags |= MDB_TXN_ERROR;
|
|
|
- return MDB_CURSOR_FULL;
|
|
|
- }
|
|
|
-
|
|
|
- mc->mc_top = mc->mc_snum++;
|
|
|
- mc->mc_pg[mc->mc_top] = mp;
|
|
|
- mc->mc_ki[mc->mc_top] = 0;
|
|
|
-
|
|
|
- return MDB_SUCCESS;
|
|
|
-}
|
|
|
-
|
|
|
-/** Find the address of the page corresponding to a given page number.
|
|
|
- * Set #MDB_TXN_ERROR on failure.
|
|
|
- * @param[in] mc the cursor accessing the page.
|
|
|
- * @param[in] pgno the page number for the page to retrieve.
|
|
|
- * @param[out] ret address of a pointer where the page's address will be stored.
|
|
|
- * @param[out] lvl dirty_list inheritance level of found page. 1=current txn, 0=mapped page.
|
|
|
- * @return 0 on success, non-zero on failure.
|
|
|
- */
|
|
|
-static int
|
|
|
-mdb_page_get(MDB_cursor *mc, pgno_t pgno, MDB_page **ret, int *lvl)
|
|
|
-{
|
|
|
- MDB_txn *txn = mc->mc_txn;
|
|
|
- MDB_env *env = txn->mt_env;
|
|
|
- MDB_page *p = NULL;
|
|
|
- int level;
|
|
|
-
|
|
|
- if (! (txn->mt_flags & (MDB_TXN_RDONLY|MDB_TXN_WRITEMAP))) {
|
|
|
- MDB_txn *tx2 = txn;
|
|
|
- level = 1;
|
|
|
- do {
|
|
|
- MDB_ID2L dl = tx2->mt_u.dirty_list;
|
|
|
- unsigned x;
|
|
|
- /* Spilled pages were dirtied in this txn and flushed
|
|
|
- * because the dirty list got full. Bring this page
|
|
|
- * back in from the map (but don't unspill it here,
|
|
|
- * leave that unless page_touch happens again).
|
|
|
- */
|
|
|
- if (tx2->mt_spill_pgs) {
|
|
|
- MDB_ID pn = pgno << 1;
|
|
|
- x = mdb_midl_search(tx2->mt_spill_pgs, pn);
|
|
|
- if (x <= tx2->mt_spill_pgs[0] && tx2->mt_spill_pgs[x] == pn) {
|
|
|
- p = (MDB_page *)(env->me_map + env->me_psize * pgno);
|
|
|
- goto done;
|
|
|
- }
|
|
|
- }
|
|
|
- if (dl[0].mid) {
|
|
|
- unsigned x = mdb_mid2l_search(dl, pgno);
|
|
|
- if (x <= dl[0].mid && dl[x].mid == pgno) {
|
|
|
- p = dl[x].mptr;
|
|
|
- goto done;
|
|
|
- }
|
|
|
- }
|
|
|
- level++;
|
|
|
- } while ((tx2 = tx2->mt_parent) != NULL);
|
|
|
- }
|
|
|
-
|
|
|
- if (pgno < txn->mt_next_pgno) {
|
|
|
- level = 0;
|
|
|
- p = (MDB_page *)(env->me_map + env->me_psize * pgno);
|
|
|
- } else {
|
|
|
- DPRINTF(("page %"Z"u not found", pgno));
|
|
|
- txn->mt_flags |= MDB_TXN_ERROR;
|
|
|
- return MDB_PAGE_NOTFOUND;
|
|
|
- }
|
|
|
-
|
|
|
-done:
|
|
|
- *ret = p;
|
|
|
- if (lvl)
|
|
|
- *lvl = level;
|
|
|
- return MDB_SUCCESS;
|
|
|
-}
|
|
|
-
|
|
|
-/** Finish #mdb_page_search() / #mdb_page_search_lowest().
|
|
|
- * The cursor is at the root page, set up the rest of it.
|
|
|
- */
|
|
|
-static int
|
|
|
-mdb_page_search_root(MDB_cursor *mc, MDB_val *key, int flags)
|
|
|
-{
|
|
|
- MDB_page *mp = mc->mc_pg[mc->mc_top];
|
|
|
- int rc;
|
|
|
- DKBUF;
|
|
|
-
|
|
|
- while (IS_BRANCH(mp)) {
|
|
|
- MDB_node *node;
|
|
|
- indx_t i;
|
|
|
-
|
|
|
- DPRINTF(("branch page %"Z"u has %u keys", mp->mp_pgno, NUMKEYS(mp)));
|
|
|
- /* Don't assert on branch pages in the FreeDB. We can get here
|
|
|
- * while in the process of rebalancing a FreeDB branch page; we must
|
|
|
- * let that proceed. ITS#8336
|
|
|
- */
|
|
|
- mdb_cassert(mc, !mc->mc_dbi || NUMKEYS(mp) > 1);
|
|
|
- DPRINTF(("found index 0 to page %"Z"u", NODEPGNO(NODEPTR(mp, 0))));
|
|
|
-
|
|
|
- if (flags & (MDB_PS_FIRST|MDB_PS_LAST)) {
|
|
|
- i = 0;
|
|
|
- if (flags & MDB_PS_LAST) {
|
|
|
- i = NUMKEYS(mp) - 1;
|
|
|
- /* if already init'd, see if we're already in right place */
|
|
|
- if (mc->mc_flags & C_INITIALIZED) {
|
|
|
- if (mc->mc_ki[mc->mc_top] == i) {
|
|
|
- mc->mc_top = mc->mc_snum++;
|
|
|
- mp = mc->mc_pg[mc->mc_top];
|
|
|
- goto ready;
|
|
|
- }
|
|
|
- }
|
|
|
- }
|
|
|
- } else {
|
|
|
- int exact;
|
|
|
- node = mdb_node_search(mc, key, &exact);
|
|
|
- if (node == NULL)
|
|
|
- i = NUMKEYS(mp) - 1;
|
|
|
- else {
|
|
|
- i = mc->mc_ki[mc->mc_top];
|
|
|
- if (!exact) {
|
|
|
- mdb_cassert(mc, i > 0);
|
|
|
- i--;
|
|
|
- }
|
|
|
- }
|
|
|
- DPRINTF(("following index %u for key [%s]", i, DKEY(key)));
|
|
|
- }
|
|
|
-
|
|
|
- mdb_cassert(mc, i < NUMKEYS(mp));
|
|
|
- node = NODEPTR(mp, i);
|
|
|
-
|
|
|
- if ((rc = mdb_page_get(mc, NODEPGNO(node), &mp, NULL)) != 0)
|
|
|
- return rc;
|
|
|
-
|
|
|
- mc->mc_ki[mc->mc_top] = i;
|
|
|
- if ((rc = mdb_cursor_push(mc, mp)))
|
|
|
- return rc;
|
|
|
-
|
|
|
-ready:
|
|
|
- if (flags & MDB_PS_MODIFY) {
|
|
|
- if ((rc = mdb_page_touch(mc)) != 0)
|
|
|
- return rc;
|
|
|
- mp = mc->mc_pg[mc->mc_top];
|
|
|
- }
|
|
|
- }
|
|
|
-
|
|
|
- if (!IS_LEAF(mp)) {
|
|
|
- DPRINTF(("internal error, index points to a %02X page!?",
|
|
|
- mp->mp_flags));
|
|
|
- mc->mc_txn->mt_flags |= MDB_TXN_ERROR;
|
|
|
- return MDB_CORRUPTED;
|
|
|
- }
|
|
|
-
|
|
|
- DPRINTF(("found leaf page %"Z"u for key [%s]", mp->mp_pgno,
|
|
|
- key ? DKEY(key) : "null"));
|
|
|
- mc->mc_flags |= C_INITIALIZED;
|
|
|
- mc->mc_flags &= ~C_EOF;
|
|
|
-
|
|
|
- return MDB_SUCCESS;
|
|
|
-}
|
|
|
-
|
|
|
-/** Search for the lowest key under the current branch page.
|
|
|
- * This just bypasses a NUMKEYS check in the current page
|
|
|
- * before calling mdb_page_search_root(), because the callers
|
|
|
- * are all in situations where the current page is known to
|
|
|
- * be underfilled.
|
|
|
- */
|
|
|
-static int
|
|
|
-mdb_page_search_lowest(MDB_cursor *mc)
|
|
|
-{
|
|
|
- MDB_page *mp = mc->mc_pg[mc->mc_top];
|
|
|
- MDB_node *node = NODEPTR(mp, 0);
|
|
|
- int rc;
|
|
|
-
|
|
|
- if ((rc = mdb_page_get(mc, NODEPGNO(node), &mp, NULL)) != 0)
|
|
|
- return rc;
|
|
|
-
|
|
|
- mc->mc_ki[mc->mc_top] = 0;
|
|
|
- if ((rc = mdb_cursor_push(mc, mp)))
|
|
|
- return rc;
|
|
|
- return mdb_page_search_root(mc, NULL, MDB_PS_FIRST);
|
|
|
-}
|
|
|
-
|
|
|
-/** Search for the page a given key should be in.
|
|
|
- * Push it and its parent pages on the cursor stack.
|
|
|
- * @param[in,out] mc the cursor for this operation.
|
|
|
- * @param[in] key the key to search for, or NULL for first/last page.
|
|
|
- * @param[in] flags If MDB_PS_MODIFY is set, visited pages in the DB
|
|
|
- * are touched (updated with new page numbers).
|
|
|
- * If MDB_PS_FIRST or MDB_PS_LAST is set, find first or last leaf.
|
|
|
- * This is used by #mdb_cursor_first() and #mdb_cursor_last().
|
|
|
- * If MDB_PS_ROOTONLY set, just fetch root node, no further lookups.
|
|
|
- * @return 0 on success, non-zero on failure.
|
|
|
- */
|
|
|
-static int
|
|
|
-mdb_page_search(MDB_cursor *mc, MDB_val *key, int flags)
|
|
|
-{
|
|
|
- int rc;
|
|
|
- pgno_t root;
|
|
|
-
|
|
|
- /* Make sure the txn is still viable, then find the root from
|
|
|
- * the txn's db table and set it as the root of the cursor's stack.
|
|
|
- */
|
|
|
- if (mc->mc_txn->mt_flags & MDB_TXN_BLOCKED) {
|
|
|
- DPUTS("transaction may not be used now");
|
|
|
- return MDB_BAD_TXN;
|
|
|
- } else {
|
|
|
- /* Make sure we're using an up-to-date root */
|
|
|
- if (*mc->mc_dbflag & DB_STALE) {
|
|
|
- MDB_cursor mc2;
|
|
|
- if (TXN_DBI_CHANGED(mc->mc_txn, mc->mc_dbi))
|
|
|
- return MDB_BAD_DBI;
|
|
|
- mdb_cursor_init(&mc2, mc->mc_txn, MAIN_DBI, NULL);
|
|
|
- rc = mdb_page_search(&mc2, &mc->mc_dbx->md_name, 0);
|
|
|
- if (rc)
|
|
|
- return rc;
|
|
|
- {
|
|
|
- MDB_val data;
|
|
|
- int exact = 0;
|
|
|
- uint16_t flags;
|
|
|
- MDB_node *leaf = mdb_node_search(&mc2,
|
|
|
- &mc->mc_dbx->md_name, &exact);
|
|
|
- if (!exact)
|
|
|
- return MDB_NOTFOUND;
|
|
|
- if ((leaf->mn_flags & (F_DUPDATA|F_SUBDATA)) != F_SUBDATA)
|
|
|
- return MDB_INCOMPATIBLE; /* not a named DB */
|
|
|
- rc = mdb_node_read(&mc2, leaf, &data);
|
|
|
- if (rc)
|
|
|
- return rc;
|
|
|
- memcpy(&flags, ((char *) data.mv_data + offsetof(MDB_db, md_flags)),
|
|
|
- sizeof(uint16_t));
|
|
|
- /* The txn may not know this DBI, or another process may
|
|
|
- * have dropped and recreated the DB with other flags.
|
|
|
- */
|
|
|
- if ((mc->mc_db->md_flags & PERSISTENT_FLAGS) != flags)
|
|
|
- return MDB_INCOMPATIBLE;
|
|
|
- memcpy(mc->mc_db, data.mv_data, sizeof(MDB_db));
|
|
|
- }
|
|
|
- *mc->mc_dbflag &= ~DB_STALE;
|
|
|
- }
|
|
|
- root = mc->mc_db->md_root;
|
|
|
-
|
|
|
- if (root == P_INVALID) { /* Tree is empty. */
|
|
|
- DPUTS("tree is empty");
|
|
|
- return MDB_NOTFOUND;
|
|
|
- }
|
|
|
- }
|
|
|
-
|
|
|
- mdb_cassert(mc, root > 1);
|
|
|
- if (!mc->mc_pg[0] || mc->mc_pg[0]->mp_pgno != root)
|
|
|
- if ((rc = mdb_page_get(mc, root, &mc->mc_pg[0], NULL)) != 0)
|
|
|
- return rc;
|
|
|
-
|
|
|
- mc->mc_snum = 1;
|
|
|
- mc->mc_top = 0;
|
|
|
-
|
|
|
- DPRINTF(("db %d root page %"Z"u has flags 0x%X",
|
|
|
- DDBI(mc), root, mc->mc_pg[0]->mp_flags));
|
|
|
-
|
|
|
- if (flags & MDB_PS_MODIFY) {
|
|
|
- if ((rc = mdb_page_touch(mc)))
|
|
|
- return rc;
|
|
|
- }
|
|
|
-
|
|
|
- if (flags & MDB_PS_ROOTONLY)
|
|
|
- return MDB_SUCCESS;
|
|
|
-
|
|
|
- return mdb_page_search_root(mc, key, flags);
|
|
|
-}
|
|
|
-
|
|
|
-static int
|
|
|
-mdb_ovpage_free(MDB_cursor *mc, MDB_page *mp)
|
|
|
-{
|
|
|
- MDB_txn *txn = mc->mc_txn;
|
|
|
- pgno_t pg = mp->mp_pgno;
|
|
|
- unsigned x = 0, ovpages = mp->mp_pages;
|
|
|
- MDB_env *env = txn->mt_env;
|
|
|
- MDB_IDL sl = txn->mt_spill_pgs;
|
|
|
- MDB_ID pn = pg << 1;
|
|
|
- int rc;
|
|
|
-
|
|
|
- DPRINTF(("free ov page %"Z"u (%d)", pg, ovpages));
|
|
|
- /* If the page is dirty or on the spill list we just acquired it,
|
|
|
- * so we should give it back to our current free list, if any.
|
|
|
- * Otherwise put it onto the list of pages we freed in this txn.
|
|
|
- *
|
|
|
- * Won't create me_pghead: me_pglast must be inited along with it.
|
|
|
- * Unsupported in nested txns: They would need to hide the page
|
|
|
- * range in ancestor txns' dirty and spilled lists.
|
|
|
- */
|
|
|
- if (env->me_pghead &&
|
|
|
- !txn->mt_parent &&
|
|
|
- ((mp->mp_flags & P_DIRTY) ||
|
|
|
- (sl && (x = mdb_midl_search(sl, pn)) <= sl[0] && sl[x] == pn)))
|
|
|
- {
|
|
|
- unsigned i, j;
|
|
|
- pgno_t *mop;
|
|
|
- MDB_ID2 *dl, ix, iy;
|
|
|
- rc = mdb_midl_need(&env->me_pghead, ovpages);
|
|
|
- if (rc)
|
|
|
- return rc;
|
|
|
- if (!(mp->mp_flags & P_DIRTY)) {
|
|
|
- /* This page is no longer spilled */
|
|
|
- if (x == sl[0])
|
|
|
- sl[0]--;
|
|
|
- else
|
|
|
- sl[x] |= 1;
|
|
|
- goto release;
|
|
|
- }
|
|
|
- /* Remove from dirty list */
|
|
|
- dl = txn->mt_u.dirty_list;
|
|
|
- x = dl[0].mid--;
|
|
|
- for (ix = dl[x]; ix.mptr != mp; ix = iy) {
|
|
|
- if (x > 1) {
|
|
|
- x--;
|
|
|
- iy = dl[x];
|
|
|
- dl[x] = ix;
|
|
|
- } else {
|
|
|
- mdb_cassert(mc, x > 1);
|
|
|
- j = ++(dl[0].mid);
|
|
|
- dl[j] = ix; /* Unsorted. OK when MDB_TXN_ERROR. */
|
|
|
- txn->mt_flags |= MDB_TXN_ERROR;
|
|
|
- return MDB_CORRUPTED;
|
|
|
- }
|
|
|
- }
|
|
|
- txn->mt_dirty_room++;
|
|
|
- if (!(env->me_flags & MDB_WRITEMAP))
|
|
|
- mdb_dpage_free(env, mp);
|
|
|
-release:
|
|
|
- /* Insert in me_pghead */
|
|
|
- mop = env->me_pghead;
|
|
|
- j = mop[0] + ovpages;
|
|
|
- for (i = mop[0]; i && mop[i] < pg; i--)
|
|
|
- mop[j--] = mop[i];
|
|
|
- while (j>i)
|
|
|
- mop[j--] = pg++;
|
|
|
- mop[0] += ovpages;
|
|
|
- } else {
|
|
|
- rc = mdb_midl_append_range(&txn->mt_free_pgs, pg, ovpages);
|
|
|
- if (rc)
|
|
|
- return rc;
|
|
|
- }
|
|
|
- mc->mc_db->md_overflow_pages -= ovpages;
|
|
|
- return 0;
|
|
|
-}
|
|
|
-
|
|
|
-/** Return the data associated with a given node.
|
|
|
- * @param[in] mc The cursor for this operation.
|
|
|
- * @param[in] leaf The node being read.
|
|
|
- * @param[out] data Updated to point to the node's data.
|
|
|
- * @return 0 on success, non-zero on failure.
|
|
|
- */
|
|
|
-static int
|
|
|
-mdb_node_read(MDB_cursor *mc, MDB_node *leaf, MDB_val *data)
|
|
|
-{
|
|
|
- MDB_page *omp; /* overflow page */
|
|
|
- pgno_t pgno;
|
|
|
- int rc;
|
|
|
-
|
|
|
- if (!F_ISSET(leaf->mn_flags, F_BIGDATA)) {
|
|
|
- data->mv_size = NODEDSZ(leaf);
|
|
|
- data->mv_data = NODEDATA(leaf);
|
|
|
- return MDB_SUCCESS;
|
|
|
- }
|
|
|
-
|
|
|
- /* Read overflow data.
|
|
|
- */
|
|
|
- data->mv_size = NODEDSZ(leaf);
|
|
|
- memcpy(&pgno, NODEDATA(leaf), sizeof(pgno));
|
|
|
- if ((rc = mdb_page_get(mc, pgno, &omp, NULL)) != 0) {
|
|
|
- DPRINTF(("read overflow page %"Z"u failed", pgno));
|
|
|
- return rc;
|
|
|
- }
|
|
|
- data->mv_data = METADATA(omp);
|
|
|
-
|
|
|
- return MDB_SUCCESS;
|
|
|
-}
|
|
|
-
|
|
|
-int
|
|
|
-mdb_get(MDB_txn *txn, MDB_dbi dbi,
|
|
|
- MDB_val *key, MDB_val *data)
|
|
|
-{
|
|
|
- MDB_cursor mc;
|
|
|
- MDB_xcursor mx;
|
|
|
- int exact = 0;
|
|
|
- DKBUF;
|
|
|
-
|
|
|
- DPRINTF(("===> get db %u key [%s]", dbi, DKEY(key)));
|
|
|
-
|
|
|
- if (!key || !data || !TXN_DBI_EXIST(txn, dbi, DB_USRVALID))
|
|
|
- return EINVAL;
|
|
|
-
|
|
|
- if (txn->mt_flags & MDB_TXN_BLOCKED)
|
|
|
- return MDB_BAD_TXN;
|
|
|
-
|
|
|
- mdb_cursor_init(&mc, txn, dbi, &mx);
|
|
|
- return mdb_cursor_set(&mc, key, data, MDB_SET, &exact);
|
|
|
-}
|
|
|
-
|
|
|
-/** Find a sibling for a page.
|
|
|
- * Replaces the page at the top of the cursor's stack with the
|
|
|
- * specified sibling, if one exists.
|
|
|
- * @param[in] mc The cursor for this operation.
|
|
|
- * @param[in] move_right Non-zero if the right sibling is requested,
|
|
|
- * otherwise the left sibling.
|
|
|
- * @return 0 on success, non-zero on failure.
|
|
|
- */
|
|
|
-static int
|
|
|
-mdb_cursor_sibling(MDB_cursor *mc, int move_right)
|
|
|
-{
|
|
|
- int rc;
|
|
|
- MDB_node *indx;
|
|
|
- MDB_page *mp;
|
|
|
-
|
|
|
- if (mc->mc_snum < 2) {
|
|
|
- return MDB_NOTFOUND; /* root has no siblings */
|
|
|
- }
|
|
|
-
|
|
|
- mdb_cursor_pop(mc);
|
|
|
- DPRINTF(("parent page is page %"Z"u, index %u",
|
|
|
- mc->mc_pg[mc->mc_top]->mp_pgno, mc->mc_ki[mc->mc_top]));
|
|
|
-
|
|
|
- if (move_right ? (mc->mc_ki[mc->mc_top] + 1u >= NUMKEYS(mc->mc_pg[mc->mc_top]))
|
|
|
- : (mc->mc_ki[mc->mc_top] == 0)) {
|
|
|
- DPRINTF(("no more keys left, moving to %s sibling",
|
|
|
- move_right ? "right" : "left"));
|
|
|
- if ((rc = mdb_cursor_sibling(mc, move_right)) != MDB_SUCCESS) {
|
|
|
- /* undo cursor_pop before returning */
|
|
|
- mc->mc_top++;
|
|
|
- mc->mc_snum++;
|
|
|
- return rc;
|
|
|
- }
|
|
|
- } else {
|
|
|
- if (move_right)
|
|
|
- mc->mc_ki[mc->mc_top]++;
|
|
|
- else
|
|
|
- mc->mc_ki[mc->mc_top]--;
|
|
|
- DPRINTF(("just moving to %s index key %u",
|
|
|
- move_right ? "right" : "left", mc->mc_ki[mc->mc_top]));
|
|
|
- }
|
|
|
- mdb_cassert(mc, IS_BRANCH(mc->mc_pg[mc->mc_top]));
|
|
|
-
|
|
|
- indx = NODEPTR(mc->mc_pg[mc->mc_top], mc->mc_ki[mc->mc_top]);
|
|
|
- if ((rc = mdb_page_get(mc, NODEPGNO(indx), &mp, NULL)) != 0) {
|
|
|
- /* mc will be inconsistent if caller does mc_snum++ as above */
|
|
|
- mc->mc_flags &= ~(C_INITIALIZED|C_EOF);
|
|
|
- return rc;
|
|
|
- }
|
|
|
-
|
|
|
- mdb_cursor_push(mc, mp);
|
|
|
- if (!move_right)
|
|
|
- mc->mc_ki[mc->mc_top] = NUMKEYS(mp)-1;
|
|
|
-
|
|
|
- return MDB_SUCCESS;
|
|
|
-}
|
|
|
-
|
|
|
-/** Move the cursor to the next data item. */
|
|
|
-static int
|
|
|
-mdb_cursor_next(MDB_cursor *mc, MDB_val *key, MDB_val *data, MDB_cursor_op op)
|
|
|
-{
|
|
|
- MDB_page *mp;
|
|
|
- MDB_node *leaf;
|
|
|
- int rc;
|
|
|
-
|
|
|
- if ((mc->mc_flags & C_DEL && op == MDB_NEXT_DUP))
|
|
|
- return MDB_NOTFOUND;
|
|
|
-
|
|
|
- if (!(mc->mc_flags & C_INITIALIZED))
|
|
|
- return mdb_cursor_first(mc, key, data);
|
|
|
-
|
|
|
- mp = mc->mc_pg[mc->mc_top];
|
|
|
-
|
|
|
- if (mc->mc_flags & C_EOF) {
|
|
|
- if (mc->mc_ki[mc->mc_top] >= NUMKEYS(mp)-1)
|
|
|
- return MDB_NOTFOUND;
|
|
|
- mc->mc_flags ^= C_EOF;
|
|
|
- }
|
|
|
-
|
|
|
- if (mc->mc_db->md_flags & MDB_DUPSORT) {
|
|
|
- leaf = NODEPTR(mp, mc->mc_ki[mc->mc_top]);
|
|
|
- if (F_ISSET(leaf->mn_flags, F_DUPDATA)) {
|
|
|
- if (op == MDB_NEXT || op == MDB_NEXT_DUP) {
|
|
|
- rc = mdb_cursor_next(&mc->mc_xcursor->mx_cursor, data, NULL, MDB_NEXT);
|
|
|
- if (op != MDB_NEXT || rc != MDB_NOTFOUND) {
|
|
|
- if (rc == MDB_SUCCESS)
|
|
|
- MDB_GET_KEY(leaf, key);
|
|
|
- return rc;
|
|
|
- }
|
|
|
- }
|
|
|
- } else {
|
|
|
- mc->mc_xcursor->mx_cursor.mc_flags &= ~(C_INITIALIZED|C_EOF);
|
|
|
- if (op == MDB_NEXT_DUP)
|
|
|
- return MDB_NOTFOUND;
|
|
|
- }
|
|
|
- }
|
|
|
-
|
|
|
- DPRINTF(("cursor_next: top page is %"Z"u in cursor %p",
|
|
|
- mdb_dbg_pgno(mp), (void *) mc));
|
|
|
- if (mc->mc_flags & C_DEL) {
|
|
|
- mc->mc_flags ^= C_DEL;
|
|
|
- goto skip;
|
|
|
- }
|
|
|
-
|
|
|
- if (mc->mc_ki[mc->mc_top] + 1u >= NUMKEYS(mp)) {
|
|
|
- DPUTS("=====> move to next sibling page");
|
|
|
- if ((rc = mdb_cursor_sibling(mc, 1)) != MDB_SUCCESS) {
|
|
|
- mc->mc_flags |= C_EOF;
|
|
|
- return rc;
|
|
|
- }
|
|
|
- mp = mc->mc_pg[mc->mc_top];
|
|
|
- DPRINTF(("next page is %"Z"u, key index %u", mp->mp_pgno, mc->mc_ki[mc->mc_top]));
|
|
|
- } else
|
|
|
- mc->mc_ki[mc->mc_top]++;
|
|
|
-
|
|
|
-skip:
|
|
|
- DPRINTF(("==> cursor points to page %"Z"u with %u keys, key index %u",
|
|
|
- mdb_dbg_pgno(mp), NUMKEYS(mp), mc->mc_ki[mc->mc_top]));
|
|
|
-
|
|
|
- if (IS_LEAF2(mp)) {
|
|
|
- key->mv_size = mc->mc_db->md_pad;
|
|
|
- key->mv_data = LEAF2KEY(mp, mc->mc_ki[mc->mc_top], key->mv_size);
|
|
|
- return MDB_SUCCESS;
|
|
|
- }
|
|
|
-
|
|
|
- mdb_cassert(mc, IS_LEAF(mp));
|
|
|
- leaf = NODEPTR(mp, mc->mc_ki[mc->mc_top]);
|
|
|
-
|
|
|
- if (F_ISSET(leaf->mn_flags, F_DUPDATA)) {
|
|
|
- mdb_xcursor_init1(mc, leaf);
|
|
|
- }
|
|
|
- if (data) {
|
|
|
- if ((rc = mdb_node_read(mc, leaf, data)) != MDB_SUCCESS)
|
|
|
- return rc;
|
|
|
-
|
|
|
- if (F_ISSET(leaf->mn_flags, F_DUPDATA)) {
|
|
|
- rc = mdb_cursor_first(&mc->mc_xcursor->mx_cursor, data, NULL);
|
|
|
- if (rc != MDB_SUCCESS)
|
|
|
- return rc;
|
|
|
- }
|
|
|
- }
|
|
|
-
|
|
|
- MDB_GET_KEY(leaf, key);
|
|
|
- return MDB_SUCCESS;
|
|
|
-}
|
|
|
-
|
|
|
-/** Move the cursor to the previous data item. */
|
|
|
-static int
|
|
|
-mdb_cursor_prev(MDB_cursor *mc, MDB_val *key, MDB_val *data, MDB_cursor_op op)
|
|
|
-{
|
|
|
- MDB_page *mp;
|
|
|
- MDB_node *leaf;
|
|
|
- int rc;
|
|
|
-
|
|
|
- if (!(mc->mc_flags & C_INITIALIZED)) {
|
|
|
- rc = mdb_cursor_last(mc, key, data);
|
|
|
- if (rc)
|
|
|
- return rc;
|
|
|
- mc->mc_ki[mc->mc_top]++;
|
|
|
- }
|
|
|
-
|
|
|
- mp = mc->mc_pg[mc->mc_top];
|
|
|
-
|
|
|
- if (mc->mc_db->md_flags & MDB_DUPSORT) {
|
|
|
- leaf = NODEPTR(mp, mc->mc_ki[mc->mc_top]);
|
|
|
- if (F_ISSET(leaf->mn_flags, F_DUPDATA)) {
|
|
|
- if (op == MDB_PREV || op == MDB_PREV_DUP) {
|
|
|
- rc = mdb_cursor_prev(&mc->mc_xcursor->mx_cursor, data, NULL, MDB_PREV);
|
|
|
- if (op != MDB_PREV || rc != MDB_NOTFOUND) {
|
|
|
- if (rc == MDB_SUCCESS) {
|
|
|
- MDB_GET_KEY(leaf, key);
|
|
|
- mc->mc_flags &= ~C_EOF;
|
|
|
- }
|
|
|
- return rc;
|
|
|
- }
|
|
|
- }
|
|
|
- } else {
|
|
|
- mc->mc_xcursor->mx_cursor.mc_flags &= ~(C_INITIALIZED|C_EOF);
|
|
|
- if (op == MDB_PREV_DUP)
|
|
|
- return MDB_NOTFOUND;
|
|
|
- }
|
|
|
- }
|
|
|
-
|
|
|
- DPRINTF(("cursor_prev: top page is %"Z"u in cursor %p",
|
|
|
- mdb_dbg_pgno(mp), (void *) mc));
|
|
|
-
|
|
|
- mc->mc_flags &= ~(C_EOF|C_DEL);
|
|
|
-
|
|
|
- if (mc->mc_ki[mc->mc_top] == 0) {
|
|
|
- DPUTS("=====> move to prev sibling page");
|
|
|
- if ((rc = mdb_cursor_sibling(mc, 0)) != MDB_SUCCESS) {
|
|
|
- return rc;
|
|
|
- }
|
|
|
- mp = mc->mc_pg[mc->mc_top];
|
|
|
- mc->mc_ki[mc->mc_top] = NUMKEYS(mp) - 1;
|
|
|
- DPRINTF(("prev page is %"Z"u, key index %u", mp->mp_pgno, mc->mc_ki[mc->mc_top]));
|
|
|
- } else
|
|
|
- mc->mc_ki[mc->mc_top]--;
|
|
|
-
|
|
|
- DPRINTF(("==> cursor points to page %"Z"u with %u keys, key index %u",
|
|
|
- mdb_dbg_pgno(mp), NUMKEYS(mp), mc->mc_ki[mc->mc_top]));
|
|
|
-
|
|
|
- if (IS_LEAF2(mp)) {
|
|
|
- key->mv_size = mc->mc_db->md_pad;
|
|
|
- key->mv_data = LEAF2KEY(mp, mc->mc_ki[mc->mc_top], key->mv_size);
|
|
|
- return MDB_SUCCESS;
|
|
|
- }
|
|
|
-
|
|
|
- mdb_cassert(mc, IS_LEAF(mp));
|
|
|
- leaf = NODEPTR(mp, mc->mc_ki[mc->mc_top]);
|
|
|
-
|
|
|
- if (F_ISSET(leaf->mn_flags, F_DUPDATA)) {
|
|
|
- mdb_xcursor_init1(mc, leaf);
|
|
|
- }
|
|
|
- if (data) {
|
|
|
- if ((rc = mdb_node_read(mc, leaf, data)) != MDB_SUCCESS)
|
|
|
- return rc;
|
|
|
-
|
|
|
- if (F_ISSET(leaf->mn_flags, F_DUPDATA)) {
|
|
|
- rc = mdb_cursor_last(&mc->mc_xcursor->mx_cursor, data, NULL);
|
|
|
- if (rc != MDB_SUCCESS)
|
|
|
- return rc;
|
|
|
- }
|
|
|
- }
|
|
|
-
|
|
|
- MDB_GET_KEY(leaf, key);
|
|
|
- return MDB_SUCCESS;
|
|
|
-}
|
|
|
-
|
|
|
-/** Set the cursor on a specific data item. */
|
|
|
-static int
|
|
|
-mdb_cursor_set(MDB_cursor *mc, MDB_val *key, MDB_val *data,
|
|
|
- MDB_cursor_op op, int *exactp)
|
|
|
-{
|
|
|
- int rc;
|
|
|
- MDB_page *mp;
|
|
|
- MDB_node *leaf = NULL;
|
|
|
- DKBUF;
|
|
|
-
|
|
|
- if (key->mv_size == 0)
|
|
|
- return MDB_BAD_VALSIZE;
|
|
|
-
|
|
|
- if (mc->mc_xcursor)
|
|
|
- mc->mc_xcursor->mx_cursor.mc_flags &= ~(C_INITIALIZED|C_EOF);
|
|
|
-
|
|
|
- /* See if we're already on the right page */
|
|
|
- if (mc->mc_flags & C_INITIALIZED) {
|
|
|
- MDB_val nodekey;
|
|
|
-
|
|
|
- mp = mc->mc_pg[mc->mc_top];
|
|
|
- if (!NUMKEYS(mp)) {
|
|
|
- mc->mc_ki[mc->mc_top] = 0;
|
|
|
- return MDB_NOTFOUND;
|
|
|
- }
|
|
|
- if (mp->mp_flags & P_LEAF2) {
|
|
|
- nodekey.mv_size = mc->mc_db->md_pad;
|
|
|
- nodekey.mv_data = LEAF2KEY(mp, 0, nodekey.mv_size);
|
|
|
- } else {
|
|
|
- leaf = NODEPTR(mp, 0);
|
|
|
- MDB_GET_KEY2(leaf, nodekey);
|
|
|
- }
|
|
|
- rc = mc->mc_dbx->md_cmp(key, &nodekey);
|
|
|
- if (rc == 0) {
|
|
|
- /* Probably happens rarely, but first node on the page
|
|
|
- * was the one we wanted.
|
|
|
- */
|
|
|
- mc->mc_ki[mc->mc_top] = 0;
|
|
|
- if (exactp)
|
|
|
- *exactp = 1;
|
|
|
- goto set1;
|
|
|
- }
|
|
|
- if (rc > 0) {
|
|
|
- unsigned int i;
|
|
|
- unsigned int nkeys = NUMKEYS(mp);
|
|
|
- if (nkeys > 1) {
|
|
|
- if (mp->mp_flags & P_LEAF2) {
|
|
|
- nodekey.mv_data = LEAF2KEY(mp,
|
|
|
- nkeys-1, nodekey.mv_size);
|
|
|
- } else {
|
|
|
- leaf = NODEPTR(mp, nkeys-1);
|
|
|
- MDB_GET_KEY2(leaf, nodekey);
|
|
|
- }
|
|
|
- rc = mc->mc_dbx->md_cmp(key, &nodekey);
|
|
|
- if (rc == 0) {
|
|
|
- /* last node was the one we wanted */
|
|
|
- mc->mc_ki[mc->mc_top] = nkeys-1;
|
|
|
- if (exactp)
|
|
|
- *exactp = 1;
|
|
|
- goto set1;
|
|
|
- }
|
|
|
- if (rc < 0) {
|
|
|
- if (mc->mc_ki[mc->mc_top] < NUMKEYS(mp)) {
|
|
|
- /* This is definitely the right page, skip search_page */
|
|
|
- if (mp->mp_flags & P_LEAF2) {
|
|
|
- nodekey.mv_data = LEAF2KEY(mp,
|
|
|
- mc->mc_ki[mc->mc_top], nodekey.mv_size);
|
|
|
- } else {
|
|
|
- leaf = NODEPTR(mp, mc->mc_ki[mc->mc_top]);
|
|
|
- MDB_GET_KEY2(leaf, nodekey);
|
|
|
- }
|
|
|
- rc = mc->mc_dbx->md_cmp(key, &nodekey);
|
|
|
- if (rc == 0) {
|
|
|
- /* current node was the one we wanted */
|
|
|
- if (exactp)
|
|
|
- *exactp = 1;
|
|
|
- goto set1;
|
|
|
- }
|
|
|
- }
|
|
|
- rc = 0;
|
|
|
- mc->mc_flags &= ~C_EOF;
|
|
|
- goto set2;
|
|
|
- }
|
|
|
- }
|
|
|
- /* If any parents have right-sibs, search.
|
|
|
- * Otherwise, there's nothing further.
|
|
|
- */
|
|
|
- for (i=0; i<mc->mc_top; i++)
|
|
|
- if (mc->mc_ki[i] <
|
|
|
- NUMKEYS(mc->mc_pg[i])-1)
|
|
|
- break;
|
|
|
- if (i == mc->mc_top) {
|
|
|
- /* There are no other pages */
|
|
|
- mc->mc_ki[mc->mc_top] = nkeys;
|
|
|
- return MDB_NOTFOUND;
|
|
|
- }
|
|
|
- }
|
|
|
- if (!mc->mc_top) {
|
|
|
- /* There are no other pages */
|
|
|
- mc->mc_ki[mc->mc_top] = 0;
|
|
|
- if (op == MDB_SET_RANGE && !exactp) {
|
|
|
- rc = 0;
|
|
|
- goto set1;
|
|
|
- } else
|
|
|
- return MDB_NOTFOUND;
|
|
|
- }
|
|
|
- } else {
|
|
|
- mc->mc_pg[0] = 0;
|
|
|
- }
|
|
|
-
|
|
|
- rc = mdb_page_search(mc, key, 0);
|
|
|
- if (rc != MDB_SUCCESS)
|
|
|
- return rc;
|
|
|
-
|
|
|
- mp = mc->mc_pg[mc->mc_top];
|
|
|
- mdb_cassert(mc, IS_LEAF(mp));
|
|
|
-
|
|
|
-set2:
|
|
|
- leaf = mdb_node_search(mc, key, exactp);
|
|
|
- if (exactp != NULL && !*exactp) {
|
|
|
- /* MDB_SET specified and not an exact match. */
|
|
|
- return MDB_NOTFOUND;
|
|
|
- }
|
|
|
-
|
|
|
- if (leaf == NULL) {
|
|
|
- DPUTS("===> inexact leaf not found, goto sibling");
|
|
|
- if ((rc = mdb_cursor_sibling(mc, 1)) != MDB_SUCCESS) {
|
|
|
- mc->mc_flags |= C_EOF;
|
|
|
- return rc; /* no entries matched */
|
|
|
- }
|
|
|
- mp = mc->mc_pg[mc->mc_top];
|
|
|
- mdb_cassert(mc, IS_LEAF(mp));
|
|
|
- leaf = NODEPTR(mp, 0);
|
|
|
- }
|
|
|
-
|
|
|
-set1:
|
|
|
- mc->mc_flags |= C_INITIALIZED;
|
|
|
- mc->mc_flags &= ~C_EOF;
|
|
|
-
|
|
|
- if (IS_LEAF2(mp)) {
|
|
|
- if (op == MDB_SET_RANGE || op == MDB_SET_KEY) {
|
|
|
- key->mv_size = mc->mc_db->md_pad;
|
|
|
- key->mv_data = LEAF2KEY(mp, mc->mc_ki[mc->mc_top], key->mv_size);
|
|
|
- }
|
|
|
- return MDB_SUCCESS;
|
|
|
- }
|
|
|
-
|
|
|
- if (F_ISSET(leaf->mn_flags, F_DUPDATA)) {
|
|
|
- mdb_xcursor_init1(mc, leaf);
|
|
|
- }
|
|
|
- if (data) {
|
|
|
- if (F_ISSET(leaf->mn_flags, F_DUPDATA)) {
|
|
|
- if (op == MDB_SET || op == MDB_SET_KEY || op == MDB_SET_RANGE) {
|
|
|
- rc = mdb_cursor_first(&mc->mc_xcursor->mx_cursor, data, NULL);
|
|
|
- } else {
|
|
|
- int ex2, *ex2p;
|
|
|
- if (op == MDB_GET_BOTH) {
|
|
|
- ex2p = &ex2;
|
|
|
- ex2 = 0;
|
|
|
- } else {
|
|
|
- ex2p = NULL;
|
|
|
- }
|
|
|
- rc = mdb_cursor_set(&mc->mc_xcursor->mx_cursor, data, NULL, MDB_SET_RANGE, ex2p);
|
|
|
- if (rc != MDB_SUCCESS)
|
|
|
- return rc;
|
|
|
- }
|
|
|
- } else if (op == MDB_GET_BOTH || op == MDB_GET_BOTH_RANGE) {
|
|
|
- MDB_val olddata;
|
|
|
- MDB_cmp_func *dcmp;
|
|
|
- if ((rc = mdb_node_read(mc, leaf, &olddata)) != MDB_SUCCESS)
|
|
|
- return rc;
|
|
|
- dcmp = mc->mc_dbx->md_dcmp;
|
|
|
-#if UINT_MAX < SIZE_MAX
|
|
|
- if (dcmp == mdb_cmp_int && olddata.mv_size == sizeof(size_t))
|
|
|
- dcmp = mdb_cmp_clong;
|
|
|
-#endif
|
|
|
- rc = dcmp(data, &olddata);
|
|
|
- if (rc) {
|
|
|
- if (op == MDB_GET_BOTH || rc > 0)
|
|
|
- return MDB_NOTFOUND;
|
|
|
- rc = 0;
|
|
|
- }
|
|
|
- *data = olddata;
|
|
|
-
|
|
|
- } else {
|
|
|
- if (mc->mc_xcursor)
|
|
|
- mc->mc_xcursor->mx_cursor.mc_flags &= ~(C_INITIALIZED|C_EOF);
|
|
|
- if ((rc = mdb_node_read(mc, leaf, data)) != MDB_SUCCESS)
|
|
|
- return rc;
|
|
|
- }
|
|
|
- }
|
|
|
-
|
|
|
- /* The key already matches in all other cases */
|
|
|
- if (op == MDB_SET_RANGE || op == MDB_SET_KEY)
|
|
|
- MDB_GET_KEY(leaf, key);
|
|
|
- DPRINTF(("==> cursor placed on key [%s]", DKEY(key)));
|
|
|
-
|
|
|
- return rc;
|
|
|
-}
|
|
|
-
|
|
|
-/** Move the cursor to the first item in the database. */
|
|
|
-static int
|
|
|
-mdb_cursor_first(MDB_cursor *mc, MDB_val *key, MDB_val *data)
|
|
|
-{
|
|
|
- int rc;
|
|
|
- MDB_node *leaf;
|
|
|
-
|
|
|
- if (mc->mc_xcursor)
|
|
|
- mc->mc_xcursor->mx_cursor.mc_flags &= ~(C_INITIALIZED|C_EOF);
|
|
|
-
|
|
|
- if (!(mc->mc_flags & C_INITIALIZED) || mc->mc_top) {
|
|
|
- rc = mdb_page_search(mc, NULL, MDB_PS_FIRST);
|
|
|
- if (rc != MDB_SUCCESS)
|
|
|
- return rc;
|
|
|
- }
|
|
|
- mdb_cassert(mc, IS_LEAF(mc->mc_pg[mc->mc_top]));
|
|
|
-
|
|
|
- leaf = NODEPTR(mc->mc_pg[mc->mc_top], 0);
|
|
|
- mc->mc_flags |= C_INITIALIZED;
|
|
|
- mc->mc_flags &= ~C_EOF;
|
|
|
-
|
|
|
- mc->mc_ki[mc->mc_top] = 0;
|
|
|
-
|
|
|
- if (IS_LEAF2(mc->mc_pg[mc->mc_top])) {
|
|
|
- key->mv_size = mc->mc_db->md_pad;
|
|
|
- key->mv_data = LEAF2KEY(mc->mc_pg[mc->mc_top], 0, key->mv_size);
|
|
|
- return MDB_SUCCESS;
|
|
|
- }
|
|
|
-
|
|
|
- if (data) {
|
|
|
- if (F_ISSET(leaf->mn_flags, F_DUPDATA)) {
|
|
|
- mdb_xcursor_init1(mc, leaf);
|
|
|
- rc = mdb_cursor_first(&mc->mc_xcursor->mx_cursor, data, NULL);
|
|
|
- if (rc)
|
|
|
- return rc;
|
|
|
- } else {
|
|
|
- if ((rc = mdb_node_read(mc, leaf, data)) != MDB_SUCCESS)
|
|
|
- return rc;
|
|
|
- }
|
|
|
- }
|
|
|
- MDB_GET_KEY(leaf, key);
|
|
|
- return MDB_SUCCESS;
|
|
|
-}
|
|
|
-
|
|
|
-/** Move the cursor to the last item in the database. */
|
|
|
-static int
|
|
|
-mdb_cursor_last(MDB_cursor *mc, MDB_val *key, MDB_val *data)
|
|
|
-{
|
|
|
- int rc;
|
|
|
- MDB_node *leaf;
|
|
|
-
|
|
|
- if (mc->mc_xcursor)
|
|
|
- mc->mc_xcursor->mx_cursor.mc_flags &= ~(C_INITIALIZED|C_EOF);
|
|
|
-
|
|
|
- if (!(mc->mc_flags & C_INITIALIZED) || mc->mc_top) {
|
|
|
- rc = mdb_page_search(mc, NULL, MDB_PS_LAST);
|
|
|
- if (rc != MDB_SUCCESS)
|
|
|
- return rc;
|
|
|
- }
|
|
|
- mdb_cassert(mc, IS_LEAF(mc->mc_pg[mc->mc_top]));
|
|
|
-
|
|
|
- mc->mc_ki[mc->mc_top] = NUMKEYS(mc->mc_pg[mc->mc_top]) - 1;
|
|
|
- mc->mc_flags |= C_INITIALIZED|C_EOF;
|
|
|
- leaf = NODEPTR(mc->mc_pg[mc->mc_top], mc->mc_ki[mc->mc_top]);
|
|
|
-
|
|
|
- if (IS_LEAF2(mc->mc_pg[mc->mc_top])) {
|
|
|
- key->mv_size = mc->mc_db->md_pad;
|
|
|
- key->mv_data = LEAF2KEY(mc->mc_pg[mc->mc_top], mc->mc_ki[mc->mc_top], key->mv_size);
|
|
|
- return MDB_SUCCESS;
|
|
|
- }
|
|
|
-
|
|
|
- if (data) {
|
|
|
- if (F_ISSET(leaf->mn_flags, F_DUPDATA)) {
|
|
|
- mdb_xcursor_init1(mc, leaf);
|
|
|
- rc = mdb_cursor_last(&mc->mc_xcursor->mx_cursor, data, NULL);
|
|
|
- if (rc)
|
|
|
- return rc;
|
|
|
- } else {
|
|
|
- if ((rc = mdb_node_read(mc, leaf, data)) != MDB_SUCCESS)
|
|
|
- return rc;
|
|
|
- }
|
|
|
- }
|
|
|
-
|
|
|
- MDB_GET_KEY(leaf, key);
|
|
|
- return MDB_SUCCESS;
|
|
|
-}
|
|
|
-
|
|
|
-int
|
|
|
-mdb_cursor_get(MDB_cursor *mc, MDB_val *key, MDB_val *data,
|
|
|
- MDB_cursor_op op)
|
|
|
-{
|
|
|
- int rc;
|
|
|
- int exact = 0;
|
|
|
- int (*mfunc)(MDB_cursor *mc, MDB_val *key, MDB_val *data);
|
|
|
-
|
|
|
- if (mc == NULL)
|
|
|
- return EINVAL;
|
|
|
-
|
|
|
- if (mc->mc_txn->mt_flags & MDB_TXN_BLOCKED)
|
|
|
- return MDB_BAD_TXN;
|
|
|
-
|
|
|
- switch (op) {
|
|
|
- case MDB_GET_CURRENT:
|
|
|
- if (!(mc->mc_flags & C_INITIALIZED)) {
|
|
|
- rc = EINVAL;
|
|
|
- } else {
|
|
|
- MDB_page *mp = mc->mc_pg[mc->mc_top];
|
|
|
- int nkeys = NUMKEYS(mp);
|
|
|
- if (!nkeys || mc->mc_ki[mc->mc_top] >= nkeys) {
|
|
|
- mc->mc_ki[mc->mc_top] = nkeys;
|
|
|
- rc = MDB_NOTFOUND;
|
|
|
- break;
|
|
|
- }
|
|
|
- rc = MDB_SUCCESS;
|
|
|
- if (IS_LEAF2(mp)) {
|
|
|
- key->mv_size = mc->mc_db->md_pad;
|
|
|
- key->mv_data = LEAF2KEY(mp, mc->mc_ki[mc->mc_top], key->mv_size);
|
|
|
- } else {
|
|
|
- MDB_node *leaf = NODEPTR(mp, mc->mc_ki[mc->mc_top]);
|
|
|
- MDB_GET_KEY(leaf, key);
|
|
|
- if (data) {
|
|
|
- if (F_ISSET(leaf->mn_flags, F_DUPDATA)) {
|
|
|
- rc = mdb_cursor_get(&mc->mc_xcursor->mx_cursor, data, NULL, MDB_GET_CURRENT);
|
|
|
- } else {
|
|
|
- rc = mdb_node_read(mc, leaf, data);
|
|
|
- }
|
|
|
- }
|
|
|
- }
|
|
|
- }
|
|
|
- break;
|
|
|
- case MDB_GET_BOTH:
|
|
|
- case MDB_GET_BOTH_RANGE:
|
|
|
- if (data == NULL) {
|
|
|
- rc = EINVAL;
|
|
|
- break;
|
|
|
- }
|
|
|
- if (mc->mc_xcursor == NULL) {
|
|
|
- rc = MDB_INCOMPATIBLE;
|
|
|
- break;
|
|
|
- }
|
|
|
- /* FALLTHRU */
|
|
|
- case MDB_SET:
|
|
|
- case MDB_SET_KEY:
|
|
|
- case MDB_SET_RANGE:
|
|
|
- if (key == NULL) {
|
|
|
- rc = EINVAL;
|
|
|
- } else {
|
|
|
- rc = mdb_cursor_set(mc, key, data, op,
|
|
|
- op == MDB_SET_RANGE ? NULL : &exact);
|
|
|
- }
|
|
|
- break;
|
|
|
- case MDB_GET_MULTIPLE:
|
|
|
- if (data == NULL || !(mc->mc_flags & C_INITIALIZED)) {
|
|
|
- rc = EINVAL;
|
|
|
- break;
|
|
|
- }
|
|
|
- if (!(mc->mc_db->md_flags & MDB_DUPFIXED)) {
|
|
|
- rc = MDB_INCOMPATIBLE;
|
|
|
- break;
|
|
|
- }
|
|
|
- rc = MDB_SUCCESS;
|
|
|
- if (!(mc->mc_xcursor->mx_cursor.mc_flags & C_INITIALIZED) ||
|
|
|
- (mc->mc_xcursor->mx_cursor.mc_flags & C_EOF))
|
|
|
- break;
|
|
|
- goto fetchm;
|
|
|
- case MDB_NEXT_MULTIPLE:
|
|
|
- if (data == NULL) {
|
|
|
- rc = EINVAL;
|
|
|
- break;
|
|
|
- }
|
|
|
- if (!(mc->mc_db->md_flags & MDB_DUPFIXED)) {
|
|
|
- rc = MDB_INCOMPATIBLE;
|
|
|
- break;
|
|
|
- }
|
|
|
- rc = mdb_cursor_next(mc, key, data, MDB_NEXT_DUP);
|
|
|
- if (rc == MDB_SUCCESS) {
|
|
|
- if (mc->mc_xcursor->mx_cursor.mc_flags & C_INITIALIZED) {
|
|
|
- MDB_cursor *mx;
|
|
|
-fetchm:
|
|
|
- mx = &mc->mc_xcursor->mx_cursor;
|
|
|
- data->mv_size = NUMKEYS(mx->mc_pg[mx->mc_top]) *
|
|
|
- mx->mc_db->md_pad;
|
|
|
- data->mv_data = METADATA(mx->mc_pg[mx->mc_top]);
|
|
|
- mx->mc_ki[mx->mc_top] = NUMKEYS(mx->mc_pg[mx->mc_top])-1;
|
|
|
- } else {
|
|
|
- rc = MDB_NOTFOUND;
|
|
|
- }
|
|
|
- }
|
|
|
- break;
|
|
|
- case MDB_PREV_MULTIPLE:
|
|
|
- if (data == NULL) {
|
|
|
- rc = EINVAL;
|
|
|
- break;
|
|
|
- }
|
|
|
- if (!(mc->mc_db->md_flags & MDB_DUPFIXED)) {
|
|
|
- rc = MDB_INCOMPATIBLE;
|
|
|
- break;
|
|
|
- }
|
|
|
- if (!(mc->mc_flags & C_INITIALIZED))
|
|
|
- rc = mdb_cursor_last(mc, key, data);
|
|
|
- else
|
|
|
- rc = MDB_SUCCESS;
|
|
|
- if (rc == MDB_SUCCESS) {
|
|
|
- MDB_cursor *mx = &mc->mc_xcursor->mx_cursor;
|
|
|
- if (mx->mc_flags & C_INITIALIZED) {
|
|
|
- rc = mdb_cursor_sibling(mx, 0);
|
|
|
- if (rc == MDB_SUCCESS)
|
|
|
- goto fetchm;
|
|
|
- } else {
|
|
|
- rc = MDB_NOTFOUND;
|
|
|
- }
|
|
|
- }
|
|
|
- break;
|
|
|
- case MDB_NEXT:
|
|
|
- case MDB_NEXT_DUP:
|
|
|
- case MDB_NEXT_NODUP:
|
|
|
- rc = mdb_cursor_next(mc, key, data, op);
|
|
|
- break;
|
|
|
- case MDB_PREV:
|
|
|
- case MDB_PREV_DUP:
|
|
|
- case MDB_PREV_NODUP:
|
|
|
- rc = mdb_cursor_prev(mc, key, data, op);
|
|
|
- break;
|
|
|
- case MDB_FIRST:
|
|
|
- rc = mdb_cursor_first(mc, key, data);
|
|
|
- break;
|
|
|
- case MDB_FIRST_DUP:
|
|
|
- mfunc = mdb_cursor_first;
|
|
|
- mmove:
|
|
|
- if (data == NULL || !(mc->mc_flags & C_INITIALIZED)) {
|
|
|
- rc = EINVAL;
|
|
|
- break;
|
|
|
- }
|
|
|
- if (mc->mc_xcursor == NULL) {
|
|
|
- rc = MDB_INCOMPATIBLE;
|
|
|
- break;
|
|
|
- }
|
|
|
- if (mc->mc_ki[mc->mc_top] >= NUMKEYS(mc->mc_pg[mc->mc_top])) {
|
|
|
- mc->mc_ki[mc->mc_top] = NUMKEYS(mc->mc_pg[mc->mc_top]);
|
|
|
- rc = MDB_NOTFOUND;
|
|
|
- break;
|
|
|
- }
|
|
|
- {
|
|
|
- MDB_node *leaf = NODEPTR(mc->mc_pg[mc->mc_top], mc->mc_ki[mc->mc_top]);
|
|
|
- if (!F_ISSET(leaf->mn_flags, F_DUPDATA)) {
|
|
|
- MDB_GET_KEY(leaf, key);
|
|
|
- rc = mdb_node_read(mc, leaf, data);
|
|
|
- break;
|
|
|
- }
|
|
|
- }
|
|
|
- if (!(mc->mc_xcursor->mx_cursor.mc_flags & C_INITIALIZED)) {
|
|
|
- rc = EINVAL;
|
|
|
- break;
|
|
|
- }
|
|
|
- rc = mfunc(&mc->mc_xcursor->mx_cursor, data, NULL);
|
|
|
- break;
|
|
|
- case MDB_LAST:
|
|
|
- rc = mdb_cursor_last(mc, key, data);
|
|
|
- break;
|
|
|
- case MDB_LAST_DUP:
|
|
|
- mfunc = mdb_cursor_last;
|
|
|
- goto mmove;
|
|
|
- default:
|
|
|
- DPRINTF(("unhandled/unimplemented cursor operation %u", op));
|
|
|
- rc = EINVAL;
|
|
|
- break;
|
|
|
- }
|
|
|
-
|
|
|
- if (mc->mc_flags & C_DEL)
|
|
|
- mc->mc_flags ^= C_DEL;
|
|
|
-
|
|
|
- return rc;
|
|
|
-}
|
|
|
-
|
|
|
-/** Touch all the pages in the cursor stack. Set mc_top.
|
|
|
- * Makes sure all the pages are writable, before attempting a write operation.
|
|
|
- * @param[in] mc The cursor to operate on.
|
|
|
- */
|
|
|
-static int
|
|
|
-mdb_cursor_touch(MDB_cursor *mc)
|
|
|
-{
|
|
|
- int rc = MDB_SUCCESS;
|
|
|
-
|
|
|
- if (mc->mc_dbi >= CORE_DBS && !(*mc->mc_dbflag & (DB_DIRTY|DB_DUPDATA))) {
|
|
|
- /* Touch DB record of named DB */
|
|
|
- MDB_cursor mc2;
|
|
|
- MDB_xcursor mcx;
|
|
|
- if (TXN_DBI_CHANGED(mc->mc_txn, mc->mc_dbi))
|
|
|
- return MDB_BAD_DBI;
|
|
|
- mdb_cursor_init(&mc2, mc->mc_txn, MAIN_DBI, &mcx);
|
|
|
- rc = mdb_page_search(&mc2, &mc->mc_dbx->md_name, MDB_PS_MODIFY);
|
|
|
- if (rc)
|
|
|
- return rc;
|
|
|
- *mc->mc_dbflag |= DB_DIRTY;
|
|
|
- }
|
|
|
- mc->mc_top = 0;
|
|
|
- if (mc->mc_snum) {
|
|
|
- do {
|
|
|
- rc = mdb_page_touch(mc);
|
|
|
- } while (!rc && ++(mc->mc_top) < mc->mc_snum);
|
|
|
- mc->mc_top = mc->mc_snum-1;
|
|
|
- }
|
|
|
- return rc;
|
|
|
-}
|
|
|
-
|
|
|
-/** Do not spill pages to disk if txn is getting full, may fail instead */
|
|
|
-#define MDB_NOSPILL 0x8000
|
|
|
-
|
|
|
-int
|
|
|
-mdb_cursor_put(MDB_cursor *mc, MDB_val *key, MDB_val *data,
|
|
|
- unsigned int flags)
|
|
|
-{
|
|
|
- MDB_env *env;
|
|
|
- MDB_node *leaf = NULL;
|
|
|
- MDB_page *fp, *mp, *sub_root = NULL;
|
|
|
- uint16_t fp_flags;
|
|
|
- MDB_val xdata, *rdata, dkey, olddata;
|
|
|
- MDB_db dummy;
|
|
|
- int do_sub = 0, insert_key, insert_data;
|
|
|
- unsigned int mcount = 0, dcount = 0, nospill;
|
|
|
- size_t nsize;
|
|
|
- int rc, rc2;
|
|
|
- unsigned int nflags;
|
|
|
- DKBUF;
|
|
|
-
|
|
|
- if (mc == NULL || key == NULL)
|
|
|
- return EINVAL;
|
|
|
-
|
|
|
- env = mc->mc_txn->mt_env;
|
|
|
-
|
|
|
- /* Check this first so counter will always be zero on any
|
|
|
- * early failures.
|
|
|
- */
|
|
|
- if (flags & MDB_MULTIPLE) {
|
|
|
- dcount = data[1].mv_size;
|
|
|
- data[1].mv_size = 0;
|
|
|
- if (!F_ISSET(mc->mc_db->md_flags, MDB_DUPFIXED))
|
|
|
- return MDB_INCOMPATIBLE;
|
|
|
- }
|
|
|
-
|
|
|
- nospill = flags & MDB_NOSPILL;
|
|
|
- flags &= ~MDB_NOSPILL;
|
|
|
-
|
|
|
- if (mc->mc_txn->mt_flags & (MDB_TXN_RDONLY|MDB_TXN_BLOCKED))
|
|
|
- return (mc->mc_txn->mt_flags & MDB_TXN_RDONLY) ? EACCES : MDB_BAD_TXN;
|
|
|
-
|
|
|
- if (key->mv_size-1 >= ENV_MAXKEY(env))
|
|
|
- return MDB_BAD_VALSIZE;
|
|
|
-
|
|
|
-#if SIZE_MAX > MAXDATASIZE
|
|
|
- if (data->mv_size > ((mc->mc_db->md_flags & MDB_DUPSORT) ? ENV_MAXKEY(env) : MAXDATASIZE))
|
|
|
- return MDB_BAD_VALSIZE;
|
|
|
-#else
|
|
|
- if ((mc->mc_db->md_flags & MDB_DUPSORT) && data->mv_size > ENV_MAXKEY(env))
|
|
|
- return MDB_BAD_VALSIZE;
|
|
|
-#endif
|
|
|
-
|
|
|
- DPRINTF(("==> put db %d key [%s], size %"Z"u, data size %"Z"u",
|
|
|
- DDBI(mc), DKEY(key), key ? key->mv_size : 0, data->mv_size));
|
|
|
-
|
|
|
- dkey.mv_size = 0;
|
|
|
-
|
|
|
- if (flags == MDB_CURRENT) {
|
|
|
- if (!(mc->mc_flags & C_INITIALIZED))
|
|
|
- return EINVAL;
|
|
|
- rc = MDB_SUCCESS;
|
|
|
- } else if (mc->mc_db->md_root == P_INVALID) {
|
|
|
- /* new database, cursor has nothing to point to */
|
|
|
- mc->mc_snum = 0;
|
|
|
- mc->mc_top = 0;
|
|
|
- mc->mc_flags &= ~C_INITIALIZED;
|
|
|
- rc = MDB_NO_ROOT;
|
|
|
- } else {
|
|
|
- int exact = 0;
|
|
|
- MDB_val d2;
|
|
|
- if (flags & MDB_APPEND) {
|
|
|
- MDB_val k2;
|
|
|
- rc = mdb_cursor_last(mc, &k2, &d2);
|
|
|
- if (rc == 0) {
|
|
|
- rc = mc->mc_dbx->md_cmp(key, &k2);
|
|
|
- if (rc > 0) {
|
|
|
- rc = MDB_NOTFOUND;
|
|
|
- mc->mc_ki[mc->mc_top]++;
|
|
|
- } else {
|
|
|
- /* new key is <= last key */
|
|
|
- rc = MDB_KEYEXIST;
|
|
|
- }
|
|
|
- }
|
|
|
- } else {
|
|
|
- rc = mdb_cursor_set(mc, key, &d2, MDB_SET, &exact);
|
|
|
- }
|
|
|
- if ((flags & MDB_NOOVERWRITE) && rc == 0) {
|
|
|
- DPRINTF(("duplicate key [%s]", DKEY(key)));
|
|
|
- *data = d2;
|
|
|
- return MDB_KEYEXIST;
|
|
|
- }
|
|
|
- if (rc && rc != MDB_NOTFOUND)
|
|
|
- return rc;
|
|
|
- }
|
|
|
-
|
|
|
- if (mc->mc_flags & C_DEL)
|
|
|
- mc->mc_flags ^= C_DEL;
|
|
|
-
|
|
|
- /* Cursor is positioned, check for room in the dirty list */
|
|
|
- if (!nospill) {
|
|
|
- if (flags & MDB_MULTIPLE) {
|
|
|
- rdata = &xdata;
|
|
|
- xdata.mv_size = data->mv_size * dcount;
|
|
|
- } else {
|
|
|
- rdata = data;
|
|
|
- }
|
|
|
- if ((rc2 = mdb_page_spill(mc, key, rdata)))
|
|
|
- return rc2;
|
|
|
- }
|
|
|
-
|
|
|
- if (rc == MDB_NO_ROOT) {
|
|
|
- MDB_page *np;
|
|
|
- /* new database, write a root leaf page */
|
|
|
- DPUTS("allocating new root leaf page");
|
|
|
- if ((rc2 = mdb_page_new(mc, P_LEAF, 1, &np))) {
|
|
|
- return rc2;
|
|
|
- }
|
|
|
- mdb_cursor_push(mc, np);
|
|
|
- mc->mc_db->md_root = np->mp_pgno;
|
|
|
- mc->mc_db->md_depth++;
|
|
|
- *mc->mc_dbflag |= DB_DIRTY;
|
|
|
- if ((mc->mc_db->md_flags & (MDB_DUPSORT|MDB_DUPFIXED))
|
|
|
- == MDB_DUPFIXED)
|
|
|
- np->mp_flags |= P_LEAF2;
|
|
|
- mc->mc_flags |= C_INITIALIZED;
|
|
|
- } else {
|
|
|
- /* make sure all cursor pages are writable */
|
|
|
- rc2 = mdb_cursor_touch(mc);
|
|
|
- if (rc2)
|
|
|
- return rc2;
|
|
|
- }
|
|
|
-
|
|
|
- insert_key = insert_data = rc;
|
|
|
- if (insert_key) {
|
|
|
- /* The key does not exist */
|
|
|
- DPRINTF(("inserting key at index %i", mc->mc_ki[mc->mc_top]));
|
|
|
- if ((mc->mc_db->md_flags & MDB_DUPSORT) &&
|
|
|
- LEAFSIZE(key, data) > env->me_nodemax)
|
|
|
- {
|
|
|
- /* Too big for a node, insert in sub-DB. Set up an empty
|
|
|
- * "old sub-page" for prep_subDB to expand to a full page.
|
|
|
- */
|
|
|
- fp_flags = P_LEAF|P_DIRTY;
|
|
|
- fp = env->me_pbuf;
|
|
|
- fp->mp_pad = data->mv_size; /* used if MDB_DUPFIXED */
|
|
|
- fp->mp_lower = fp->mp_upper = (PAGEHDRSZ-PAGEBASE);
|
|
|
- olddata.mv_size = PAGEHDRSZ;
|
|
|
- goto prep_subDB;
|
|
|
- }
|
|
|
- } else {
|
|
|
- /* there's only a key anyway, so this is a no-op */
|
|
|
- if (IS_LEAF2(mc->mc_pg[mc->mc_top])) {
|
|
|
- char *ptr;
|
|
|
- unsigned int ksize = mc->mc_db->md_pad;
|
|
|
- if (key->mv_size != ksize)
|
|
|
- return MDB_BAD_VALSIZE;
|
|
|
- ptr = LEAF2KEY(mc->mc_pg[mc->mc_top], mc->mc_ki[mc->mc_top], ksize);
|
|
|
- memcpy(ptr, key->mv_data, ksize);
|
|
|
-fix_parent:
|
|
|
- /* if overwriting slot 0 of leaf, need to
|
|
|
- * update branch key if there is a parent page
|
|
|
- */
|
|
|
- if (mc->mc_top && !mc->mc_ki[mc->mc_top]) {
|
|
|
- unsigned short dtop = 1;
|
|
|
- mc->mc_top--;
|
|
|
- /* slot 0 is always an empty key, find real slot */
|
|
|
- while (mc->mc_top && !mc->mc_ki[mc->mc_top]) {
|
|
|
- mc->mc_top--;
|
|
|
- dtop++;
|
|
|
- }
|
|
|
- if (mc->mc_ki[mc->mc_top])
|
|
|
- rc2 = mdb_update_key(mc, key);
|
|
|
- else
|
|
|
- rc2 = MDB_SUCCESS;
|
|
|
- mc->mc_top += dtop;
|
|
|
- if (rc2)
|
|
|
- return rc2;
|
|
|
- }
|
|
|
- return MDB_SUCCESS;
|
|
|
- }
|
|
|
-
|
|
|
-more:
|
|
|
- leaf = NODEPTR(mc->mc_pg[mc->mc_top], mc->mc_ki[mc->mc_top]);
|
|
|
- olddata.mv_size = NODEDSZ(leaf);
|
|
|
- olddata.mv_data = NODEDATA(leaf);
|
|
|
-
|
|
|
- /* DB has dups? */
|
|
|
- if (F_ISSET(mc->mc_db->md_flags, MDB_DUPSORT)) {
|
|
|
- /* Prepare (sub-)page/sub-DB to accept the new item,
|
|
|
- * if needed. fp: old sub-page or a header faking
|
|
|
- * it. mp: new (sub-)page. offset: growth in page
|
|
|
- * size. xdata: node data with new page or DB.
|
|
|
- */
|
|
|
- unsigned i, offset = 0;
|
|
|
- mp = fp = xdata.mv_data = env->me_pbuf;
|
|
|
- mp->mp_pgno = mc->mc_pg[mc->mc_top]->mp_pgno;
|
|
|
-
|
|
|
- /* Was a single item before, must convert now */
|
|
|
- if (!F_ISSET(leaf->mn_flags, F_DUPDATA)) {
|
|
|
- MDB_cmp_func *dcmp;
|
|
|
- /* Just overwrite the current item */
|
|
|
- if (flags == MDB_CURRENT)
|
|
|
- goto current;
|
|
|
- dcmp = mc->mc_dbx->md_dcmp;
|
|
|
-#if UINT_MAX < SIZE_MAX
|
|
|
- if (dcmp == mdb_cmp_int && olddata.mv_size == sizeof(size_t))
|
|
|
- dcmp = mdb_cmp_clong;
|
|
|
-#endif
|
|
|
- /* does data match? */
|
|
|
- if (!dcmp(data, &olddata)) {
|
|
|
- if (flags & (MDB_NODUPDATA|MDB_APPENDDUP))
|
|
|
- return MDB_KEYEXIST;
|
|
|
- /* overwrite it */
|
|
|
- goto current;
|
|
|
- }
|
|
|
-
|
|
|
- /* Back up original data item */
|
|
|
- dkey.mv_size = olddata.mv_size;
|
|
|
- dkey.mv_data = memcpy(fp+1, olddata.mv_data, olddata.mv_size);
|
|
|
-
|
|
|
- /* Make sub-page header for the dup items, with dummy body */
|
|
|
- fp->mp_flags = P_LEAF|P_DIRTY|P_SUBP;
|
|
|
- fp->mp_lower = (PAGEHDRSZ-PAGEBASE);
|
|
|
- xdata.mv_size = PAGEHDRSZ + dkey.mv_size + data->mv_size;
|
|
|
- if (mc->mc_db->md_flags & MDB_DUPFIXED) {
|
|
|
- fp->mp_flags |= P_LEAF2;
|
|
|
- fp->mp_pad = data->mv_size;
|
|
|
- xdata.mv_size += 2 * data->mv_size; /* leave space for 2 more */
|
|
|
- } else {
|
|
|
- xdata.mv_size += 2 * (sizeof(indx_t) + NODESIZE) +
|
|
|
- (dkey.mv_size & 1) + (data->mv_size & 1);
|
|
|
- }
|
|
|
- fp->mp_upper = xdata.mv_size - PAGEBASE;
|
|
|
- olddata.mv_size = xdata.mv_size; /* pretend olddata is fp */
|
|
|
- } else if (leaf->mn_flags & F_SUBDATA) {
|
|
|
- /* Data is on sub-DB, just store it */
|
|
|
- flags |= F_DUPDATA|F_SUBDATA;
|
|
|
- goto put_sub;
|
|
|
- } else {
|
|
|
- /* Data is on sub-page */
|
|
|
- fp = olddata.mv_data;
|
|
|
- switch (flags) {
|
|
|
- default:
|
|
|
- if (!(mc->mc_db->md_flags & MDB_DUPFIXED)) {
|
|
|
- offset = EVEN(NODESIZE + sizeof(indx_t) +
|
|
|
- data->mv_size);
|
|
|
- break;
|
|
|
- }
|
|
|
- offset = fp->mp_pad;
|
|
|
- if (SIZELEFT(fp) < offset) {
|
|
|
- offset *= 4; /* space for 4 more */
|
|
|
- break;
|
|
|
- }
|
|
|
- /* FALLTHRU: Big enough MDB_DUPFIXED sub-page */
|
|
|
- case MDB_CURRENT:
|
|
|
- fp->mp_flags |= P_DIRTY;
|
|
|
- COPY_PGNO(fp->mp_pgno, mp->mp_pgno);
|
|
|
- mc->mc_xcursor->mx_cursor.mc_pg[0] = fp;
|
|
|
- flags |= F_DUPDATA;
|
|
|
- goto put_sub;
|
|
|
- }
|
|
|
- xdata.mv_size = olddata.mv_size + offset;
|
|
|
- }
|
|
|
-
|
|
|
- fp_flags = fp->mp_flags;
|
|
|
- if (NODESIZE + NODEKSZ(leaf) + xdata.mv_size > env->me_nodemax) {
|
|
|
- /* Too big for a sub-page, convert to sub-DB */
|
|
|
- fp_flags &= ~P_SUBP;
|
|
|
-prep_subDB:
|
|
|
- if (mc->mc_db->md_flags & MDB_DUPFIXED) {
|
|
|
- fp_flags |= P_LEAF2;
|
|
|
- dummy.md_pad = fp->mp_pad;
|
|
|
- dummy.md_flags = MDB_DUPFIXED;
|
|
|
- if (mc->mc_db->md_flags & MDB_INTEGERDUP)
|
|
|
- dummy.md_flags |= MDB_INTEGERKEY;
|
|
|
- } else {
|
|
|
- dummy.md_pad = 0;
|
|
|
- dummy.md_flags = 0;
|
|
|
- }
|
|
|
- dummy.md_depth = 1;
|
|
|
- dummy.md_branch_pages = 0;
|
|
|
- dummy.md_leaf_pages = 1;
|
|
|
- dummy.md_overflow_pages = 0;
|
|
|
- dummy.md_entries = NUMKEYS(fp);
|
|
|
- xdata.mv_size = sizeof(MDB_db);
|
|
|
- xdata.mv_data = &dummy;
|
|
|
- if ((rc = mdb_page_alloc(mc, 1, &mp)))
|
|
|
- return rc;
|
|
|
- offset = env->me_psize - olddata.mv_size;
|
|
|
- flags |= F_DUPDATA|F_SUBDATA;
|
|
|
- dummy.md_root = mp->mp_pgno;
|
|
|
- sub_root = mp;
|
|
|
- }
|
|
|
- if (mp != fp) {
|
|
|
- mp->mp_flags = fp_flags | P_DIRTY;
|
|
|
- mp->mp_pad = fp->mp_pad;
|
|
|
- mp->mp_lower = fp->mp_lower;
|
|
|
- mp->mp_upper = fp->mp_upper + offset;
|
|
|
- if (fp_flags & P_LEAF2) {
|
|
|
- memcpy(METADATA(mp), METADATA(fp), NUMKEYS(fp) * fp->mp_pad);
|
|
|
- } else {
|
|
|
- memcpy((char *)mp + mp->mp_upper + PAGEBASE, (char *)fp + fp->mp_upper + PAGEBASE,
|
|
|
- olddata.mv_size - fp->mp_upper - PAGEBASE);
|
|
|
- memcpy((char *)(&mp->mp_ptrs), (char *)(&fp->mp_ptrs), NUMKEYS(fp) * sizeof(mp->mp_ptrs[0]));
|
|
|
- for (i=0; i<NUMKEYS(fp); i++)
|
|
|
- mp->mp_ptrs[i] += offset;
|
|
|
- }
|
|
|
- }
|
|
|
-
|
|
|
- rdata = &xdata;
|
|
|
- flags |= F_DUPDATA;
|
|
|
- do_sub = 1;
|
|
|
- if (!insert_key)
|
|
|
- mdb_node_del(mc, 0);
|
|
|
- goto new_sub;
|
|
|
- }
|
|
|
-current:
|
|
|
- /* LMDB passes F_SUBDATA in 'flags' to write a DB record */
|
|
|
- if ((leaf->mn_flags ^ flags) & F_SUBDATA)
|
|
|
- return MDB_INCOMPATIBLE;
|
|
|
- /* overflow page overwrites need special handling */
|
|
|
- if (F_ISSET(leaf->mn_flags, F_BIGDATA)) {
|
|
|
- MDB_page *omp;
|
|
|
- pgno_t pg;
|
|
|
- int level, ovpages, dpages = OVPAGES(data->mv_size, env->me_psize);
|
|
|
-
|
|
|
- memcpy(&pg, olddata.mv_data, sizeof(pg));
|
|
|
- if ((rc2 = mdb_page_get(mc, pg, &omp, &level)) != 0)
|
|
|
- return rc2;
|
|
|
- ovpages = omp->mp_pages;
|
|
|
-
|
|
|
- /* Is the ov page large enough? */
|
|
|
- if (ovpages >= dpages) {
|
|
|
- if (!(omp->mp_flags & P_DIRTY) &&
|
|
|
- (level || (env->me_flags & MDB_WRITEMAP)))
|
|
|
- {
|
|
|
- rc = mdb_page_unspill(mc->mc_txn, omp, &omp);
|
|
|
- if (rc)
|
|
|
- return rc;
|
|
|
- level = 0; /* dirty in this txn or clean */
|
|
|
- }
|
|
|
- /* Is it dirty? */
|
|
|
- if (omp->mp_flags & P_DIRTY) {
|
|
|
- /* yes, overwrite it. Note in this case we don't
|
|
|
- * bother to try shrinking the page if the new data
|
|
|
- * is smaller than the overflow threshold.
|
|
|
- */
|
|
|
- if (level > 1) {
|
|
|
- /* It is writable only in a parent txn */
|
|
|
- size_t sz = (size_t) env->me_psize * ovpages, off;
|
|
|
- MDB_page *np = mdb_page_malloc(mc->mc_txn, ovpages);
|
|
|
- MDB_ID2 id2;
|
|
|
- if (!np)
|
|
|
- return ENOMEM;
|
|
|
- id2.mid = pg;
|
|
|
- id2.mptr = np;
|
|
|
- /* Note - this page is already counted in parent's dirty_room */
|
|
|
- rc2 = mdb_mid2l_insert(mc->mc_txn->mt_u.dirty_list, &id2);
|
|
|
- mdb_cassert(mc, rc2 == 0);
|
|
|
- /* Currently we make the page look as with put() in the
|
|
|
- * parent txn, in case the user peeks at MDB_RESERVEd
|
|
|
- * or unused parts. Some users treat ovpages specially.
|
|
|
- */
|
|
|
- if (!(flags & MDB_RESERVE)) {
|
|
|
- /* Skip the part where LMDB will put *data.
|
|
|
- * Copy end of page, adjusting alignment so
|
|
|
- * compiler may copy words instead of bytes.
|
|
|
- */
|
|
|
- off = (PAGEHDRSZ + data->mv_size) & -sizeof(size_t);
|
|
|
- memcpy((size_t *)((char *)np + off),
|
|
|
- (size_t *)((char *)omp + off), sz - off);
|
|
|
- sz = PAGEHDRSZ;
|
|
|
- }
|
|
|
- memcpy(np, omp, sz); /* Copy beginning of page */
|
|
|
- omp = np;
|
|
|
- }
|
|
|
- SETDSZ(leaf, data->mv_size);
|
|
|
- if (F_ISSET(flags, MDB_RESERVE))
|
|
|
- data->mv_data = METADATA(omp);
|
|
|
- else
|
|
|
- memcpy(METADATA(omp), data->mv_data, data->mv_size);
|
|
|
- return MDB_SUCCESS;
|
|
|
- }
|
|
|
- }
|
|
|
- if ((rc2 = mdb_ovpage_free(mc, omp)) != MDB_SUCCESS)
|
|
|
- return rc2;
|
|
|
- } else if (data->mv_size == olddata.mv_size) {
|
|
|
- /* same size, just replace it. Note that we could
|
|
|
- * also reuse this node if the new data is smaller,
|
|
|
- * but instead we opt to shrink the node in that case.
|
|
|
- */
|
|
|
- if (F_ISSET(flags, MDB_RESERVE))
|
|
|
- data->mv_data = olddata.mv_data;
|
|
|
- else if (!(mc->mc_flags & C_SUB))
|
|
|
- memcpy(olddata.mv_data, data->mv_data, data->mv_size);
|
|
|
- else {
|
|
|
- memcpy(NODEKEY(leaf), key->mv_data, key->mv_size);
|
|
|
- goto fix_parent;
|
|
|
- }
|
|
|
- return MDB_SUCCESS;
|
|
|
- }
|
|
|
- mdb_node_del(mc, 0);
|
|
|
- }
|
|
|
-
|
|
|
- rdata = data;
|
|
|
-
|
|
|
-new_sub:
|
|
|
- nflags = flags & NODE_ADD_FLAGS;
|
|
|
- nsize = IS_LEAF2(mc->mc_pg[mc->mc_top]) ? key->mv_size : mdb_leaf_size(env, key, rdata);
|
|
|
- if (SIZELEFT(mc->mc_pg[mc->mc_top]) < nsize) {
|
|
|
- if (( flags & (F_DUPDATA|F_SUBDATA)) == F_DUPDATA )
|
|
|
- nflags &= ~MDB_APPEND; /* sub-page may need room to grow */
|
|
|
- if (!insert_key)
|
|
|
- nflags |= MDB_SPLIT_REPLACE;
|
|
|
- rc = mdb_page_split(mc, key, rdata, P_INVALID, nflags);
|
|
|
- } else {
|
|
|
- /* There is room already in this leaf page. */
|
|
|
- rc = mdb_node_add(mc, mc->mc_ki[mc->mc_top], key, rdata, 0, nflags);
|
|
|
- if (rc == 0) {
|
|
|
- /* Adjust other cursors pointing to mp */
|
|
|
- MDB_cursor *m2, *m3;
|
|
|
- MDB_dbi dbi = mc->mc_dbi;
|
|
|
- unsigned i = mc->mc_top;
|
|
|
- MDB_page *mp = mc->mc_pg[i];
|
|
|
-
|
|
|
- for (m2 = mc->mc_txn->mt_cursors[dbi]; m2; m2=m2->mc_next) {
|
|
|
- if (mc->mc_flags & C_SUB)
|
|
|
- m3 = &m2->mc_xcursor->mx_cursor;
|
|
|
- else
|
|
|
- m3 = m2;
|
|
|
- if (m3 == mc || m3->mc_snum < mc->mc_snum || m3->mc_pg[i] != mp) continue;
|
|
|
- if (m3->mc_ki[i] >= mc->mc_ki[i] && insert_key) {
|
|
|
- m3->mc_ki[i]++;
|
|
|
- }
|
|
|
- XCURSOR_REFRESH(m3, i, mp);
|
|
|
- }
|
|
|
- }
|
|
|
- }
|
|
|
-
|
|
|
- if (rc == MDB_SUCCESS) {
|
|
|
- /* Now store the actual data in the child DB. Note that we're
|
|
|
- * storing the user data in the keys field, so there are strict
|
|
|
- * size limits on dupdata. The actual data fields of the child
|
|
|
- * DB are all zero size.
|
|
|
- */
|
|
|
- if (do_sub) {
|
|
|
- int xflags, new_dupdata;
|
|
|
- size_t ecount;
|
|
|
-put_sub:
|
|
|
- xdata.mv_size = 0;
|
|
|
- xdata.mv_data = "";
|
|
|
- leaf = NODEPTR(mc->mc_pg[mc->mc_top], mc->mc_ki[mc->mc_top]);
|
|
|
- if (flags & MDB_CURRENT) {
|
|
|
- xflags = MDB_CURRENT|MDB_NOSPILL;
|
|
|
- } else {
|
|
|
- mdb_xcursor_init1(mc, leaf);
|
|
|
- xflags = (flags & MDB_NODUPDATA) ?
|
|
|
- MDB_NOOVERWRITE|MDB_NOSPILL : MDB_NOSPILL;
|
|
|
- }
|
|
|
- if (sub_root)
|
|
|
- mc->mc_xcursor->mx_cursor.mc_pg[0] = sub_root;
|
|
|
- new_dupdata = (int)dkey.mv_size;
|
|
|
- /* converted, write the original data first */
|
|
|
- if (dkey.mv_size) {
|
|
|
- rc = mdb_cursor_put(&mc->mc_xcursor->mx_cursor, &dkey, &xdata, xflags);
|
|
|
- if (rc)
|
|
|
- goto bad_sub;
|
|
|
- /* we've done our job */
|
|
|
- dkey.mv_size = 0;
|
|
|
- }
|
|
|
- if (!(leaf->mn_flags & F_SUBDATA) || sub_root) {
|
|
|
- /* Adjust other cursors pointing to mp */
|
|
|
- MDB_cursor *m2;
|
|
|
- MDB_xcursor *mx = mc->mc_xcursor;
|
|
|
- unsigned i = mc->mc_top;
|
|
|
- MDB_page *mp = mc->mc_pg[i];
|
|
|
-
|
|
|
- for (m2 = mc->mc_txn->mt_cursors[mc->mc_dbi]; m2; m2=m2->mc_next) {
|
|
|
- if (m2 == mc || m2->mc_snum < mc->mc_snum) continue;
|
|
|
- if (!(m2->mc_flags & C_INITIALIZED)) continue;
|
|
|
- if (m2->mc_pg[i] == mp) {
|
|
|
- if (m2->mc_ki[i] == mc->mc_ki[i]) {
|
|
|
- mdb_xcursor_init2(m2, mx, new_dupdata);
|
|
|
- } else if (!insert_key) {
|
|
|
- XCURSOR_REFRESH(m2, i, mp);
|
|
|
- }
|
|
|
- }
|
|
|
- }
|
|
|
- }
|
|
|
- ecount = mc->mc_xcursor->mx_db.md_entries;
|
|
|
- if (flags & MDB_APPENDDUP)
|
|
|
- xflags |= MDB_APPEND;
|
|
|
- rc = mdb_cursor_put(&mc->mc_xcursor->mx_cursor, data, &xdata, xflags);
|
|
|
- if (flags & F_SUBDATA) {
|
|
|
- void *db = NODEDATA(leaf);
|
|
|
- memcpy(db, &mc->mc_xcursor->mx_db, sizeof(MDB_db));
|
|
|
- }
|
|
|
- insert_data = mc->mc_xcursor->mx_db.md_entries - ecount;
|
|
|
- }
|
|
|
- /* Increment count unless we just replaced an existing item. */
|
|
|
- if (insert_data)
|
|
|
- mc->mc_db->md_entries++;
|
|
|
- if (insert_key) {
|
|
|
- /* Invalidate txn if we created an empty sub-DB */
|
|
|
- if (rc)
|
|
|
- goto bad_sub;
|
|
|
- /* If we succeeded and the key didn't exist before,
|
|
|
- * make sure the cursor is marked valid.
|
|
|
- */
|
|
|
- mc->mc_flags |= C_INITIALIZED;
|
|
|
- }
|
|
|
- if (flags & MDB_MULTIPLE) {
|
|
|
- if (!rc) {
|
|
|
- mcount++;
|
|
|
- /* let caller know how many succeeded, if any */
|
|
|
- data[1].mv_size = mcount;
|
|
|
- if (mcount < dcount) {
|
|
|
- data[0].mv_data = (char *)data[0].mv_data + data[0].mv_size;
|
|
|
- insert_key = insert_data = 0;
|
|
|
- goto more;
|
|
|
- }
|
|
|
- }
|
|
|
- }
|
|
|
- return rc;
|
|
|
-bad_sub:
|
|
|
- if (rc == MDB_KEYEXIST) /* should not happen, we deleted that item */
|
|
|
- rc = MDB_CORRUPTED;
|
|
|
- }
|
|
|
- mc->mc_txn->mt_flags |= MDB_TXN_ERROR;
|
|
|
- return rc;
|
|
|
-}
|
|
|
-
|
|
|
-int
|
|
|
-mdb_cursor_del(MDB_cursor *mc, unsigned int flags)
|
|
|
-{
|
|
|
- MDB_node *leaf;
|
|
|
- MDB_page *mp;
|
|
|
- int rc;
|
|
|
-
|
|
|
- if (mc->mc_txn->mt_flags & (MDB_TXN_RDONLY|MDB_TXN_BLOCKED))
|
|
|
- return (mc->mc_txn->mt_flags & MDB_TXN_RDONLY) ? EACCES : MDB_BAD_TXN;
|
|
|
-
|
|
|
- if (!(mc->mc_flags & C_INITIALIZED))
|
|
|
- return EINVAL;
|
|
|
-
|
|
|
- if (mc->mc_ki[mc->mc_top] >= NUMKEYS(mc->mc_pg[mc->mc_top]))
|
|
|
- return MDB_NOTFOUND;
|
|
|
-
|
|
|
- if (!(flags & MDB_NOSPILL) && (rc = mdb_page_spill(mc, NULL, NULL)))
|
|
|
- return rc;
|
|
|
-
|
|
|
- rc = mdb_cursor_touch(mc);
|
|
|
- if (rc)
|
|
|
- return rc;
|
|
|
-
|
|
|
- mp = mc->mc_pg[mc->mc_top];
|
|
|
- if (IS_LEAF2(mp))
|
|
|
- goto del_key;
|
|
|
- leaf = NODEPTR(mp, mc->mc_ki[mc->mc_top]);
|
|
|
-
|
|
|
- if (F_ISSET(leaf->mn_flags, F_DUPDATA)) {
|
|
|
- if (flags & MDB_NODUPDATA) {
|
|
|
- /* mdb_cursor_del0() will subtract the final entry */
|
|
|
- mc->mc_db->md_entries -= mc->mc_xcursor->mx_db.md_entries - 1;
|
|
|
- mc->mc_xcursor->mx_cursor.mc_flags &= ~C_INITIALIZED;
|
|
|
- } else {
|
|
|
- if (!F_ISSET(leaf->mn_flags, F_SUBDATA)) {
|
|
|
- mc->mc_xcursor->mx_cursor.mc_pg[0] = NODEDATA(leaf);
|
|
|
- }
|
|
|
- rc = mdb_cursor_del(&mc->mc_xcursor->mx_cursor, MDB_NOSPILL);
|
|
|
- if (rc)
|
|
|
- return rc;
|
|
|
- /* If sub-DB still has entries, we're done */
|
|
|
- if (mc->mc_xcursor->mx_db.md_entries) {
|
|
|
- if (leaf->mn_flags & F_SUBDATA) {
|
|
|
- /* update subDB info */
|
|
|
- void *db = NODEDATA(leaf);
|
|
|
- memcpy(db, &mc->mc_xcursor->mx_db, sizeof(MDB_db));
|
|
|
- } else {
|
|
|
- MDB_cursor *m2;
|
|
|
- /* shrink fake page */
|
|
|
- mdb_node_shrink(mp, mc->mc_ki[mc->mc_top]);
|
|
|
- leaf = NODEPTR(mp, mc->mc_ki[mc->mc_top]);
|
|
|
- mc->mc_xcursor->mx_cursor.mc_pg[0] = NODEDATA(leaf);
|
|
|
- /* fix other sub-DB cursors pointed at fake pages on this page */
|
|
|
- for (m2 = mc->mc_txn->mt_cursors[mc->mc_dbi]; m2; m2=m2->mc_next) {
|
|
|
- if (m2 == mc || m2->mc_snum < mc->mc_snum) continue;
|
|
|
- if (!(m2->mc_flags & C_INITIALIZED)) continue;
|
|
|
- if (m2->mc_pg[mc->mc_top] == mp) {
|
|
|
- XCURSOR_REFRESH(m2, mc->mc_top, mp);
|
|
|
- }
|
|
|
- }
|
|
|
- }
|
|
|
- mc->mc_db->md_entries--;
|
|
|
- return rc;
|
|
|
- } else {
|
|
|
- mc->mc_xcursor->mx_cursor.mc_flags &= ~C_INITIALIZED;
|
|
|
- }
|
|
|
- /* otherwise fall thru and delete the sub-DB */
|
|
|
- }
|
|
|
-
|
|
|
- if (leaf->mn_flags & F_SUBDATA) {
|
|
|
- /* add all the child DB's pages to the free list */
|
|
|
- rc = mdb_drop0(&mc->mc_xcursor->mx_cursor, 0);
|
|
|
- if (rc)
|
|
|
- goto fail;
|
|
|
- }
|
|
|
- }
|
|
|
- /* LMDB passes F_SUBDATA in 'flags' to delete a DB record */
|
|
|
- else if ((leaf->mn_flags ^ flags) & F_SUBDATA) {
|
|
|
- rc = MDB_INCOMPATIBLE;
|
|
|
- goto fail;
|
|
|
- }
|
|
|
-
|
|
|
- /* add overflow pages to free list */
|
|
|
- if (F_ISSET(leaf->mn_flags, F_BIGDATA)) {
|
|
|
- MDB_page *omp;
|
|
|
- pgno_t pg;
|
|
|
-
|
|
|
- memcpy(&pg, NODEDATA(leaf), sizeof(pg));
|
|
|
- if ((rc = mdb_page_get(mc, pg, &omp, NULL)) ||
|
|
|
- (rc = mdb_ovpage_free(mc, omp)))
|
|
|
- goto fail;
|
|
|
- }
|
|
|
-
|
|
|
-del_key:
|
|
|
- return mdb_cursor_del0(mc);
|
|
|
-
|
|
|
-fail:
|
|
|
- mc->mc_txn->mt_flags |= MDB_TXN_ERROR;
|
|
|
- return rc;
|
|
|
-}
|
|
|
-
|
|
|
-/** Allocate and initialize new pages for a database.
|
|
|
- * Set #MDB_TXN_ERROR on failure.
|
|
|
- * @param[in] mc a cursor on the database being added to.
|
|
|
- * @param[in] flags flags defining what type of page is being allocated.
|
|
|
- * @param[in] num the number of pages to allocate. This is usually 1,
|
|
|
- * unless allocating overflow pages for a large record.
|
|
|
- * @param[out] mp Address of a page, or NULL on failure.
|
|
|
- * @return 0 on success, non-zero on failure.
|
|
|
- */
|
|
|
-static int
|
|
|
-mdb_page_new(MDB_cursor *mc, uint32_t flags, int num, MDB_page **mp)
|
|
|
-{
|
|
|
- MDB_page *np;
|
|
|
- int rc;
|
|
|
-
|
|
|
- if ((rc = mdb_page_alloc(mc, num, &np)))
|
|
|
- return rc;
|
|
|
- DPRINTF(("allocated new mpage %"Z"u, page size %u",
|
|
|
- np->mp_pgno, mc->mc_txn->mt_env->me_psize));
|
|
|
- np->mp_flags = flags | P_DIRTY;
|
|
|
- np->mp_lower = (PAGEHDRSZ-PAGEBASE);
|
|
|
- np->mp_upper = mc->mc_txn->mt_env->me_psize - PAGEBASE;
|
|
|
-
|
|
|
- if (IS_BRANCH(np))
|
|
|
- mc->mc_db->md_branch_pages++;
|
|
|
- else if (IS_LEAF(np))
|
|
|
- mc->mc_db->md_leaf_pages++;
|
|
|
- else if (IS_OVERFLOW(np)) {
|
|
|
- mc->mc_db->md_overflow_pages += num;
|
|
|
- np->mp_pages = num;
|
|
|
- }
|
|
|
- *mp = np;
|
|
|
-
|
|
|
- return 0;
|
|
|
-}
|
|
|
-
|
|
|
-/** Calculate the size of a leaf node.
|
|
|
- * The size depends on the environment's page size; if a data item
|
|
|
- * is too large it will be put onto an overflow page and the node
|
|
|
- * size will only include the key and not the data. Sizes are always
|
|
|
- * rounded up to an even number of bytes, to guarantee 2-byte alignment
|
|
|
- * of the #MDB_node headers.
|
|
|
- * @param[in] env The environment handle.
|
|
|
- * @param[in] key The key for the node.
|
|
|
- * @param[in] data The data for the node.
|
|
|
- * @return The number of bytes needed to store the node.
|
|
|
- */
|
|
|
-static size_t
|
|
|
-mdb_leaf_size(MDB_env *env, MDB_val *key, MDB_val *data)
|
|
|
-{
|
|
|
- size_t sz;
|
|
|
-
|
|
|
- sz = LEAFSIZE(key, data);
|
|
|
- if (sz > env->me_nodemax) {
|
|
|
- /* put on overflow page */
|
|
|
- sz -= data->mv_size - sizeof(pgno_t);
|
|
|
- }
|
|
|
-
|
|
|
- return EVEN(sz + sizeof(indx_t));
|
|
|
-}
|
|
|
-
|
|
|
-/** Calculate the size of a branch node.
|
|
|
- * The size should depend on the environment's page size but since
|
|
|
- * we currently don't support spilling large keys onto overflow
|
|
|
- * pages, it's simply the size of the #MDB_node header plus the
|
|
|
- * size of the key. Sizes are always rounded up to an even number
|
|
|
- * of bytes, to guarantee 2-byte alignment of the #MDB_node headers.
|
|
|
- * @param[in] env The environment handle.
|
|
|
- * @param[in] key The key for the node.
|
|
|
- * @return The number of bytes needed to store the node.
|
|
|
- */
|
|
|
-static size_t
|
|
|
-mdb_branch_size(MDB_env *env, MDB_val *key)
|
|
|
-{
|
|
|
- size_t sz;
|
|
|
-
|
|
|
- sz = INDXSIZE(key);
|
|
|
- if (sz > env->me_nodemax) {
|
|
|
- /* put on overflow page */
|
|
|
- /* not implemented */
|
|
|
- /* sz -= key->size - sizeof(pgno_t); */
|
|
|
- }
|
|
|
-
|
|
|
- return sz + sizeof(indx_t);
|
|
|
-}
|
|
|
-
|
|
|
-/** Add a node to the page pointed to by the cursor.
|
|
|
- * Set #MDB_TXN_ERROR on failure.
|
|
|
- * @param[in] mc The cursor for this operation.
|
|
|
- * @param[in] indx The index on the page where the new node should be added.
|
|
|
- * @param[in] key The key for the new node.
|
|
|
- * @param[in] data The data for the new node, if any.
|
|
|
- * @param[in] pgno The page number, if adding a branch node.
|
|
|
- * @param[in] flags Flags for the node.
|
|
|
- * @return 0 on success, non-zero on failure. Possible errors are:
|
|
|
- * <ul>
|
|
|
- * <li>ENOMEM - failed to allocate overflow pages for the node.
|
|
|
- * <li>MDB_PAGE_FULL - there is insufficient room in the page. This error
|
|
|
- * should never happen since all callers already calculate the
|
|
|
- * page's free space before calling this function.
|
|
|
- * </ul>
|
|
|
- */
|
|
|
-static int
|
|
|
-mdb_node_add(MDB_cursor *mc, indx_t indx,
|
|
|
- MDB_val *key, MDB_val *data, pgno_t pgno, unsigned int flags)
|
|
|
-{
|
|
|
- unsigned int i;
|
|
|
- size_t node_size = NODESIZE;
|
|
|
- ssize_t room;
|
|
|
- indx_t ofs;
|
|
|
- MDB_node *node;
|
|
|
- MDB_page *mp = mc->mc_pg[mc->mc_top];
|
|
|
- MDB_page *ofp = NULL; /* overflow page */
|
|
|
- void *ndata;
|
|
|
- DKBUF;
|
|
|
-
|
|
|
- mdb_cassert(mc, mp->mp_upper >= mp->mp_lower);
|
|
|
-
|
|
|
- DPRINTF(("add to %s %spage %"Z"u index %i, data size %"Z"u key size %"Z"u [%s]",
|
|
|
- IS_LEAF(mp) ? "leaf" : "branch",
|
|
|
- IS_SUBP(mp) ? "sub-" : "",
|
|
|
- mdb_dbg_pgno(mp), indx, data ? data->mv_size : 0,
|
|
|
- key ? key->mv_size : 0, key ? DKEY(key) : "null"));
|
|
|
-
|
|
|
- if (IS_LEAF2(mp)) {
|
|
|
- /* Move higher keys up one slot. */
|
|
|
- int ksize = mc->mc_db->md_pad, dif;
|
|
|
- char *ptr = LEAF2KEY(mp, indx, ksize);
|
|
|
- dif = NUMKEYS(mp) - indx;
|
|
|
- if (dif > 0)
|
|
|
- memmove(ptr+ksize, ptr, dif*ksize);
|
|
|
- /* insert new key */
|
|
|
- memcpy(ptr, key->mv_data, ksize);
|
|
|
-
|
|
|
- /* Just using these for counting */
|
|
|
- mp->mp_lower += sizeof(indx_t);
|
|
|
- mp->mp_upper -= ksize - sizeof(indx_t);
|
|
|
- return MDB_SUCCESS;
|
|
|
- }
|
|
|
-
|
|
|
- room = (ssize_t)SIZELEFT(mp) - (ssize_t)sizeof(indx_t);
|
|
|
- if (key != NULL)
|
|
|
- node_size += key->mv_size;
|
|
|
- if (IS_LEAF(mp)) {
|
|
|
- mdb_cassert(mc, key && data);
|
|
|
- if (F_ISSET(flags, F_BIGDATA)) {
|
|
|
- /* Data already on overflow page. */
|
|
|
- node_size += sizeof(pgno_t);
|
|
|
- } else if (node_size + data->mv_size > mc->mc_txn->mt_env->me_nodemax) {
|
|
|
- int ovpages = OVPAGES(data->mv_size, mc->mc_txn->mt_env->me_psize);
|
|
|
- int rc;
|
|
|
- /* Put data on overflow page. */
|
|
|
- DPRINTF(("data size is %"Z"u, node would be %"Z"u, put data on overflow page",
|
|
|
- data->mv_size, node_size+data->mv_size));
|
|
|
- node_size = EVEN(node_size + sizeof(pgno_t));
|
|
|
- if ((ssize_t)node_size > room)
|
|
|
- goto full;
|
|
|
- if ((rc = mdb_page_new(mc, P_OVERFLOW, ovpages, &ofp)))
|
|
|
- return rc;
|
|
|
- DPRINTF(("allocated overflow page %"Z"u", ofp->mp_pgno));
|
|
|
- flags |= F_BIGDATA;
|
|
|
- goto update;
|
|
|
- } else {
|
|
|
- node_size += data->mv_size;
|
|
|
- }
|
|
|
- }
|
|
|
- node_size = EVEN(node_size);
|
|
|
- if ((ssize_t)node_size > room)
|
|
|
- goto full;
|
|
|
-
|
|
|
-update:
|
|
|
- /* Move higher pointers up one slot. */
|
|
|
- for (i = NUMKEYS(mp); i > indx; i--)
|
|
|
- mp->mp_ptrs[i] = mp->mp_ptrs[i - 1];
|
|
|
-
|
|
|
- /* Adjust free space offsets. */
|
|
|
- ofs = mp->mp_upper - node_size;
|
|
|
- mdb_cassert(mc, ofs >= mp->mp_lower + sizeof(indx_t));
|
|
|
- mp->mp_ptrs[indx] = ofs;
|
|
|
- mp->mp_upper = ofs;
|
|
|
- mp->mp_lower += sizeof(indx_t);
|
|
|
-
|
|
|
- /* Write the node data. */
|
|
|
- node = NODEPTR(mp, indx);
|
|
|
- node->mn_ksize = (key == NULL) ? 0 : key->mv_size;
|
|
|
- node->mn_flags = flags;
|
|
|
- if (IS_LEAF(mp))
|
|
|
- SETDSZ(node,data->mv_size);
|
|
|
- else
|
|
|
- SETPGNO(node,pgno);
|
|
|
-
|
|
|
- if (key)
|
|
|
- memcpy(NODEKEY(node), key->mv_data, key->mv_size);
|
|
|
-
|
|
|
- if (IS_LEAF(mp)) {
|
|
|
- ndata = NODEDATA(node);
|
|
|
- if (ofp == NULL) {
|
|
|
- if (F_ISSET(flags, F_BIGDATA))
|
|
|
- memcpy(ndata, data->mv_data, sizeof(pgno_t));
|
|
|
- else if (F_ISSET(flags, MDB_RESERVE))
|
|
|
- data->mv_data = ndata;
|
|
|
- else
|
|
|
- memcpy(ndata, data->mv_data, data->mv_size);
|
|
|
- } else {
|
|
|
- memcpy(ndata, &ofp->mp_pgno, sizeof(pgno_t));
|
|
|
- ndata = METADATA(ofp);
|
|
|
- if (F_ISSET(flags, MDB_RESERVE))
|
|
|
- data->mv_data = ndata;
|
|
|
- else
|
|
|
- memcpy(ndata, data->mv_data, data->mv_size);
|
|
|
- }
|
|
|
- }
|
|
|
-
|
|
|
- return MDB_SUCCESS;
|
|
|
-
|
|
|
-full:
|
|
|
- DPRINTF(("not enough room in page %"Z"u, got %u ptrs",
|
|
|
- mdb_dbg_pgno(mp), NUMKEYS(mp)));
|
|
|
- DPRINTF(("upper-lower = %u - %u = %"Z"d", mp->mp_upper,mp->mp_lower,room));
|
|
|
- DPRINTF(("node size = %"Z"u", node_size));
|
|
|
- mc->mc_txn->mt_flags |= MDB_TXN_ERROR;
|
|
|
- return MDB_PAGE_FULL;
|
|
|
-}
|
|
|
-
|
|
|
-/** Delete the specified node from a page.
|
|
|
- * @param[in] mc Cursor pointing to the node to delete.
|
|
|
- * @param[in] ksize The size of a node. Only used if the page is
|
|
|
- * part of a #MDB_DUPFIXED database.
|
|
|
- */
|
|
|
-static void
|
|
|
-mdb_node_del(MDB_cursor *mc, int ksize)
|
|
|
-{
|
|
|
- MDB_page *mp = mc->mc_pg[mc->mc_top];
|
|
|
- indx_t indx = mc->mc_ki[mc->mc_top];
|
|
|
- unsigned int sz;
|
|
|
- indx_t i, j, numkeys, ptr;
|
|
|
- MDB_node *node;
|
|
|
- char *base;
|
|
|
-
|
|
|
- DPRINTF(("delete node %u on %s page %"Z"u", indx,
|
|
|
- IS_LEAF(mp) ? "leaf" : "branch", mdb_dbg_pgno(mp)));
|
|
|
- numkeys = NUMKEYS(mp);
|
|
|
- mdb_cassert(mc, indx < numkeys);
|
|
|
-
|
|
|
- if (IS_LEAF2(mp)) {
|
|
|
- int x = numkeys - 1 - indx;
|
|
|
- base = LEAF2KEY(mp, indx, ksize);
|
|
|
- if (x)
|
|
|
- memmove(base, base + ksize, x * ksize);
|
|
|
- mp->mp_lower -= sizeof(indx_t);
|
|
|
- mp->mp_upper += ksize - sizeof(indx_t);
|
|
|
- return;
|
|
|
- }
|
|
|
-
|
|
|
- node = NODEPTR(mp, indx);
|
|
|
- sz = NODESIZE + node->mn_ksize;
|
|
|
- if (IS_LEAF(mp)) {
|
|
|
- if (F_ISSET(node->mn_flags, F_BIGDATA))
|
|
|
- sz += sizeof(pgno_t);
|
|
|
- else
|
|
|
- sz += NODEDSZ(node);
|
|
|
- }
|
|
|
- sz = EVEN(sz);
|
|
|
-
|
|
|
- ptr = mp->mp_ptrs[indx];
|
|
|
- for (i = j = 0; i < numkeys; i++) {
|
|
|
- if (i != indx) {
|
|
|
- mp->mp_ptrs[j] = mp->mp_ptrs[i];
|
|
|
- if (mp->mp_ptrs[i] < ptr)
|
|
|
- mp->mp_ptrs[j] += sz;
|
|
|
- j++;
|
|
|
- }
|
|
|
- }
|
|
|
-
|
|
|
- base = (char *)mp + mp->mp_upper + PAGEBASE;
|
|
|
- memmove(base + sz, base, ptr - mp->mp_upper);
|
|
|
-
|
|
|
- mp->mp_lower -= sizeof(indx_t);
|
|
|
- mp->mp_upper += sz;
|
|
|
-}
|
|
|
-
|
|
|
-/** Compact the main page after deleting a node on a subpage.
|
|
|
- * @param[in] mp The main page to operate on.
|
|
|
- * @param[in] indx The index of the subpage on the main page.
|
|
|
- */
|
|
|
-static void
|
|
|
-mdb_node_shrink(MDB_page *mp, indx_t indx)
|
|
|
-{
|
|
|
- MDB_node *node;
|
|
|
- MDB_page *sp, *xp;
|
|
|
- char *base;
|
|
|
- indx_t delta, nsize, len, ptr;
|
|
|
- int i;
|
|
|
-
|
|
|
- node = NODEPTR(mp, indx);
|
|
|
- sp = (MDB_page *)NODEDATA(node);
|
|
|
- delta = SIZELEFT(sp);
|
|
|
- nsize = NODEDSZ(node) - delta;
|
|
|
-
|
|
|
- /* Prepare to shift upward, set len = length(subpage part to shift) */
|
|
|
- if (IS_LEAF2(sp)) {
|
|
|
- len = nsize;
|
|
|
- if (nsize & 1)
|
|
|
- return; /* do not make the node uneven-sized */
|
|
|
- } else {
|
|
|
- xp = (MDB_page *)((char *)sp + delta); /* destination subpage */
|
|
|
- for (i = NUMKEYS(sp); --i >= 0; )
|
|
|
- xp->mp_ptrs[i] = sp->mp_ptrs[i] - delta;
|
|
|
- len = PAGEHDRSZ;
|
|
|
- }
|
|
|
- sp->mp_upper = sp->mp_lower;
|
|
|
- COPY_PGNO(sp->mp_pgno, mp->mp_pgno);
|
|
|
- SETDSZ(node, nsize);
|
|
|
-
|
|
|
- /* Shift <lower nodes...initial part of subpage> upward */
|
|
|
- base = (char *)mp + mp->mp_upper + PAGEBASE;
|
|
|
- memmove(base + delta, base, (char *)sp + len - base);
|
|
|
-
|
|
|
- ptr = mp->mp_ptrs[indx];
|
|
|
- for (i = NUMKEYS(mp); --i >= 0; ) {
|
|
|
- if (mp->mp_ptrs[i] <= ptr)
|
|
|
- mp->mp_ptrs[i] += delta;
|
|
|
- }
|
|
|
- mp->mp_upper += delta;
|
|
|
-}
|
|
|
-
|
|
|
-/** Initial setup of a sorted-dups cursor.
|
|
|
- * Sorted duplicates are implemented as a sub-database for the given key.
|
|
|
- * The duplicate data items are actually keys of the sub-database.
|
|
|
- * Operations on the duplicate data items are performed using a sub-cursor
|
|
|
- * initialized when the sub-database is first accessed. This function does
|
|
|
- * the preliminary setup of the sub-cursor, filling in the fields that
|
|
|
- * depend only on the parent DB.
|
|
|
- * @param[in] mc The main cursor whose sorted-dups cursor is to be initialized.
|
|
|
- */
|
|
|
-static void
|
|
|
-mdb_xcursor_init0(MDB_cursor *mc)
|
|
|
-{
|
|
|
- MDB_xcursor *mx = mc->mc_xcursor;
|
|
|
-
|
|
|
- mx->mx_cursor.mc_xcursor = NULL;
|
|
|
- mx->mx_cursor.mc_txn = mc->mc_txn;
|
|
|
- mx->mx_cursor.mc_db = &mx->mx_db;
|
|
|
- mx->mx_cursor.mc_dbx = &mx->mx_dbx;
|
|
|
- mx->mx_cursor.mc_dbi = mc->mc_dbi;
|
|
|
- mx->mx_cursor.mc_dbflag = &mx->mx_dbflag;
|
|
|
- mx->mx_cursor.mc_snum = 0;
|
|
|
- mx->mx_cursor.mc_top = 0;
|
|
|
- mx->mx_cursor.mc_flags = C_SUB;
|
|
|
- mx->mx_dbx.md_name.mv_size = 0;
|
|
|
- mx->mx_dbx.md_name.mv_data = NULL;
|
|
|
- mx->mx_dbx.md_cmp = mc->mc_dbx->md_dcmp;
|
|
|
- mx->mx_dbx.md_dcmp = NULL;
|
|
|
- mx->mx_dbx.md_rel = mc->mc_dbx->md_rel;
|
|
|
-}
|
|
|
-
|
|
|
-/** Final setup of a sorted-dups cursor.
|
|
|
- * Sets up the fields that depend on the data from the main cursor.
|
|
|
- * @param[in] mc The main cursor whose sorted-dups cursor is to be initialized.
|
|
|
- * @param[in] node The data containing the #MDB_db record for the
|
|
|
- * sorted-dup database.
|
|
|
- */
|
|
|
-static void
|
|
|
-mdb_xcursor_init1(MDB_cursor *mc, MDB_node *node)
|
|
|
-{
|
|
|
- MDB_xcursor *mx = mc->mc_xcursor;
|
|
|
-
|
|
|
- if (node->mn_flags & F_SUBDATA) {
|
|
|
- memcpy(&mx->mx_db, NODEDATA(node), sizeof(MDB_db));
|
|
|
- mx->mx_cursor.mc_pg[0] = 0;
|
|
|
- mx->mx_cursor.mc_snum = 0;
|
|
|
- mx->mx_cursor.mc_top = 0;
|
|
|
- mx->mx_cursor.mc_flags = C_SUB;
|
|
|
- } else {
|
|
|
- MDB_page *fp = NODEDATA(node);
|
|
|
- mx->mx_db.md_pad = 0;
|
|
|
- mx->mx_db.md_flags = 0;
|
|
|
- mx->mx_db.md_depth = 1;
|
|
|
- mx->mx_db.md_branch_pages = 0;
|
|
|
- mx->mx_db.md_leaf_pages = 1;
|
|
|
- mx->mx_db.md_overflow_pages = 0;
|
|
|
- mx->mx_db.md_entries = NUMKEYS(fp);
|
|
|
- COPY_PGNO(mx->mx_db.md_root, fp->mp_pgno);
|
|
|
- mx->mx_cursor.mc_snum = 1;
|
|
|
- mx->mx_cursor.mc_top = 0;
|
|
|
- mx->mx_cursor.mc_flags = C_INITIALIZED|C_SUB;
|
|
|
- mx->mx_cursor.mc_pg[0] = fp;
|
|
|
- mx->mx_cursor.mc_ki[0] = 0;
|
|
|
- if (mc->mc_db->md_flags & MDB_DUPFIXED) {
|
|
|
- mx->mx_db.md_flags = MDB_DUPFIXED;
|
|
|
- mx->mx_db.md_pad = fp->mp_pad;
|
|
|
- if (mc->mc_db->md_flags & MDB_INTEGERDUP)
|
|
|
- mx->mx_db.md_flags |= MDB_INTEGERKEY;
|
|
|
- }
|
|
|
- }
|
|
|
- DPRINTF(("Sub-db -%u root page %"Z"u", mx->mx_cursor.mc_dbi,
|
|
|
- mx->mx_db.md_root));
|
|
|
- mx->mx_dbflag = DB_VALID|DB_USRVALID|DB_DUPDATA;
|
|
|
-#if UINT_MAX < SIZE_MAX
|
|
|
- if (mx->mx_dbx.md_cmp == mdb_cmp_int && mx->mx_db.md_pad == sizeof(size_t))
|
|
|
- mx->mx_dbx.md_cmp = mdb_cmp_clong;
|
|
|
-#endif
|
|
|
-}
|
|
|
-
|
|
|
-
|
|
|
-/** Fixup a sorted-dups cursor due to underlying update.
|
|
|
- * Sets up some fields that depend on the data from the main cursor.
|
|
|
- * Almost the same as init1, but skips initialization steps if the
|
|
|
- * xcursor had already been used.
|
|
|
- * @param[in] mc The main cursor whose sorted-dups cursor is to be fixed up.
|
|
|
- * @param[in] src_mx The xcursor of an up-to-date cursor.
|
|
|
- * @param[in] new_dupdata True if converting from a non-#F_DUPDATA item.
|
|
|
- */
|
|
|
-static void
|
|
|
-mdb_xcursor_init2(MDB_cursor *mc, MDB_xcursor *src_mx, int new_dupdata)
|
|
|
-{
|
|
|
- MDB_xcursor *mx = mc->mc_xcursor;
|
|
|
-
|
|
|
- if (new_dupdata) {
|
|
|
- mx->mx_cursor.mc_snum = 1;
|
|
|
- mx->mx_cursor.mc_top = 0;
|
|
|
- mx->mx_cursor.mc_flags |= C_INITIALIZED;
|
|
|
- mx->mx_cursor.mc_ki[0] = 0;
|
|
|
- mx->mx_dbflag = DB_VALID|DB_USRVALID|DB_DUPDATA;
|
|
|
-#if UINT_MAX < SIZE_MAX
|
|
|
- mx->mx_dbx.md_cmp = src_mx->mx_dbx.md_cmp;
|
|
|
-#endif
|
|
|
- } else if (!(mx->mx_cursor.mc_flags & C_INITIALIZED)) {
|
|
|
- return;
|
|
|
- }
|
|
|
- mx->mx_db = src_mx->mx_db;
|
|
|
- mx->mx_cursor.mc_pg[0] = src_mx->mx_cursor.mc_pg[0];
|
|
|
- DPRINTF(("Sub-db -%u root page %"Z"u", mx->mx_cursor.mc_dbi,
|
|
|
- mx->mx_db.md_root));
|
|
|
-}
|
|
|
-
|
|
|
-/** Initialize a cursor for a given transaction and database. */
|
|
|
-static void
|
|
|
-mdb_cursor_init(MDB_cursor *mc, MDB_txn *txn, MDB_dbi dbi, MDB_xcursor *mx)
|
|
|
-{
|
|
|
- mc->mc_next = NULL;
|
|
|
- mc->mc_backup = NULL;
|
|
|
- mc->mc_dbi = dbi;
|
|
|
- mc->mc_txn = txn;
|
|
|
- mc->mc_db = &txn->mt_dbs[dbi];
|
|
|
- mc->mc_dbx = &txn->mt_dbxs[dbi];
|
|
|
- mc->mc_dbflag = &txn->mt_dbflags[dbi];
|
|
|
- mc->mc_snum = 0;
|
|
|
- mc->mc_top = 0;
|
|
|
- mc->mc_pg[0] = 0;
|
|
|
- mc->mc_ki[0] = 0;
|
|
|
- mc->mc_flags = 0;
|
|
|
- if (txn->mt_dbs[dbi].md_flags & MDB_DUPSORT) {
|
|
|
- mdb_tassert(txn, mx != NULL);
|
|
|
- mc->mc_xcursor = mx;
|
|
|
- mdb_xcursor_init0(mc);
|
|
|
- } else {
|
|
|
- mc->mc_xcursor = NULL;
|
|
|
- }
|
|
|
- if (*mc->mc_dbflag & DB_STALE) {
|
|
|
- mdb_page_search(mc, NULL, MDB_PS_ROOTONLY);
|
|
|
- }
|
|
|
-}
|
|
|
-
|
|
|
-int
|
|
|
-mdb_cursor_open(MDB_txn *txn, MDB_dbi dbi, MDB_cursor **ret)
|
|
|
-{
|
|
|
- MDB_cursor *mc;
|
|
|
- size_t size = sizeof(MDB_cursor);
|
|
|
-
|
|
|
- if (!ret || !TXN_DBI_EXIST(txn, dbi, DB_VALID))
|
|
|
- return EINVAL;
|
|
|
-
|
|
|
- if (txn->mt_flags & MDB_TXN_BLOCKED)
|
|
|
- return MDB_BAD_TXN;
|
|
|
-
|
|
|
- if (dbi == FREE_DBI && !F_ISSET(txn->mt_flags, MDB_TXN_RDONLY))
|
|
|
- return EINVAL;
|
|
|
-
|
|
|
- if (txn->mt_dbs[dbi].md_flags & MDB_DUPSORT)
|
|
|
- size += sizeof(MDB_xcursor);
|
|
|
-
|
|
|
- if ((mc = malloc(size)) != NULL) {
|
|
|
- mdb_cursor_init(mc, txn, dbi, (MDB_xcursor *)(mc + 1));
|
|
|
- if (txn->mt_cursors) {
|
|
|
- mc->mc_next = txn->mt_cursors[dbi];
|
|
|
- txn->mt_cursors[dbi] = mc;
|
|
|
- mc->mc_flags |= C_UNTRACK;
|
|
|
- }
|
|
|
- } else {
|
|
|
- return ENOMEM;
|
|
|
- }
|
|
|
-
|
|
|
- *ret = mc;
|
|
|
-
|
|
|
- return MDB_SUCCESS;
|
|
|
-}
|
|
|
-
|
|
|
-int
|
|
|
-mdb_cursor_renew(MDB_txn *txn, MDB_cursor *mc)
|
|
|
-{
|
|
|
- if (!mc || !TXN_DBI_EXIST(txn, mc->mc_dbi, DB_VALID))
|
|
|
- return EINVAL;
|
|
|
-
|
|
|
- if ((mc->mc_flags & C_UNTRACK) || txn->mt_cursors)
|
|
|
- return EINVAL;
|
|
|
-
|
|
|
- if (txn->mt_flags & MDB_TXN_BLOCKED)
|
|
|
- return MDB_BAD_TXN;
|
|
|
-
|
|
|
- mdb_cursor_init(mc, txn, mc->mc_dbi, mc->mc_xcursor);
|
|
|
- return MDB_SUCCESS;
|
|
|
-}
|
|
|
-
|
|
|
-/* Return the count of duplicate data items for the current key */
|
|
|
-int
|
|
|
-mdb_cursor_count(MDB_cursor *mc, size_t *countp)
|
|
|
-{
|
|
|
- MDB_node *leaf;
|
|
|
-
|
|
|
- if (mc == NULL || countp == NULL)
|
|
|
- return EINVAL;
|
|
|
-
|
|
|
- if (mc->mc_xcursor == NULL)
|
|
|
- return MDB_INCOMPATIBLE;
|
|
|
-
|
|
|
- if (mc->mc_txn->mt_flags & MDB_TXN_BLOCKED)
|
|
|
- return MDB_BAD_TXN;
|
|
|
-
|
|
|
- if (!(mc->mc_flags & C_INITIALIZED))
|
|
|
- return EINVAL;
|
|
|
-
|
|
|
- if (!mc->mc_snum)
|
|
|
- return MDB_NOTFOUND;
|
|
|
-
|
|
|
- if (mc->mc_flags & C_EOF) {
|
|
|
- if (mc->mc_ki[mc->mc_top] >= NUMKEYS(mc->mc_pg[mc->mc_top]))
|
|
|
- return MDB_NOTFOUND;
|
|
|
- mc->mc_flags ^= C_EOF;
|
|
|
- }
|
|
|
-
|
|
|
- leaf = NODEPTR(mc->mc_pg[mc->mc_top], mc->mc_ki[mc->mc_top]);
|
|
|
- if (!F_ISSET(leaf->mn_flags, F_DUPDATA)) {
|
|
|
- *countp = 1;
|
|
|
- } else {
|
|
|
- if (!(mc->mc_xcursor->mx_cursor.mc_flags & C_INITIALIZED))
|
|
|
- return EINVAL;
|
|
|
-
|
|
|
- *countp = mc->mc_xcursor->mx_db.md_entries;
|
|
|
- }
|
|
|
- return MDB_SUCCESS;
|
|
|
-}
|
|
|
-
|
|
|
-void
|
|
|
-mdb_cursor_close(MDB_cursor *mc)
|
|
|
-{
|
|
|
- if (mc && !mc->mc_backup) {
|
|
|
- /* remove from txn, if tracked */
|
|
|
- if ((mc->mc_flags & C_UNTRACK) && mc->mc_txn->mt_cursors) {
|
|
|
- MDB_cursor **prev = &mc->mc_txn->mt_cursors[mc->mc_dbi];
|
|
|
- while (*prev && *prev != mc) prev = &(*prev)->mc_next;
|
|
|
- if (*prev == mc)
|
|
|
- *prev = mc->mc_next;
|
|
|
- }
|
|
|
- free(mc);
|
|
|
- }
|
|
|
-}
|
|
|
-
|
|
|
-MDB_txn *
|
|
|
-mdb_cursor_txn(MDB_cursor *mc)
|
|
|
-{
|
|
|
- if (!mc) return NULL;
|
|
|
- return mc->mc_txn;
|
|
|
-}
|
|
|
-
|
|
|
-MDB_dbi
|
|
|
-mdb_cursor_dbi(MDB_cursor *mc)
|
|
|
-{
|
|
|
- return mc->mc_dbi;
|
|
|
-}
|
|
|
-
|
|
|
-/** Replace the key for a branch node with a new key.
|
|
|
- * Set #MDB_TXN_ERROR on failure.
|
|
|
- * @param[in] mc Cursor pointing to the node to operate on.
|
|
|
- * @param[in] key The new key to use.
|
|
|
- * @return 0 on success, non-zero on failure.
|
|
|
- */
|
|
|
-static int
|
|
|
-mdb_update_key(MDB_cursor *mc, MDB_val *key)
|
|
|
-{
|
|
|
- MDB_page *mp;
|
|
|
- MDB_node *node;
|
|
|
- char *base;
|
|
|
- size_t len;
|
|
|
- int delta, ksize, oksize;
|
|
|
- indx_t ptr, i, numkeys, indx;
|
|
|
- DKBUF;
|
|
|
-
|
|
|
- indx = mc->mc_ki[mc->mc_top];
|
|
|
- mp = mc->mc_pg[mc->mc_top];
|
|
|
- node = NODEPTR(mp, indx);
|
|
|
- ptr = mp->mp_ptrs[indx];
|
|
|
-#if MDB_DEBUG
|
|
|
- {
|
|
|
- MDB_val k2;
|
|
|
- char kbuf2[DKBUF_MAXKEYSIZE*2+1];
|
|
|
- k2.mv_data = NODEKEY(node);
|
|
|
- k2.mv_size = node->mn_ksize;
|
|
|
- DPRINTF(("update key %u (ofs %u) [%s] to [%s] on page %"Z"u",
|
|
|
- indx, ptr,
|
|
|
- mdb_dkey(&k2, kbuf2),
|
|
|
- DKEY(key),
|
|
|
- mp->mp_pgno));
|
|
|
- }
|
|
|
-#endif
|
|
|
-
|
|
|
- /* Sizes must be 2-byte aligned. */
|
|
|
- ksize = EVEN(key->mv_size);
|
|
|
- oksize = EVEN(node->mn_ksize);
|
|
|
- delta = ksize - oksize;
|
|
|
-
|
|
|
- /* Shift node contents if EVEN(key length) changed. */
|
|
|
- if (delta) {
|
|
|
- if (delta > 0 && SIZELEFT(mp) < delta) {
|
|
|
- pgno_t pgno;
|
|
|
- /* not enough space left, do a delete and split */
|
|
|
- DPRINTF(("Not enough room, delta = %d, splitting...", delta));
|
|
|
- pgno = NODEPGNO(node);
|
|
|
- mdb_node_del(mc, 0);
|
|
|
- return mdb_page_split(mc, key, NULL, pgno, MDB_SPLIT_REPLACE);
|
|
|
- }
|
|
|
-
|
|
|
- numkeys = NUMKEYS(mp);
|
|
|
- for (i = 0; i < numkeys; i++) {
|
|
|
- if (mp->mp_ptrs[i] <= ptr)
|
|
|
- mp->mp_ptrs[i] -= delta;
|
|
|
- }
|
|
|
-
|
|
|
- base = (char *)mp + mp->mp_upper + PAGEBASE;
|
|
|
- len = ptr - mp->mp_upper + NODESIZE;
|
|
|
- memmove(base - delta, base, len);
|
|
|
- mp->mp_upper -= delta;
|
|
|
-
|
|
|
- node = NODEPTR(mp, indx);
|
|
|
- }
|
|
|
-
|
|
|
- /* But even if no shift was needed, update ksize */
|
|
|
- if (node->mn_ksize != key->mv_size)
|
|
|
- node->mn_ksize = key->mv_size;
|
|
|
-
|
|
|
- if (key->mv_size)
|
|
|
- memcpy(NODEKEY(node), key->mv_data, key->mv_size);
|
|
|
-
|
|
|
- return MDB_SUCCESS;
|
|
|
-}
|
|
|
-
|
|
|
-static void
|
|
|
-mdb_cursor_copy(const MDB_cursor *csrc, MDB_cursor *cdst);
|
|
|
-
|
|
|
-/** Perform \b act while tracking temporary cursor \b mn */
|
|
|
-#define WITH_CURSOR_TRACKING(mn, act) do { \
|
|
|
- MDB_cursor dummy, *tracked, **tp = &(mn).mc_txn->mt_cursors[mn.mc_dbi]; \
|
|
|
- if ((mn).mc_flags & C_SUB) { \
|
|
|
- dummy.mc_flags = C_INITIALIZED; \
|
|
|
- dummy.mc_xcursor = (MDB_xcursor *)&(mn); \
|
|
|
- tracked = &dummy; \
|
|
|
- } else { \
|
|
|
- tracked = &(mn); \
|
|
|
- } \
|
|
|
- tracked->mc_next = *tp; \
|
|
|
- *tp = tracked; \
|
|
|
- { act; } \
|
|
|
- *tp = tracked->mc_next; \
|
|
|
-} while (0)
|
|
|
-
|
|
|
-/** Move a node from csrc to cdst.
|
|
|
- */
|
|
|
-static int
|
|
|
-mdb_node_move(MDB_cursor *csrc, MDB_cursor *cdst, int fromleft)
|
|
|
-{
|
|
|
- MDB_node *srcnode;
|
|
|
- MDB_val key, data;
|
|
|
- pgno_t srcpg;
|
|
|
- MDB_cursor mn;
|
|
|
- int rc;
|
|
|
- unsigned short flags;
|
|
|
-
|
|
|
- DKBUF;
|
|
|
-
|
|
|
- /* Mark src and dst as dirty. */
|
|
|
- if ((rc = mdb_page_touch(csrc)) ||
|
|
|
- (rc = mdb_page_touch(cdst)))
|
|
|
- return rc;
|
|
|
-
|
|
|
- if (IS_LEAF2(csrc->mc_pg[csrc->mc_top])) {
|
|
|
- key.mv_size = csrc->mc_db->md_pad;
|
|
|
- key.mv_data = LEAF2KEY(csrc->mc_pg[csrc->mc_top], csrc->mc_ki[csrc->mc_top], key.mv_size);
|
|
|
- data.mv_size = 0;
|
|
|
- data.mv_data = NULL;
|
|
|
- srcpg = 0;
|
|
|
- flags = 0;
|
|
|
- } else {
|
|
|
- srcnode = NODEPTR(csrc->mc_pg[csrc->mc_top], csrc->mc_ki[csrc->mc_top]);
|
|
|
- mdb_cassert(csrc, !((size_t)srcnode & 1));
|
|
|
- srcpg = NODEPGNO(srcnode);
|
|
|
- flags = srcnode->mn_flags;
|
|
|
- if (csrc->mc_ki[csrc->mc_top] == 0 && IS_BRANCH(csrc->mc_pg[csrc->mc_top])) {
|
|
|
- unsigned int snum = csrc->mc_snum;
|
|
|
- MDB_node *s2;
|
|
|
- /* must find the lowest key below src */
|
|
|
- rc = mdb_page_search_lowest(csrc);
|
|
|
- if (rc)
|
|
|
- return rc;
|
|
|
- if (IS_LEAF2(csrc->mc_pg[csrc->mc_top])) {
|
|
|
- key.mv_size = csrc->mc_db->md_pad;
|
|
|
- key.mv_data = LEAF2KEY(csrc->mc_pg[csrc->mc_top], 0, key.mv_size);
|
|
|
- } else {
|
|
|
- s2 = NODEPTR(csrc->mc_pg[csrc->mc_top], 0);
|
|
|
- key.mv_size = NODEKSZ(s2);
|
|
|
- key.mv_data = NODEKEY(s2);
|
|
|
- }
|
|
|
- csrc->mc_snum = snum--;
|
|
|
- csrc->mc_top = snum;
|
|
|
- } else {
|
|
|
- key.mv_size = NODEKSZ(srcnode);
|
|
|
- key.mv_data = NODEKEY(srcnode);
|
|
|
- }
|
|
|
- data.mv_size = NODEDSZ(srcnode);
|
|
|
- data.mv_data = NODEDATA(srcnode);
|
|
|
- }
|
|
|
- mn.mc_xcursor = NULL;
|
|
|
- if (IS_BRANCH(cdst->mc_pg[cdst->mc_top]) && cdst->mc_ki[cdst->mc_top] == 0) {
|
|
|
- unsigned int snum = cdst->mc_snum;
|
|
|
- MDB_node *s2;
|
|
|
- MDB_val bkey;
|
|
|
- /* must find the lowest key below dst */
|
|
|
- mdb_cursor_copy(cdst, &mn);
|
|
|
- rc = mdb_page_search_lowest(&mn);
|
|
|
- if (rc)
|
|
|
- return rc;
|
|
|
- if (IS_LEAF2(mn.mc_pg[mn.mc_top])) {
|
|
|
- bkey.mv_size = mn.mc_db->md_pad;
|
|
|
- bkey.mv_data = LEAF2KEY(mn.mc_pg[mn.mc_top], 0, bkey.mv_size);
|
|
|
- } else {
|
|
|
- s2 = NODEPTR(mn.mc_pg[mn.mc_top], 0);
|
|
|
- bkey.mv_size = NODEKSZ(s2);
|
|
|
- bkey.mv_data = NODEKEY(s2);
|
|
|
- }
|
|
|
- mn.mc_snum = snum--;
|
|
|
- mn.mc_top = snum;
|
|
|
- mn.mc_ki[snum] = 0;
|
|
|
- rc = mdb_update_key(&mn, &bkey);
|
|
|
- if (rc)
|
|
|
- return rc;
|
|
|
- }
|
|
|
-
|
|
|
- DPRINTF(("moving %s node %u [%s] on page %"Z"u to node %u on page %"Z"u",
|
|
|
- IS_LEAF(csrc->mc_pg[csrc->mc_top]) ? "leaf" : "branch",
|
|
|
- csrc->mc_ki[csrc->mc_top],
|
|
|
- DKEY(&key),
|
|
|
- csrc->mc_pg[csrc->mc_top]->mp_pgno,
|
|
|
- cdst->mc_ki[cdst->mc_top], cdst->mc_pg[cdst->mc_top]->mp_pgno));
|
|
|
-
|
|
|
- /* Add the node to the destination page.
|
|
|
- */
|
|
|
- rc = mdb_node_add(cdst, cdst->mc_ki[cdst->mc_top], &key, &data, srcpg, flags);
|
|
|
- if (rc != MDB_SUCCESS)
|
|
|
- return rc;
|
|
|
-
|
|
|
- /* Delete the node from the source page.
|
|
|
- */
|
|
|
- mdb_node_del(csrc, key.mv_size);
|
|
|
-
|
|
|
- {
|
|
|
- /* Adjust other cursors pointing to mp */
|
|
|
- MDB_cursor *m2, *m3;
|
|
|
- MDB_dbi dbi = csrc->mc_dbi;
|
|
|
- MDB_page *mpd, *mps;
|
|
|
-
|
|
|
- mps = csrc->mc_pg[csrc->mc_top];
|
|
|
- /* If we're adding on the left, bump others up */
|
|
|
- if (fromleft) {
|
|
|
- mpd = cdst->mc_pg[csrc->mc_top];
|
|
|
- for (m2 = csrc->mc_txn->mt_cursors[dbi]; m2; m2=m2->mc_next) {
|
|
|
- if (csrc->mc_flags & C_SUB)
|
|
|
- m3 = &m2->mc_xcursor->mx_cursor;
|
|
|
- else
|
|
|
- m3 = m2;
|
|
|
- if (!(m3->mc_flags & C_INITIALIZED) || m3->mc_top < csrc->mc_top)
|
|
|
- continue;
|
|
|
- if (m3 != cdst &&
|
|
|
- m3->mc_pg[csrc->mc_top] == mpd &&
|
|
|
- m3->mc_ki[csrc->mc_top] >= cdst->mc_ki[csrc->mc_top]) {
|
|
|
- m3->mc_ki[csrc->mc_top]++;
|
|
|
- }
|
|
|
- if (m3 !=csrc &&
|
|
|
- m3->mc_pg[csrc->mc_top] == mps &&
|
|
|
- m3->mc_ki[csrc->mc_top] == csrc->mc_ki[csrc->mc_top]) {
|
|
|
- m3->mc_pg[csrc->mc_top] = cdst->mc_pg[cdst->mc_top];
|
|
|
- m3->mc_ki[csrc->mc_top] = cdst->mc_ki[cdst->mc_top];
|
|
|
- m3->mc_ki[csrc->mc_top-1]++;
|
|
|
- }
|
|
|
- if (IS_LEAF(mps))
|
|
|
- XCURSOR_REFRESH(m3, csrc->mc_top, m3->mc_pg[csrc->mc_top]);
|
|
|
- }
|
|
|
- } else
|
|
|
- /* Adding on the right, bump others down */
|
|
|
- {
|
|
|
- for (m2 = csrc->mc_txn->mt_cursors[dbi]; m2; m2=m2->mc_next) {
|
|
|
- if (csrc->mc_flags & C_SUB)
|
|
|
- m3 = &m2->mc_xcursor->mx_cursor;
|
|
|
- else
|
|
|
- m3 = m2;
|
|
|
- if (m3 == csrc) continue;
|
|
|
- if (!(m3->mc_flags & C_INITIALIZED) || m3->mc_top < csrc->mc_top)
|
|
|
- continue;
|
|
|
- if (m3->mc_pg[csrc->mc_top] == mps) {
|
|
|
- if (!m3->mc_ki[csrc->mc_top]) {
|
|
|
- m3->mc_pg[csrc->mc_top] = cdst->mc_pg[cdst->mc_top];
|
|
|
- m3->mc_ki[csrc->mc_top] = cdst->mc_ki[cdst->mc_top];
|
|
|
- m3->mc_ki[csrc->mc_top-1]--;
|
|
|
- } else {
|
|
|
- m3->mc_ki[csrc->mc_top]--;
|
|
|
- }
|
|
|
- if (IS_LEAF(mps))
|
|
|
- XCURSOR_REFRESH(m3, csrc->mc_top, m3->mc_pg[csrc->mc_top]);
|
|
|
- }
|
|
|
- }
|
|
|
- }
|
|
|
- }
|
|
|
-
|
|
|
- /* Update the parent separators.
|
|
|
- */
|
|
|
- if (csrc->mc_ki[csrc->mc_top] == 0) {
|
|
|
- if (csrc->mc_ki[csrc->mc_top-1] != 0) {
|
|
|
- if (IS_LEAF2(csrc->mc_pg[csrc->mc_top])) {
|
|
|
- key.mv_data = LEAF2KEY(csrc->mc_pg[csrc->mc_top], 0, key.mv_size);
|
|
|
- } else {
|
|
|
- srcnode = NODEPTR(csrc->mc_pg[csrc->mc_top], 0);
|
|
|
- key.mv_size = NODEKSZ(srcnode);
|
|
|
- key.mv_data = NODEKEY(srcnode);
|
|
|
- }
|
|
|
- DPRINTF(("update separator for source page %"Z"u to [%s]",
|
|
|
- csrc->mc_pg[csrc->mc_top]->mp_pgno, DKEY(&key)));
|
|
|
- mdb_cursor_copy(csrc, &mn);
|
|
|
- mn.mc_snum--;
|
|
|
- mn.mc_top--;
|
|
|
- /* We want mdb_rebalance to find mn when doing fixups */
|
|
|
- WITH_CURSOR_TRACKING(mn,
|
|
|
- rc = mdb_update_key(&mn, &key));
|
|
|
- if (rc)
|
|
|
- return rc;
|
|
|
- }
|
|
|
- if (IS_BRANCH(csrc->mc_pg[csrc->mc_top])) {
|
|
|
- MDB_val nullkey;
|
|
|
- indx_t ix = csrc->mc_ki[csrc->mc_top];
|
|
|
- nullkey.mv_size = 0;
|
|
|
- csrc->mc_ki[csrc->mc_top] = 0;
|
|
|
- rc = mdb_update_key(csrc, &nullkey);
|
|
|
- csrc->mc_ki[csrc->mc_top] = ix;
|
|
|
- mdb_cassert(csrc, rc == MDB_SUCCESS);
|
|
|
- }
|
|
|
- }
|
|
|
-
|
|
|
- if (cdst->mc_ki[cdst->mc_top] == 0) {
|
|
|
- if (cdst->mc_ki[cdst->mc_top-1] != 0) {
|
|
|
- if (IS_LEAF2(csrc->mc_pg[csrc->mc_top])) {
|
|
|
- key.mv_data = LEAF2KEY(cdst->mc_pg[cdst->mc_top], 0, key.mv_size);
|
|
|
- } else {
|
|
|
- srcnode = NODEPTR(cdst->mc_pg[cdst->mc_top], 0);
|
|
|
- key.mv_size = NODEKSZ(srcnode);
|
|
|
- key.mv_data = NODEKEY(srcnode);
|
|
|
- }
|
|
|
- DPRINTF(("update separator for destination page %"Z"u to [%s]",
|
|
|
- cdst->mc_pg[cdst->mc_top]->mp_pgno, DKEY(&key)));
|
|
|
- mdb_cursor_copy(cdst, &mn);
|
|
|
- mn.mc_snum--;
|
|
|
- mn.mc_top--;
|
|
|
- /* We want mdb_rebalance to find mn when doing fixups */
|
|
|
- WITH_CURSOR_TRACKING(mn,
|
|
|
- rc = mdb_update_key(&mn, &key));
|
|
|
- if (rc)
|
|
|
- return rc;
|
|
|
- }
|
|
|
- if (IS_BRANCH(cdst->mc_pg[cdst->mc_top])) {
|
|
|
- MDB_val nullkey;
|
|
|
- indx_t ix = cdst->mc_ki[cdst->mc_top];
|
|
|
- nullkey.mv_size = 0;
|
|
|
- cdst->mc_ki[cdst->mc_top] = 0;
|
|
|
- rc = mdb_update_key(cdst, &nullkey);
|
|
|
- cdst->mc_ki[cdst->mc_top] = ix;
|
|
|
- mdb_cassert(cdst, rc == MDB_SUCCESS);
|
|
|
- }
|
|
|
- }
|
|
|
-
|
|
|
- return MDB_SUCCESS;
|
|
|
-}
|
|
|
-
|
|
|
-/** Merge one page into another.
|
|
|
- * The nodes from the page pointed to by \b csrc will
|
|
|
- * be copied to the page pointed to by \b cdst and then
|
|
|
- * the \b csrc page will be freed.
|
|
|
- * @param[in] csrc Cursor pointing to the source page.
|
|
|
- * @param[in] cdst Cursor pointing to the destination page.
|
|
|
- * @return 0 on success, non-zero on failure.
|
|
|
- */
|
|
|
-static int
|
|
|
-mdb_page_merge(MDB_cursor *csrc, MDB_cursor *cdst)
|
|
|
-{
|
|
|
- MDB_page *psrc, *pdst;
|
|
|
- MDB_node *srcnode;
|
|
|
- MDB_val key, data;
|
|
|
- unsigned nkeys;
|
|
|
- int rc;
|
|
|
- indx_t i, j;
|
|
|
-
|
|
|
- psrc = csrc->mc_pg[csrc->mc_top];
|
|
|
- pdst = cdst->mc_pg[cdst->mc_top];
|
|
|
-
|
|
|
- DPRINTF(("merging page %"Z"u into %"Z"u", psrc->mp_pgno, pdst->mp_pgno));
|
|
|
-
|
|
|
- mdb_cassert(csrc, csrc->mc_snum > 1); /* can't merge root page */
|
|
|
- mdb_cassert(csrc, cdst->mc_snum > 1);
|
|
|
-
|
|
|
- /* Mark dst as dirty. */
|
|
|
- if ((rc = mdb_page_touch(cdst)))
|
|
|
- return rc;
|
|
|
-
|
|
|
- /* get dst page again now that we've touched it. */
|
|
|
- pdst = cdst->mc_pg[cdst->mc_top];
|
|
|
-
|
|
|
- /* Move all nodes from src to dst.
|
|
|
- */
|
|
|
- j = nkeys = NUMKEYS(pdst);
|
|
|
- if (IS_LEAF2(psrc)) {
|
|
|
- key.mv_size = csrc->mc_db->md_pad;
|
|
|
- key.mv_data = METADATA(psrc);
|
|
|
- for (i = 0; i < NUMKEYS(psrc); i++, j++) {
|
|
|
- rc = mdb_node_add(cdst, j, &key, NULL, 0, 0);
|
|
|
- if (rc != MDB_SUCCESS)
|
|
|
- return rc;
|
|
|
- key.mv_data = (char *)key.mv_data + key.mv_size;
|
|
|
- }
|
|
|
- } else {
|
|
|
- for (i = 0; i < NUMKEYS(psrc); i++, j++) {
|
|
|
- srcnode = NODEPTR(psrc, i);
|
|
|
- if (i == 0 && IS_BRANCH(psrc)) {
|
|
|
- MDB_cursor mn;
|
|
|
- MDB_node *s2;
|
|
|
- mdb_cursor_copy(csrc, &mn);
|
|
|
- mn.mc_xcursor = NULL;
|
|
|
- /* must find the lowest key below src */
|
|
|
- rc = mdb_page_search_lowest(&mn);
|
|
|
- if (rc)
|
|
|
- return rc;
|
|
|
- if (IS_LEAF2(mn.mc_pg[mn.mc_top])) {
|
|
|
- key.mv_size = mn.mc_db->md_pad;
|
|
|
- key.mv_data = LEAF2KEY(mn.mc_pg[mn.mc_top], 0, key.mv_size);
|
|
|
- } else {
|
|
|
- s2 = NODEPTR(mn.mc_pg[mn.mc_top], 0);
|
|
|
- key.mv_size = NODEKSZ(s2);
|
|
|
- key.mv_data = NODEKEY(s2);
|
|
|
- }
|
|
|
- } else {
|
|
|
- key.mv_size = srcnode->mn_ksize;
|
|
|
- key.mv_data = NODEKEY(srcnode);
|
|
|
- }
|
|
|
-
|
|
|
- data.mv_size = NODEDSZ(srcnode);
|
|
|
- data.mv_data = NODEDATA(srcnode);
|
|
|
- rc = mdb_node_add(cdst, j, &key, &data, NODEPGNO(srcnode), srcnode->mn_flags);
|
|
|
- if (rc != MDB_SUCCESS)
|
|
|
- return rc;
|
|
|
- }
|
|
|
- }
|
|
|
-
|
|
|
- DPRINTF(("dst page %"Z"u now has %u keys (%.1f%% filled)",
|
|
|
- pdst->mp_pgno, NUMKEYS(pdst),
|
|
|
- (float)PAGEFILL(cdst->mc_txn->mt_env, pdst) / 10));
|
|
|
-
|
|
|
- /* Unlink the src page from parent and add to free list.
|
|
|
- */
|
|
|
- csrc->mc_top--;
|
|
|
- mdb_node_del(csrc, 0);
|
|
|
- if (csrc->mc_ki[csrc->mc_top] == 0) {
|
|
|
- key.mv_size = 0;
|
|
|
- rc = mdb_update_key(csrc, &key);
|
|
|
- if (rc) {
|
|
|
- csrc->mc_top++;
|
|
|
- return rc;
|
|
|
- }
|
|
|
- }
|
|
|
- csrc->mc_top++;
|
|
|
-
|
|
|
- psrc = csrc->mc_pg[csrc->mc_top];
|
|
|
- /* If not operating on FreeDB, allow this page to be reused
|
|
|
- * in this txn. Otherwise just add to free list.
|
|
|
- */
|
|
|
- rc = mdb_page_loose(csrc, psrc);
|
|
|
- if (rc)
|
|
|
- return rc;
|
|
|
- if (IS_LEAF(psrc))
|
|
|
- csrc->mc_db->md_leaf_pages--;
|
|
|
- else
|
|
|
- csrc->mc_db->md_branch_pages--;
|
|
|
- {
|
|
|
- /* Adjust other cursors pointing to mp */
|
|
|
- MDB_cursor *m2, *m3;
|
|
|
- MDB_dbi dbi = csrc->mc_dbi;
|
|
|
- unsigned int top = csrc->mc_top;
|
|
|
-
|
|
|
- for (m2 = csrc->mc_txn->mt_cursors[dbi]; m2; m2=m2->mc_next) {
|
|
|
- if (csrc->mc_flags & C_SUB)
|
|
|
- m3 = &m2->mc_xcursor->mx_cursor;
|
|
|
- else
|
|
|
- m3 = m2;
|
|
|
- if (m3 == csrc) continue;
|
|
|
- if (m3->mc_snum < csrc->mc_snum) continue;
|
|
|
- if (m3->mc_pg[top] == psrc) {
|
|
|
- m3->mc_pg[top] = pdst;
|
|
|
- m3->mc_ki[top] += nkeys;
|
|
|
- m3->mc_ki[top-1] = cdst->mc_ki[top-1];
|
|
|
- } else if (m3->mc_pg[top-1] == csrc->mc_pg[top-1] &&
|
|
|
- m3->mc_ki[top-1] > csrc->mc_ki[top-1]) {
|
|
|
- m3->mc_ki[top-1]--;
|
|
|
- }
|
|
|
- if (IS_LEAF(psrc))
|
|
|
- XCURSOR_REFRESH(m3, top, m3->mc_pg[top]);
|
|
|
- }
|
|
|
- }
|
|
|
- {
|
|
|
- unsigned int snum = cdst->mc_snum;
|
|
|
- uint16_t depth = cdst->mc_db->md_depth;
|
|
|
- mdb_cursor_pop(cdst);
|
|
|
- rc = mdb_rebalance(cdst);
|
|
|
- /* Did the tree height change? */
|
|
|
- if (depth != cdst->mc_db->md_depth)
|
|
|
- snum += cdst->mc_db->md_depth - depth;
|
|
|
- cdst->mc_snum = snum;
|
|
|
- cdst->mc_top = snum-1;
|
|
|
- }
|
|
|
- return rc;
|
|
|
-}
|
|
|
-
|
|
|
-/** Copy the contents of a cursor.
|
|
|
- * @param[in] csrc The cursor to copy from.
|
|
|
- * @param[out] cdst The cursor to copy to.
|
|
|
- */
|
|
|
-static void
|
|
|
-mdb_cursor_copy(const MDB_cursor *csrc, MDB_cursor *cdst)
|
|
|
-{
|
|
|
- unsigned int i;
|
|
|
-
|
|
|
- cdst->mc_txn = csrc->mc_txn;
|
|
|
- cdst->mc_dbi = csrc->mc_dbi;
|
|
|
- cdst->mc_db = csrc->mc_db;
|
|
|
- cdst->mc_dbx = csrc->mc_dbx;
|
|
|
- cdst->mc_snum = csrc->mc_snum;
|
|
|
- cdst->mc_top = csrc->mc_top;
|
|
|
- cdst->mc_flags = csrc->mc_flags;
|
|
|
-
|
|
|
- for (i=0; i<csrc->mc_snum; i++) {
|
|
|
- cdst->mc_pg[i] = csrc->mc_pg[i];
|
|
|
- cdst->mc_ki[i] = csrc->mc_ki[i];
|
|
|
- }
|
|
|
-}
|
|
|
-
|
|
|
-/** Rebalance the tree after a delete operation.
|
|
|
- * @param[in] mc Cursor pointing to the page where rebalancing
|
|
|
- * should begin.
|
|
|
- * @return 0 on success, non-zero on failure.
|
|
|
- */
|
|
|
-static int
|
|
|
-mdb_rebalance(MDB_cursor *mc)
|
|
|
-{
|
|
|
- MDB_node *node;
|
|
|
- int rc, fromleft;
|
|
|
- unsigned int ptop, minkeys, thresh;
|
|
|
- MDB_cursor mn;
|
|
|
- indx_t oldki;
|
|
|
-
|
|
|
- if (IS_BRANCH(mc->mc_pg[mc->mc_top])) {
|
|
|
- minkeys = 2;
|
|
|
- thresh = 1;
|
|
|
- } else {
|
|
|
- minkeys = 1;
|
|
|
- thresh = FILL_THRESHOLD;
|
|
|
- }
|
|
|
- DPRINTF(("rebalancing %s page %"Z"u (has %u keys, %.1f%% full)",
|
|
|
- IS_LEAF(mc->mc_pg[mc->mc_top]) ? "leaf" : "branch",
|
|
|
- mdb_dbg_pgno(mc->mc_pg[mc->mc_top]), NUMKEYS(mc->mc_pg[mc->mc_top]),
|
|
|
- (float)PAGEFILL(mc->mc_txn->mt_env, mc->mc_pg[mc->mc_top]) / 10));
|
|
|
-
|
|
|
- if (PAGEFILL(mc->mc_txn->mt_env, mc->mc_pg[mc->mc_top]) >= thresh &&
|
|
|
- NUMKEYS(mc->mc_pg[mc->mc_top]) >= minkeys) {
|
|
|
- DPRINTF(("no need to rebalance page %"Z"u, above fill threshold",
|
|
|
- mdb_dbg_pgno(mc->mc_pg[mc->mc_top])));
|
|
|
- return MDB_SUCCESS;
|
|
|
- }
|
|
|
-
|
|
|
- if (mc->mc_snum < 2) {
|
|
|
- MDB_page *mp = mc->mc_pg[0];
|
|
|
- if (IS_SUBP(mp)) {
|
|
|
- DPUTS("Can't rebalance a subpage, ignoring");
|
|
|
- return MDB_SUCCESS;
|
|
|
- }
|
|
|
- if (NUMKEYS(mp) == 0) {
|
|
|
- DPUTS("tree is completely empty");
|
|
|
- mc->mc_db->md_root = P_INVALID;
|
|
|
- mc->mc_db->md_depth = 0;
|
|
|
- mc->mc_db->md_leaf_pages = 0;
|
|
|
- rc = mdb_midl_append(&mc->mc_txn->mt_free_pgs, mp->mp_pgno);
|
|
|
- if (rc)
|
|
|
- return rc;
|
|
|
- /* Adjust cursors pointing to mp */
|
|
|
- mc->mc_snum = 0;
|
|
|
- mc->mc_top = 0;
|
|
|
- mc->mc_flags &= ~C_INITIALIZED;
|
|
|
- {
|
|
|
- MDB_cursor *m2, *m3;
|
|
|
- MDB_dbi dbi = mc->mc_dbi;
|
|
|
-
|
|
|
- for (m2 = mc->mc_txn->mt_cursors[dbi]; m2; m2=m2->mc_next) {
|
|
|
- if (mc->mc_flags & C_SUB)
|
|
|
- m3 = &m2->mc_xcursor->mx_cursor;
|
|
|
- else
|
|
|
- m3 = m2;
|
|
|
- if (!(m3->mc_flags & C_INITIALIZED) || (m3->mc_snum < mc->mc_snum))
|
|
|
- continue;
|
|
|
- if (m3->mc_pg[0] == mp) {
|
|
|
- m3->mc_snum = 0;
|
|
|
- m3->mc_top = 0;
|
|
|
- m3->mc_flags &= ~C_INITIALIZED;
|
|
|
- }
|
|
|
- }
|
|
|
- }
|
|
|
- } else if (IS_BRANCH(mp) && NUMKEYS(mp) == 1) {
|
|
|
- int i;
|
|
|
- DPUTS("collapsing root page!");
|
|
|
- rc = mdb_midl_append(&mc->mc_txn->mt_free_pgs, mp->mp_pgno);
|
|
|
- if (rc)
|
|
|
- return rc;
|
|
|
- mc->mc_db->md_root = NODEPGNO(NODEPTR(mp, 0));
|
|
|
- rc = mdb_page_get(mc, mc->mc_db->md_root, &mc->mc_pg[0], NULL);
|
|
|
- if (rc)
|
|
|
- return rc;
|
|
|
- mc->mc_db->md_depth--;
|
|
|
- mc->mc_db->md_branch_pages--;
|
|
|
- mc->mc_ki[0] = mc->mc_ki[1];
|
|
|
- for (i = 1; i<mc->mc_db->md_depth; i++) {
|
|
|
- mc->mc_pg[i] = mc->mc_pg[i+1];
|
|
|
- mc->mc_ki[i] = mc->mc_ki[i+1];
|
|
|
- }
|
|
|
- {
|
|
|
- /* Adjust other cursors pointing to mp */
|
|
|
- MDB_cursor *m2, *m3;
|
|
|
- MDB_dbi dbi = mc->mc_dbi;
|
|
|
-
|
|
|
- for (m2 = mc->mc_txn->mt_cursors[dbi]; m2; m2=m2->mc_next) {
|
|
|
- if (mc->mc_flags & C_SUB)
|
|
|
- m3 = &m2->mc_xcursor->mx_cursor;
|
|
|
- else
|
|
|
- m3 = m2;
|
|
|
- if (m3 == mc) continue;
|
|
|
- if (!(m3->mc_flags & C_INITIALIZED))
|
|
|
- continue;
|
|
|
- if (m3->mc_pg[0] == mp) {
|
|
|
- for (i=0; i<mc->mc_db->md_depth; i++) {
|
|
|
- m3->mc_pg[i] = m3->mc_pg[i+1];
|
|
|
- m3->mc_ki[i] = m3->mc_ki[i+1];
|
|
|
- }
|
|
|
- m3->mc_snum--;
|
|
|
- m3->mc_top--;
|
|
|
- }
|
|
|
- }
|
|
|
- }
|
|
|
- } else
|
|
|
- DPUTS("root page doesn't need rebalancing");
|
|
|
- return MDB_SUCCESS;
|
|
|
- }
|
|
|
-
|
|
|
- /* The parent (branch page) must have at least 2 pointers,
|
|
|
- * otherwise the tree is invalid.
|
|
|
- */
|
|
|
- ptop = mc->mc_top-1;
|
|
|
- mdb_cassert(mc, NUMKEYS(mc->mc_pg[ptop]) > 1);
|
|
|
-
|
|
|
- /* Leaf page fill factor is below the threshold.
|
|
|
- * Try to move keys from left or right neighbor, or
|
|
|
- * merge with a neighbor page.
|
|
|
- */
|
|
|
-
|
|
|
- /* Find neighbors.
|
|
|
- */
|
|
|
- mdb_cursor_copy(mc, &mn);
|
|
|
- mn.mc_xcursor = NULL;
|
|
|
-
|
|
|
- oldki = mc->mc_ki[mc->mc_top];
|
|
|
- if (mc->mc_ki[ptop] == 0) {
|
|
|
- /* We're the leftmost leaf in our parent.
|
|
|
- */
|
|
|
- DPUTS("reading right neighbor");
|
|
|
- mn.mc_ki[ptop]++;
|
|
|
- node = NODEPTR(mc->mc_pg[ptop], mn.mc_ki[ptop]);
|
|
|
- rc = mdb_page_get(mc, NODEPGNO(node), &mn.mc_pg[mn.mc_top], NULL);
|
|
|
- if (rc)
|
|
|
- return rc;
|
|
|
- mn.mc_ki[mn.mc_top] = 0;
|
|
|
- mc->mc_ki[mc->mc_top] = NUMKEYS(mc->mc_pg[mc->mc_top]);
|
|
|
- fromleft = 0;
|
|
|
- } else {
|
|
|
- /* There is at least one neighbor to the left.
|
|
|
- */
|
|
|
- DPUTS("reading left neighbor");
|
|
|
- mn.mc_ki[ptop]--;
|
|
|
- node = NODEPTR(mc->mc_pg[ptop], mn.mc_ki[ptop]);
|
|
|
- rc = mdb_page_get(mc, NODEPGNO(node), &mn.mc_pg[mn.mc_top], NULL);
|
|
|
- if (rc)
|
|
|
- return rc;
|
|
|
- mn.mc_ki[mn.mc_top] = NUMKEYS(mn.mc_pg[mn.mc_top]) - 1;
|
|
|
- mc->mc_ki[mc->mc_top] = 0;
|
|
|
- fromleft = 1;
|
|
|
- }
|
|
|
-
|
|
|
- DPRINTF(("found neighbor page %"Z"u (%u keys, %.1f%% full)",
|
|
|
- mn.mc_pg[mn.mc_top]->mp_pgno, NUMKEYS(mn.mc_pg[mn.mc_top]),
|
|
|
- (float)PAGEFILL(mc->mc_txn->mt_env, mn.mc_pg[mn.mc_top]) / 10));
|
|
|
-
|
|
|
- /* If the neighbor page is above threshold and has enough keys,
|
|
|
- * move one key from it. Otherwise we should try to merge them.
|
|
|
- * (A branch page must never have less than 2 keys.)
|
|
|
- */
|
|
|
- if (PAGEFILL(mc->mc_txn->mt_env, mn.mc_pg[mn.mc_top]) >= thresh && NUMKEYS(mn.mc_pg[mn.mc_top]) > minkeys) {
|
|
|
- rc = mdb_node_move(&mn, mc, fromleft);
|
|
|
- if (fromleft) {
|
|
|
- /* if we inserted on left, bump position up */
|
|
|
- oldki++;
|
|
|
- }
|
|
|
- } else {
|
|
|
- if (!fromleft) {
|
|
|
- rc = mdb_page_merge(&mn, mc);
|
|
|
- } else {
|
|
|
- oldki += NUMKEYS(mn.mc_pg[mn.mc_top]);
|
|
|
- mn.mc_ki[mn.mc_top] += mc->mc_ki[mn.mc_top] + 1;
|
|
|
- /* We want mdb_rebalance to find mn when doing fixups */
|
|
|
- WITH_CURSOR_TRACKING(mn,
|
|
|
- rc = mdb_page_merge(mc, &mn));
|
|
|
- mdb_cursor_copy(&mn, mc);
|
|
|
- }
|
|
|
- mc->mc_flags &= ~C_EOF;
|
|
|
- }
|
|
|
- mc->mc_ki[mc->mc_top] = oldki;
|
|
|
- return rc;
|
|
|
-}
|
|
|
-
|
|
|
-/** Complete a delete operation started by #mdb_cursor_del(). */
|
|
|
-static int
|
|
|
-mdb_cursor_del0(MDB_cursor *mc)
|
|
|
-{
|
|
|
- int rc;
|
|
|
- MDB_page *mp;
|
|
|
- indx_t ki;
|
|
|
- unsigned int nkeys;
|
|
|
- MDB_cursor *m2, *m3;
|
|
|
- MDB_dbi dbi = mc->mc_dbi;
|
|
|
-
|
|
|
- ki = mc->mc_ki[mc->mc_top];
|
|
|
- mp = mc->mc_pg[mc->mc_top];
|
|
|
- mdb_node_del(mc, mc->mc_db->md_pad);
|
|
|
- mc->mc_db->md_entries--;
|
|
|
- {
|
|
|
- /* Adjust other cursors pointing to mp */
|
|
|
- for (m2 = mc->mc_txn->mt_cursors[dbi]; m2; m2=m2->mc_next) {
|
|
|
- m3 = (mc->mc_flags & C_SUB) ? &m2->mc_xcursor->mx_cursor : m2;
|
|
|
- if (! (m2->mc_flags & m3->mc_flags & C_INITIALIZED))
|
|
|
- continue;
|
|
|
- if (m3 == mc || m3->mc_snum < mc->mc_snum)
|
|
|
- continue;
|
|
|
- if (m3->mc_pg[mc->mc_top] == mp) {
|
|
|
- if (m3->mc_ki[mc->mc_top] == ki) {
|
|
|
- m3->mc_flags |= C_DEL;
|
|
|
- if (mc->mc_db->md_flags & MDB_DUPSORT) {
|
|
|
- /* Sub-cursor referred into dataset which is gone */
|
|
|
- m3->mc_xcursor->mx_cursor.mc_flags &= ~(C_INITIALIZED|C_EOF);
|
|
|
- }
|
|
|
- continue;
|
|
|
- } else if (m3->mc_ki[mc->mc_top] > ki) {
|
|
|
- m3->mc_ki[mc->mc_top]--;
|
|
|
- }
|
|
|
- XCURSOR_REFRESH(m3, mc->mc_top, mp);
|
|
|
- }
|
|
|
- }
|
|
|
- }
|
|
|
- rc = mdb_rebalance(mc);
|
|
|
-
|
|
|
- if (rc == MDB_SUCCESS) {
|
|
|
- /* DB is totally empty now, just bail out.
|
|
|
- * Other cursors adjustments were already done
|
|
|
- * by mdb_rebalance and aren't needed here.
|
|
|
- */
|
|
|
- if (!mc->mc_snum)
|
|
|
- return rc;
|
|
|
-
|
|
|
- mp = mc->mc_pg[mc->mc_top];
|
|
|
- nkeys = NUMKEYS(mp);
|
|
|
-
|
|
|
- /* Adjust other cursors pointing to mp */
|
|
|
- for (m2 = mc->mc_txn->mt_cursors[dbi]; !rc && m2; m2=m2->mc_next) {
|
|
|
- m3 = (mc->mc_flags & C_SUB) ? &m2->mc_xcursor->mx_cursor : m2;
|
|
|
- if (! (m2->mc_flags & m3->mc_flags & C_INITIALIZED))
|
|
|
- continue;
|
|
|
- if (m3->mc_snum < mc->mc_snum)
|
|
|
- continue;
|
|
|
- if (m3->mc_pg[mc->mc_top] == mp) {
|
|
|
- /* if m3 points past last node in page, find next sibling */
|
|
|
- if (m3->mc_ki[mc->mc_top] >= mc->mc_ki[mc->mc_top]) {
|
|
|
- if (m3->mc_ki[mc->mc_top] >= nkeys) {
|
|
|
- rc = mdb_cursor_sibling(m3, 1);
|
|
|
- if (rc == MDB_NOTFOUND) {
|
|
|
- m3->mc_flags |= C_EOF;
|
|
|
- rc = MDB_SUCCESS;
|
|
|
- continue;
|
|
|
- }
|
|
|
- }
|
|
|
- if (mc->mc_db->md_flags & MDB_DUPSORT) {
|
|
|
- MDB_node *node = NODEPTR(m3->mc_pg[m3->mc_top], m3->mc_ki[m3->mc_top]);
|
|
|
- /* If this node has dupdata, it may need to be reinited
|
|
|
- * because its data has moved.
|
|
|
- * If the xcursor was not initd it must be reinited.
|
|
|
- * Else if node points to a subDB, nothing is needed.
|
|
|
- * Else (xcursor was initd, not a subDB) needs mc_pg[0] reset.
|
|
|
- */
|
|
|
- if (node->mn_flags & F_DUPDATA) {
|
|
|
- if (m3->mc_xcursor->mx_cursor.mc_flags & C_INITIALIZED) {
|
|
|
- if (!(node->mn_flags & F_SUBDATA))
|
|
|
- m3->mc_xcursor->mx_cursor.mc_pg[0] = NODEDATA(node);
|
|
|
- } else {
|
|
|
- mdb_xcursor_init1(m3, node);
|
|
|
- m3->mc_xcursor->mx_cursor.mc_flags |= C_DEL;
|
|
|
- }
|
|
|
- }
|
|
|
- }
|
|
|
- }
|
|
|
- }
|
|
|
- }
|
|
|
- mc->mc_flags |= C_DEL;
|
|
|
- }
|
|
|
-
|
|
|
- if (rc)
|
|
|
- mc->mc_txn->mt_flags |= MDB_TXN_ERROR;
|
|
|
- return rc;
|
|
|
-}
|
|
|
-
|
|
|
-int
|
|
|
-mdb_del(MDB_txn *txn, MDB_dbi dbi,
|
|
|
- MDB_val *key, MDB_val *data)
|
|
|
-{
|
|
|
- if (!key || !TXN_DBI_EXIST(txn, dbi, DB_USRVALID))
|
|
|
- return EINVAL;
|
|
|
-
|
|
|
- if (txn->mt_flags & (MDB_TXN_RDONLY|MDB_TXN_BLOCKED))
|
|
|
- return (txn->mt_flags & MDB_TXN_RDONLY) ? EACCES : MDB_BAD_TXN;
|
|
|
-
|
|
|
- if (!F_ISSET(txn->mt_dbs[dbi].md_flags, MDB_DUPSORT)) {
|
|
|
- /* must ignore any data */
|
|
|
- data = NULL;
|
|
|
- }
|
|
|
-
|
|
|
- return mdb_del0(txn, dbi, key, data, 0);
|
|
|
-}
|
|
|
-
|
|
|
-static int
|
|
|
-mdb_del0(MDB_txn *txn, MDB_dbi dbi,
|
|
|
- MDB_val *key, MDB_val *data, unsigned flags)
|
|
|
-{
|
|
|
- MDB_cursor mc;
|
|
|
- MDB_xcursor mx;
|
|
|
- MDB_cursor_op op;
|
|
|
- MDB_val rdata, *xdata;
|
|
|
- int rc, exact = 0;
|
|
|
- DKBUF;
|
|
|
-
|
|
|
- DPRINTF(("====> delete db %u key [%s]", dbi, DKEY(key)));
|
|
|
-
|
|
|
- mdb_cursor_init(&mc, txn, dbi, &mx);
|
|
|
-
|
|
|
- if (data) {
|
|
|
- op = MDB_GET_BOTH;
|
|
|
- rdata = *data;
|
|
|
- xdata = &rdata;
|
|
|
- } else {
|
|
|
- op = MDB_SET;
|
|
|
- xdata = NULL;
|
|
|
- flags |= MDB_NODUPDATA;
|
|
|
- }
|
|
|
- rc = mdb_cursor_set(&mc, key, xdata, op, &exact);
|
|
|
- if (rc == 0) {
|
|
|
- /* let mdb_page_split know about this cursor if needed:
|
|
|
- * delete will trigger a rebalance; if it needs to move
|
|
|
- * a node from one page to another, it will have to
|
|
|
- * update the parent's separator key(s). If the new sepkey
|
|
|
- * is larger than the current one, the parent page may
|
|
|
- * run out of space, triggering a split. We need this
|
|
|
- * cursor to be consistent until the end of the rebalance.
|
|
|
- */
|
|
|
- mc.mc_flags |= C_UNTRACK;
|
|
|
- mc.mc_next = txn->mt_cursors[dbi];
|
|
|
- txn->mt_cursors[dbi] = &mc;
|
|
|
- rc = mdb_cursor_del(&mc, flags);
|
|
|
- txn->mt_cursors[dbi] = mc.mc_next;
|
|
|
- }
|
|
|
- return rc;
|
|
|
-}
|
|
|
-
|
|
|
-/** Split a page and insert a new node.
|
|
|
- * Set #MDB_TXN_ERROR on failure.
|
|
|
- * @param[in,out] mc Cursor pointing to the page and desired insertion index.
|
|
|
- * The cursor will be updated to point to the actual page and index where
|
|
|
- * the node got inserted after the split.
|
|
|
- * @param[in] newkey The key for the newly inserted node.
|
|
|
- * @param[in] newdata The data for the newly inserted node.
|
|
|
- * @param[in] newpgno The page number, if the new node is a branch node.
|
|
|
- * @param[in] nflags The #NODE_ADD_FLAGS for the new node.
|
|
|
- * @return 0 on success, non-zero on failure.
|
|
|
- */
|
|
|
-static int
|
|
|
-mdb_page_split(MDB_cursor *mc, MDB_val *newkey, MDB_val *newdata, pgno_t newpgno,
|
|
|
- unsigned int nflags)
|
|
|
-{
|
|
|
- unsigned int flags;
|
|
|
- int rc = MDB_SUCCESS, new_root = 0, did_split = 0;
|
|
|
- indx_t newindx;
|
|
|
- pgno_t pgno = 0;
|
|
|
- int i, j, split_indx, nkeys, pmax;
|
|
|
- MDB_env *env = mc->mc_txn->mt_env;
|
|
|
- MDB_node *node;
|
|
|
- MDB_val sepkey, rkey, xdata, *rdata = &xdata;
|
|
|
- MDB_page *copy = NULL;
|
|
|
- MDB_page *mp, *rp, *pp;
|
|
|
- int ptop;
|
|
|
- MDB_cursor mn;
|
|
|
- DKBUF;
|
|
|
-
|
|
|
- mp = mc->mc_pg[mc->mc_top];
|
|
|
- newindx = mc->mc_ki[mc->mc_top];
|
|
|
- nkeys = NUMKEYS(mp);
|
|
|
-
|
|
|
- DPRINTF(("-----> splitting %s page %"Z"u and adding [%s] at index %i/%i",
|
|
|
- IS_LEAF(mp) ? "leaf" : "branch", mp->mp_pgno,
|
|
|
- DKEY(newkey), mc->mc_ki[mc->mc_top], nkeys));
|
|
|
-
|
|
|
- /* Create a right sibling. */
|
|
|
- if ((rc = mdb_page_new(mc, mp->mp_flags, 1, &rp)))
|
|
|
- return rc;
|
|
|
- rp->mp_pad = mp->mp_pad;
|
|
|
- DPRINTF(("new right sibling: page %"Z"u", rp->mp_pgno));
|
|
|
-
|
|
|
- /* Usually when splitting the root page, the cursor
|
|
|
- * height is 1. But when called from mdb_update_key,
|
|
|
- * the cursor height may be greater because it walks
|
|
|
- * up the stack while finding the branch slot to update.
|
|
|
- */
|
|
|
- if (mc->mc_top < 1) {
|
|
|
- if ((rc = mdb_page_new(mc, P_BRANCH, 1, &pp)))
|
|
|
- goto done;
|
|
|
- /* shift current top to make room for new parent */
|
|
|
- for (i=mc->mc_snum; i>0; i--) {
|
|
|
- mc->mc_pg[i] = mc->mc_pg[i-1];
|
|
|
- mc->mc_ki[i] = mc->mc_ki[i-1];
|
|
|
- }
|
|
|
- mc->mc_pg[0] = pp;
|
|
|
- mc->mc_ki[0] = 0;
|
|
|
- mc->mc_db->md_root = pp->mp_pgno;
|
|
|
- DPRINTF(("root split! new root = %"Z"u", pp->mp_pgno));
|
|
|
- new_root = mc->mc_db->md_depth++;
|
|
|
-
|
|
|
- /* Add left (implicit) pointer. */
|
|
|
- if ((rc = mdb_node_add(mc, 0, NULL, NULL, mp->mp_pgno, 0)) != MDB_SUCCESS) {
|
|
|
- /* undo the pre-push */
|
|
|
- mc->mc_pg[0] = mc->mc_pg[1];
|
|
|
- mc->mc_ki[0] = mc->mc_ki[1];
|
|
|
- mc->mc_db->md_root = mp->mp_pgno;
|
|
|
- mc->mc_db->md_depth--;
|
|
|
- goto done;
|
|
|
- }
|
|
|
- mc->mc_snum++;
|
|
|
- mc->mc_top++;
|
|
|
- ptop = 0;
|
|
|
- } else {
|
|
|
- ptop = mc->mc_top-1;
|
|
|
- DPRINTF(("parent branch page is %"Z"u", mc->mc_pg[ptop]->mp_pgno));
|
|
|
- }
|
|
|
-
|
|
|
- mdb_cursor_copy(mc, &mn);
|
|
|
- mn.mc_xcursor = NULL;
|
|
|
- mn.mc_pg[mn.mc_top] = rp;
|
|
|
- mn.mc_ki[ptop] = mc->mc_ki[ptop]+1;
|
|
|
-
|
|
|
- if (nflags & MDB_APPEND) {
|
|
|
- mn.mc_ki[mn.mc_top] = 0;
|
|
|
- sepkey = *newkey;
|
|
|
- split_indx = newindx;
|
|
|
- nkeys = 0;
|
|
|
- } else {
|
|
|
-
|
|
|
- split_indx = (nkeys+1) / 2;
|
|
|
-
|
|
|
- if (IS_LEAF2(rp)) {
|
|
|
- char *split, *ins;
|
|
|
- int x;
|
|
|
- unsigned int lsize, rsize, ksize;
|
|
|
- /* Move half of the keys to the right sibling */
|
|
|
- x = mc->mc_ki[mc->mc_top] - split_indx;
|
|
|
- ksize = mc->mc_db->md_pad;
|
|
|
- split = LEAF2KEY(mp, split_indx, ksize);
|
|
|
- rsize = (nkeys - split_indx) * ksize;
|
|
|
- lsize = (nkeys - split_indx) * sizeof(indx_t);
|
|
|
- mp->mp_lower -= lsize;
|
|
|
- rp->mp_lower += lsize;
|
|
|
- mp->mp_upper += rsize - lsize;
|
|
|
- rp->mp_upper -= rsize - lsize;
|
|
|
- sepkey.mv_size = ksize;
|
|
|
- if (newindx == split_indx) {
|
|
|
- sepkey.mv_data = newkey->mv_data;
|
|
|
- } else {
|
|
|
- sepkey.mv_data = split;
|
|
|
- }
|
|
|
- if (x<0) {
|
|
|
- ins = LEAF2KEY(mp, mc->mc_ki[mc->mc_top], ksize);
|
|
|
- memcpy(rp->mp_ptrs, split, rsize);
|
|
|
- sepkey.mv_data = rp->mp_ptrs;
|
|
|
- memmove(ins+ksize, ins, (split_indx - mc->mc_ki[mc->mc_top]) * ksize);
|
|
|
- memcpy(ins, newkey->mv_data, ksize);
|
|
|
- mp->mp_lower += sizeof(indx_t);
|
|
|
- mp->mp_upper -= ksize - sizeof(indx_t);
|
|
|
- } else {
|
|
|
- if (x)
|
|
|
- memcpy(rp->mp_ptrs, split, x * ksize);
|
|
|
- ins = LEAF2KEY(rp, x, ksize);
|
|
|
- memcpy(ins, newkey->mv_data, ksize);
|
|
|
- memcpy(ins+ksize, split + x * ksize, rsize - x * ksize);
|
|
|
- rp->mp_lower += sizeof(indx_t);
|
|
|
- rp->mp_upper -= ksize - sizeof(indx_t);
|
|
|
- mc->mc_ki[mc->mc_top] = x;
|
|
|
- }
|
|
|
- } else {
|
|
|
- int psize, nsize, k;
|
|
|
- /* Maximum free space in an empty page */
|
|
|
- pmax = env->me_psize - PAGEHDRSZ;
|
|
|
- if (IS_LEAF(mp))
|
|
|
- nsize = mdb_leaf_size(env, newkey, newdata);
|
|
|
- else
|
|
|
- nsize = mdb_branch_size(env, newkey);
|
|
|
- nsize = EVEN(nsize);
|
|
|
-
|
|
|
- /* grab a page to hold a temporary copy */
|
|
|
- copy = mdb_page_malloc(mc->mc_txn, 1);
|
|
|
- if (copy == NULL) {
|
|
|
- rc = ENOMEM;
|
|
|
- goto done;
|
|
|
- }
|
|
|
- copy->mp_pgno = mp->mp_pgno;
|
|
|
- copy->mp_flags = mp->mp_flags;
|
|
|
- copy->mp_lower = (PAGEHDRSZ-PAGEBASE);
|
|
|
- copy->mp_upper = env->me_psize - PAGEBASE;
|
|
|
-
|
|
|
- /* prepare to insert */
|
|
|
- for (i=0, j=0; i<nkeys; i++) {
|
|
|
- if (i == newindx) {
|
|
|
- copy->mp_ptrs[j++] = 0;
|
|
|
- }
|
|
|
- copy->mp_ptrs[j++] = mp->mp_ptrs[i];
|
|
|
- }
|
|
|
-
|
|
|
- /* When items are relatively large the split point needs
|
|
|
- * to be checked, because being off-by-one will make the
|
|
|
- * difference between success or failure in mdb_node_add.
|
|
|
- *
|
|
|
- * It's also relevant if a page happens to be laid out
|
|
|
- * such that one half of its nodes are all "small" and
|
|
|
- * the other half of its nodes are "large." If the new
|
|
|
- * item is also "large" and falls on the half with
|
|
|
- * "large" nodes, it also may not fit.
|
|
|
- *
|
|
|
- * As a final tweak, if the new item goes on the last
|
|
|
- * spot on the page (and thus, onto the new page), bias
|
|
|
- * the split so the new page is emptier than the old page.
|
|
|
- * This yields better packing during sequential inserts.
|
|
|
- */
|
|
|
- if (nkeys < 20 || nsize > pmax/16 || newindx >= nkeys) {
|
|
|
- /* Find split point */
|
|
|
- psize = 0;
|
|
|
- if (newindx <= split_indx || newindx >= nkeys) {
|
|
|
- i = 0; j = 1;
|
|
|
- k = newindx >= nkeys ? nkeys : split_indx+1+IS_LEAF(mp);
|
|
|
- } else {
|
|
|
- i = nkeys; j = -1;
|
|
|
- k = split_indx-1;
|
|
|
- }
|
|
|
- for (; i!=k; i+=j) {
|
|
|
- if (i == newindx) {
|
|
|
- psize += nsize;
|
|
|
- node = NULL;
|
|
|
- } else {
|
|
|
- node = (MDB_node *)((char *)mp + copy->mp_ptrs[i] + PAGEBASE);
|
|
|
- psize += NODESIZE + NODEKSZ(node) + sizeof(indx_t);
|
|
|
- if (IS_LEAF(mp)) {
|
|
|
- if (F_ISSET(node->mn_flags, F_BIGDATA))
|
|
|
- psize += sizeof(pgno_t);
|
|
|
- else
|
|
|
- psize += NODEDSZ(node);
|
|
|
- }
|
|
|
- psize = EVEN(psize);
|
|
|
- }
|
|
|
- if (psize > pmax || i == k-j) {
|
|
|
- split_indx = i + (j<0);
|
|
|
- break;
|
|
|
- }
|
|
|
- }
|
|
|
- }
|
|
|
- if (split_indx == newindx) {
|
|
|
- sepkey.mv_size = newkey->mv_size;
|
|
|
- sepkey.mv_data = newkey->mv_data;
|
|
|
- } else {
|
|
|
- node = (MDB_node *)((char *)mp + copy->mp_ptrs[split_indx] + PAGEBASE);
|
|
|
- sepkey.mv_size = node->mn_ksize;
|
|
|
- sepkey.mv_data = NODEKEY(node);
|
|
|
- }
|
|
|
- }
|
|
|
- }
|
|
|
-
|
|
|
- DPRINTF(("separator is %d [%s]", split_indx, DKEY(&sepkey)));
|
|
|
-
|
|
|
- /* Copy separator key to the parent.
|
|
|
- */
|
|
|
- if (SIZELEFT(mn.mc_pg[ptop]) < mdb_branch_size(env, &sepkey)) {
|
|
|
- int snum = mc->mc_snum;
|
|
|
- mn.mc_snum--;
|
|
|
- mn.mc_top--;
|
|
|
- did_split = 1;
|
|
|
- /* We want other splits to find mn when doing fixups */
|
|
|
- WITH_CURSOR_TRACKING(mn,
|
|
|
- rc = mdb_page_split(&mn, &sepkey, NULL, rp->mp_pgno, 0));
|
|
|
- if (rc)
|
|
|
- goto done;
|
|
|
-
|
|
|
- /* root split? */
|
|
|
- if (mc->mc_snum > snum) {
|
|
|
- ptop++;
|
|
|
- }
|
|
|
- /* Right page might now have changed parent.
|
|
|
- * Check if left page also changed parent.
|
|
|
- */
|
|
|
- if (mn.mc_pg[ptop] != mc->mc_pg[ptop] &&
|
|
|
- mc->mc_ki[ptop] >= NUMKEYS(mc->mc_pg[ptop])) {
|
|
|
- for (i=0; i<ptop; i++) {
|
|
|
- mc->mc_pg[i] = mn.mc_pg[i];
|
|
|
- mc->mc_ki[i] = mn.mc_ki[i];
|
|
|
- }
|
|
|
- mc->mc_pg[ptop] = mn.mc_pg[ptop];
|
|
|
- if (mn.mc_ki[ptop]) {
|
|
|
- mc->mc_ki[ptop] = mn.mc_ki[ptop] - 1;
|
|
|
- } else {
|
|
|
- /* find right page's left sibling */
|
|
|
- mc->mc_ki[ptop] = mn.mc_ki[ptop];
|
|
|
- mdb_cursor_sibling(mc, 0);
|
|
|
- }
|
|
|
- }
|
|
|
- } else {
|
|
|
- mn.mc_top--;
|
|
|
- rc = mdb_node_add(&mn, mn.mc_ki[ptop], &sepkey, NULL, rp->mp_pgno, 0);
|
|
|
- mn.mc_top++;
|
|
|
- }
|
|
|
- if (rc != MDB_SUCCESS) {
|
|
|
- goto done;
|
|
|
- }
|
|
|
- if (nflags & MDB_APPEND) {
|
|
|
- mc->mc_pg[mc->mc_top] = rp;
|
|
|
- mc->mc_ki[mc->mc_top] = 0;
|
|
|
- rc = mdb_node_add(mc, 0, newkey, newdata, newpgno, nflags);
|
|
|
- if (rc)
|
|
|
- goto done;
|
|
|
- for (i=0; i<mc->mc_top; i++)
|
|
|
- mc->mc_ki[i] = mn.mc_ki[i];
|
|
|
- } else if (!IS_LEAF2(mp)) {
|
|
|
- /* Move nodes */
|
|
|
- mc->mc_pg[mc->mc_top] = rp;
|
|
|
- i = split_indx;
|
|
|
- j = 0;
|
|
|
- do {
|
|
|
- if (i == newindx) {
|
|
|
- rkey.mv_data = newkey->mv_data;
|
|
|
- rkey.mv_size = newkey->mv_size;
|
|
|
- if (IS_LEAF(mp)) {
|
|
|
- rdata = newdata;
|
|
|
- } else
|
|
|
- pgno = newpgno;
|
|
|
- flags = nflags;
|
|
|
- /* Update index for the new key. */
|
|
|
- mc->mc_ki[mc->mc_top] = j;
|
|
|
- } else {
|
|
|
- node = (MDB_node *)((char *)mp + copy->mp_ptrs[i] + PAGEBASE);
|
|
|
- rkey.mv_data = NODEKEY(node);
|
|
|
- rkey.mv_size = node->mn_ksize;
|
|
|
- if (IS_LEAF(mp)) {
|
|
|
- xdata.mv_data = NODEDATA(node);
|
|
|
- xdata.mv_size = NODEDSZ(node);
|
|
|
- rdata = &xdata;
|
|
|
- } else
|
|
|
- pgno = NODEPGNO(node);
|
|
|
- flags = node->mn_flags;
|
|
|
- }
|
|
|
-
|
|
|
- if (!IS_LEAF(mp) && j == 0) {
|
|
|
- /* First branch index doesn't need key data. */
|
|
|
- rkey.mv_size = 0;
|
|
|
- }
|
|
|
-
|
|
|
- rc = mdb_node_add(mc, j, &rkey, rdata, pgno, flags);
|
|
|
- if (rc)
|
|
|
- goto done;
|
|
|
- if (i == nkeys) {
|
|
|
- i = 0;
|
|
|
- j = 0;
|
|
|
- mc->mc_pg[mc->mc_top] = copy;
|
|
|
- } else {
|
|
|
- i++;
|
|
|
- j++;
|
|
|
- }
|
|
|
- } while (i != split_indx);
|
|
|
-
|
|
|
- nkeys = NUMKEYS(copy);
|
|
|
- for (i=0; i<nkeys; i++)
|
|
|
- mp->mp_ptrs[i] = copy->mp_ptrs[i];
|
|
|
- mp->mp_lower = copy->mp_lower;
|
|
|
- mp->mp_upper = copy->mp_upper;
|
|
|
- memcpy(NODEPTR(mp, nkeys-1), NODEPTR(copy, nkeys-1),
|
|
|
- env->me_psize - copy->mp_upper - PAGEBASE);
|
|
|
-
|
|
|
- /* reset back to original page */
|
|
|
- if (newindx < split_indx) {
|
|
|
- mc->mc_pg[mc->mc_top] = mp;
|
|
|
- } else {
|
|
|
- mc->mc_pg[mc->mc_top] = rp;
|
|
|
- mc->mc_ki[ptop]++;
|
|
|
- /* Make sure mc_ki is still valid.
|
|
|
- */
|
|
|
- if (mn.mc_pg[ptop] != mc->mc_pg[ptop] &&
|
|
|
- mc->mc_ki[ptop] >= NUMKEYS(mc->mc_pg[ptop])) {
|
|
|
- for (i=0; i<=ptop; i++) {
|
|
|
- mc->mc_pg[i] = mn.mc_pg[i];
|
|
|
- mc->mc_ki[i] = mn.mc_ki[i];
|
|
|
- }
|
|
|
- }
|
|
|
- }
|
|
|
- if (nflags & MDB_RESERVE) {
|
|
|
- node = NODEPTR(mc->mc_pg[mc->mc_top], mc->mc_ki[mc->mc_top]);
|
|
|
- if (!(node->mn_flags & F_BIGDATA))
|
|
|
- newdata->mv_data = NODEDATA(node);
|
|
|
- }
|
|
|
- } else {
|
|
|
- if (newindx >= split_indx) {
|
|
|
- mc->mc_pg[mc->mc_top] = rp;
|
|
|
- mc->mc_ki[ptop]++;
|
|
|
- /* Make sure mc_ki is still valid.
|
|
|
- */
|
|
|
- if (mn.mc_pg[ptop] != mc->mc_pg[ptop] &&
|
|
|
- mc->mc_ki[ptop] >= NUMKEYS(mc->mc_pg[ptop])) {
|
|
|
- for (i=0; i<=ptop; i++) {
|
|
|
- mc->mc_pg[i] = mn.mc_pg[i];
|
|
|
- mc->mc_ki[i] = mn.mc_ki[i];
|
|
|
- }
|
|
|
- }
|
|
|
- }
|
|
|
- }
|
|
|
-
|
|
|
- {
|
|
|
- /* Adjust other cursors pointing to mp */
|
|
|
- MDB_cursor *m2, *m3;
|
|
|
- MDB_dbi dbi = mc->mc_dbi;
|
|
|
- nkeys = NUMKEYS(mp);
|
|
|
-
|
|
|
- for (m2 = mc->mc_txn->mt_cursors[dbi]; m2; m2=m2->mc_next) {
|
|
|
- if (mc->mc_flags & C_SUB)
|
|
|
- m3 = &m2->mc_xcursor->mx_cursor;
|
|
|
- else
|
|
|
- m3 = m2;
|
|
|
- if (m3 == mc)
|
|
|
- continue;
|
|
|
- if (!(m2->mc_flags & m3->mc_flags & C_INITIALIZED))
|
|
|
- continue;
|
|
|
- if (new_root) {
|
|
|
- int k;
|
|
|
- /* sub cursors may be on different DB */
|
|
|
- if (m3->mc_pg[0] != mp)
|
|
|
- continue;
|
|
|
- /* root split */
|
|
|
- for (k=new_root; k>=0; k--) {
|
|
|
- m3->mc_ki[k+1] = m3->mc_ki[k];
|
|
|
- m3->mc_pg[k+1] = m3->mc_pg[k];
|
|
|
- }
|
|
|
- if (m3->mc_ki[0] >= nkeys) {
|
|
|
- m3->mc_ki[0] = 1;
|
|
|
- } else {
|
|
|
- m3->mc_ki[0] = 0;
|
|
|
- }
|
|
|
- m3->mc_pg[0] = mc->mc_pg[0];
|
|
|
- m3->mc_snum++;
|
|
|
- m3->mc_top++;
|
|
|
- }
|
|
|
- if (m3->mc_top >= mc->mc_top && m3->mc_pg[mc->mc_top] == mp) {
|
|
|
- if (m3->mc_ki[mc->mc_top] >= newindx && !(nflags & MDB_SPLIT_REPLACE))
|
|
|
- m3->mc_ki[mc->mc_top]++;
|
|
|
- if (m3->mc_ki[mc->mc_top] >= nkeys) {
|
|
|
- m3->mc_pg[mc->mc_top] = rp;
|
|
|
- m3->mc_ki[mc->mc_top] -= nkeys;
|
|
|
- for (i=0; i<mc->mc_top; i++) {
|
|
|
- m3->mc_ki[i] = mn.mc_ki[i];
|
|
|
- m3->mc_pg[i] = mn.mc_pg[i];
|
|
|
- }
|
|
|
- }
|
|
|
- } else if (!did_split && m3->mc_top >= ptop && m3->mc_pg[ptop] == mc->mc_pg[ptop] &&
|
|
|
- m3->mc_ki[ptop] >= mc->mc_ki[ptop]) {
|
|
|
- m3->mc_ki[ptop]++;
|
|
|
- }
|
|
|
- if (IS_LEAF(mp))
|
|
|
- XCURSOR_REFRESH(m3, mc->mc_top, m3->mc_pg[mc->mc_top]);
|
|
|
- }
|
|
|
- }
|
|
|
- DPRINTF(("mp left: %d, rp left: %d", SIZELEFT(mp), SIZELEFT(rp)));
|
|
|
-
|
|
|
-done:
|
|
|
- if (copy) /* tmp page */
|
|
|
- mdb_page_free(env, copy);
|
|
|
- if (rc)
|
|
|
- mc->mc_txn->mt_flags |= MDB_TXN_ERROR;
|
|
|
- return rc;
|
|
|
-}
|
|
|
-
|
|
|
-int
|
|
|
-mdb_put(MDB_txn *txn, MDB_dbi dbi,
|
|
|
- MDB_val *key, MDB_val *data, unsigned int flags)
|
|
|
-{
|
|
|
- MDB_cursor mc;
|
|
|
- MDB_xcursor mx;
|
|
|
- int rc;
|
|
|
-
|
|
|
- if (!key || !data || !TXN_DBI_EXIST(txn, dbi, DB_USRVALID))
|
|
|
- return EINVAL;
|
|
|
-
|
|
|
- if (flags & ~(MDB_NOOVERWRITE|MDB_NODUPDATA|MDB_RESERVE|MDB_APPEND|MDB_APPENDDUP))
|
|
|
- return EINVAL;
|
|
|
-
|
|
|
- if (txn->mt_flags & (MDB_TXN_RDONLY|MDB_TXN_BLOCKED))
|
|
|
- return (txn->mt_flags & MDB_TXN_RDONLY) ? EACCES : MDB_BAD_TXN;
|
|
|
-
|
|
|
- mdb_cursor_init(&mc, txn, dbi, &mx);
|
|
|
- mc.mc_next = txn->mt_cursors[dbi];
|
|
|
- txn->mt_cursors[dbi] = &mc;
|
|
|
- rc = mdb_cursor_put(&mc, key, data, flags);
|
|
|
- txn->mt_cursors[dbi] = mc.mc_next;
|
|
|
- return rc;
|
|
|
-}
|
|
|
-
|
|
|
-#ifndef MDB_WBUF
|
|
|
-#define MDB_WBUF (1024*1024)
|
|
|
-#endif
|
|
|
-#define MDB_EOF 0x10 /**< #mdb_env_copyfd1() is done reading */
|
|
|
-
|
|
|
- /** State needed for a double-buffering compacting copy. */
|
|
|
-typedef struct mdb_copy {
|
|
|
- MDB_env *mc_env;
|
|
|
- MDB_txn *mc_txn;
|
|
|
- pthread_mutex_t mc_mutex;
|
|
|
- pthread_cond_t mc_cond; /**< Condition variable for #mc_new */
|
|
|
- char *mc_wbuf[2];
|
|
|
- char *mc_over[2];
|
|
|
- int mc_wlen[2];
|
|
|
- int mc_olen[2];
|
|
|
- pgno_t mc_next_pgno;
|
|
|
- HANDLE mc_fd;
|
|
|
- int mc_toggle; /**< Buffer number in provider */
|
|
|
- int mc_new; /**< (0-2 buffers to write) | (#MDB_EOF at end) */
|
|
|
- /** Error code. Never cleared if set. Both threads can set nonzero
|
|
|
- * to fail the copy. Not mutex-protected, LMDB expects atomic int.
|
|
|
- */
|
|
|
- volatile int mc_error;
|
|
|
-} mdb_copy;
|
|
|
-
|
|
|
- /** Dedicated writer thread for compacting copy. */
|
|
|
-static THREAD_RET ESECT CALL_CONV
|
|
|
-mdb_env_copythr(void *arg)
|
|
|
-{
|
|
|
- mdb_copy *my = arg;
|
|
|
- char *ptr;
|
|
|
- int toggle = 0, wsize, rc;
|
|
|
-#ifdef _WIN32
|
|
|
- DWORD len;
|
|
|
-#define DO_WRITE(rc, fd, ptr, w2, len) rc = WriteFile(fd, ptr, w2, &len, NULL)
|
|
|
-#else
|
|
|
- int len;
|
|
|
-#define DO_WRITE(rc, fd, ptr, w2, len) len = write(fd, ptr, w2); rc = (len >= 0)
|
|
|
-#ifdef SIGPIPE
|
|
|
- sigset_t set;
|
|
|
- sigemptyset(&set);
|
|
|
- sigaddset(&set, SIGPIPE);
|
|
|
- if ((rc = pthread_sigmask(SIG_BLOCK, &set, NULL)) != 0)
|
|
|
- my->mc_error = rc;
|
|
|
-#endif
|
|
|
-#endif
|
|
|
-
|
|
|
- pthread_mutex_lock(&my->mc_mutex);
|
|
|
- for(;;) {
|
|
|
- while (!my->mc_new)
|
|
|
- pthread_cond_wait(&my->mc_cond, &my->mc_mutex);
|
|
|
- if (my->mc_new == 0 + MDB_EOF) /* 0 buffers, just EOF */
|
|
|
- break;
|
|
|
- wsize = my->mc_wlen[toggle];
|
|
|
- ptr = my->mc_wbuf[toggle];
|
|
|
-again:
|
|
|
- rc = MDB_SUCCESS;
|
|
|
- while (wsize > 0 && !my->mc_error) {
|
|
|
- DO_WRITE(rc, my->mc_fd, ptr, wsize, len);
|
|
|
- if (!rc) {
|
|
|
- rc = ErrCode();
|
|
|
-#if defined(SIGPIPE) && !defined(_WIN32)
|
|
|
- if (rc == EPIPE) {
|
|
|
- /* Collect the pending SIGPIPE, otherwise at least OS X
|
|
|
- * gives it to the process on thread-exit (ITS#8504).
|
|
|
- */
|
|
|
- int tmp;
|
|
|
- sigwait(&set, &tmp);
|
|
|
- }
|
|
|
-#endif
|
|
|
- break;
|
|
|
- } else if (len > 0) {
|
|
|
- rc = MDB_SUCCESS;
|
|
|
- ptr += len;
|
|
|
- wsize -= len;
|
|
|
- continue;
|
|
|
- } else {
|
|
|
- rc = EIO;
|
|
|
- break;
|
|
|
- }
|
|
|
- }
|
|
|
- if (rc) {
|
|
|
- my->mc_error = rc;
|
|
|
- }
|
|
|
- /* If there's an overflow page tail, write it too */
|
|
|
- if (my->mc_olen[toggle]) {
|
|
|
- wsize = my->mc_olen[toggle];
|
|
|
- ptr = my->mc_over[toggle];
|
|
|
- my->mc_olen[toggle] = 0;
|
|
|
- goto again;
|
|
|
- }
|
|
|
- my->mc_wlen[toggle] = 0;
|
|
|
- toggle ^= 1;
|
|
|
- /* Return the empty buffer to provider */
|
|
|
- my->mc_new--;
|
|
|
- pthread_cond_signal(&my->mc_cond);
|
|
|
- }
|
|
|
- pthread_mutex_unlock(&my->mc_mutex);
|
|
|
- return (THREAD_RET)0;
|
|
|
-#undef DO_WRITE
|
|
|
-}
|
|
|
-
|
|
|
- /** Give buffer and/or #MDB_EOF to writer thread, await unused buffer.
|
|
|
- *
|
|
|
- * @param[in] my control structure.
|
|
|
- * @param[in] adjust (1 to hand off 1 buffer) | (MDB_EOF when ending).
|
|
|
- */
|
|
|
-static int ESECT
|
|
|
-mdb_env_cthr_toggle(mdb_copy *my, int adjust)
|
|
|
-{
|
|
|
- pthread_mutex_lock(&my->mc_mutex);
|
|
|
- my->mc_new += adjust;
|
|
|
- pthread_cond_signal(&my->mc_cond);
|
|
|
- while (my->mc_new & 2) /* both buffers in use */
|
|
|
- pthread_cond_wait(&my->mc_cond, &my->mc_mutex);
|
|
|
- pthread_mutex_unlock(&my->mc_mutex);
|
|
|
-
|
|
|
- my->mc_toggle ^= (adjust & 1);
|
|
|
- /* Both threads reset mc_wlen, to be safe from threading errors */
|
|
|
- my->mc_wlen[my->mc_toggle] = 0;
|
|
|
- return my->mc_error;
|
|
|
-}
|
|
|
-
|
|
|
- /** Depth-first tree traversal for compacting copy.
|
|
|
- * @param[in] my control structure.
|
|
|
- * @param[in,out] pg database root.
|
|
|
- * @param[in] flags includes #F_DUPDATA if it is a sorted-duplicate sub-DB.
|
|
|
- */
|
|
|
-static int ESECT
|
|
|
-mdb_env_cwalk(mdb_copy *my, pgno_t *pg, int flags)
|
|
|
-{
|
|
|
- MDB_cursor mc = {0};
|
|
|
- MDB_node *ni;
|
|
|
- MDB_page *mo, *mp, *leaf;
|
|
|
- char *buf, *ptr;
|
|
|
- int rc, toggle;
|
|
|
- unsigned int i;
|
|
|
-
|
|
|
- /* Empty DB, nothing to do */
|
|
|
- if (*pg == P_INVALID)
|
|
|
- return MDB_SUCCESS;
|
|
|
-
|
|
|
- mc.mc_snum = 1;
|
|
|
- mc.mc_txn = my->mc_txn;
|
|
|
-
|
|
|
- rc = mdb_page_get(&mc, *pg, &mc.mc_pg[0], NULL);
|
|
|
- if (rc)
|
|
|
- return rc;
|
|
|
- rc = mdb_page_search_root(&mc, NULL, MDB_PS_FIRST);
|
|
|
- if (rc)
|
|
|
- return rc;
|
|
|
-
|
|
|
- /* Make cursor pages writable */
|
|
|
- buf = ptr = malloc(my->mc_env->me_psize * mc.mc_snum);
|
|
|
- if (buf == NULL)
|
|
|
- return ENOMEM;
|
|
|
-
|
|
|
- for (i=0; i<mc.mc_top; i++) {
|
|
|
- mdb_page_copy((MDB_page *)ptr, mc.mc_pg[i], my->mc_env->me_psize);
|
|
|
- mc.mc_pg[i] = (MDB_page *)ptr;
|
|
|
- ptr += my->mc_env->me_psize;
|
|
|
- }
|
|
|
-
|
|
|
- /* This is writable space for a leaf page. Usually not needed. */
|
|
|
- leaf = (MDB_page *)ptr;
|
|
|
-
|
|
|
- toggle = my->mc_toggle;
|
|
|
- while (mc.mc_snum > 0) {
|
|
|
- unsigned n;
|
|
|
- mp = mc.mc_pg[mc.mc_top];
|
|
|
- n = NUMKEYS(mp);
|
|
|
-
|
|
|
- if (IS_LEAF(mp)) {
|
|
|
- if (!IS_LEAF2(mp) && !(flags & F_DUPDATA)) {
|
|
|
- for (i=0; i<n; i++) {
|
|
|
- ni = NODEPTR(mp, i);
|
|
|
- if (ni->mn_flags & F_BIGDATA) {
|
|
|
- MDB_page *omp;
|
|
|
- pgno_t pg;
|
|
|
-
|
|
|
- /* Need writable leaf */
|
|
|
- if (mp != leaf) {
|
|
|
- mc.mc_pg[mc.mc_top] = leaf;
|
|
|
- mdb_page_copy(leaf, mp, my->mc_env->me_psize);
|
|
|
- mp = leaf;
|
|
|
- ni = NODEPTR(mp, i);
|
|
|
- }
|
|
|
-
|
|
|
- memcpy(&pg, NODEDATA(ni), sizeof(pg));
|
|
|
- memcpy(NODEDATA(ni), &my->mc_next_pgno, sizeof(pgno_t));
|
|
|
- rc = mdb_page_get(&mc, pg, &omp, NULL);
|
|
|
- if (rc)
|
|
|
- goto done;
|
|
|
- if (my->mc_wlen[toggle] >= MDB_WBUF) {
|
|
|
- rc = mdb_env_cthr_toggle(my, 1);
|
|
|
- if (rc)
|
|
|
- goto done;
|
|
|
- toggle = my->mc_toggle;
|
|
|
- }
|
|
|
- mo = (MDB_page *)(my->mc_wbuf[toggle] + my->mc_wlen[toggle]);
|
|
|
- memcpy(mo, omp, my->mc_env->me_psize);
|
|
|
- mo->mp_pgno = my->mc_next_pgno;
|
|
|
- my->mc_next_pgno += omp->mp_pages;
|
|
|
- my->mc_wlen[toggle] += my->mc_env->me_psize;
|
|
|
- if (omp->mp_pages > 1) {
|
|
|
- my->mc_olen[toggle] = my->mc_env->me_psize * (omp->mp_pages - 1);
|
|
|
- my->mc_over[toggle] = (char *)omp + my->mc_env->me_psize;
|
|
|
- rc = mdb_env_cthr_toggle(my, 1);
|
|
|
- if (rc)
|
|
|
- goto done;
|
|
|
- toggle = my->mc_toggle;
|
|
|
- }
|
|
|
- } else if (ni->mn_flags & F_SUBDATA) {
|
|
|
- MDB_db db;
|
|
|
-
|
|
|
- /* Need writable leaf */
|
|
|
- if (mp != leaf) {
|
|
|
- mc.mc_pg[mc.mc_top] = leaf;
|
|
|
- mdb_page_copy(leaf, mp, my->mc_env->me_psize);
|
|
|
- mp = leaf;
|
|
|
- ni = NODEPTR(mp, i);
|
|
|
- }
|
|
|
-
|
|
|
- memcpy(&db, NODEDATA(ni), sizeof(db));
|
|
|
- my->mc_toggle = toggle;
|
|
|
- rc = mdb_env_cwalk(my, &db.md_root, ni->mn_flags & F_DUPDATA);
|
|
|
- if (rc)
|
|
|
- goto done;
|
|
|
- toggle = my->mc_toggle;
|
|
|
- memcpy(NODEDATA(ni), &db, sizeof(db));
|
|
|
- }
|
|
|
- }
|
|
|
- }
|
|
|
- } else {
|
|
|
- mc.mc_ki[mc.mc_top]++;
|
|
|
- if (mc.mc_ki[mc.mc_top] < n) {
|
|
|
- pgno_t pg;
|
|
|
-again:
|
|
|
- ni = NODEPTR(mp, mc.mc_ki[mc.mc_top]);
|
|
|
- pg = NODEPGNO(ni);
|
|
|
- rc = mdb_page_get(&mc, pg, &mp, NULL);
|
|
|
- if (rc)
|
|
|
- goto done;
|
|
|
- mc.mc_top++;
|
|
|
- mc.mc_snum++;
|
|
|
- mc.mc_ki[mc.mc_top] = 0;
|
|
|
- if (IS_BRANCH(mp)) {
|
|
|
- /* Whenever we advance to a sibling branch page,
|
|
|
- * we must proceed all the way down to its first leaf.
|
|
|
- */
|
|
|
- mdb_page_copy(mc.mc_pg[mc.mc_top], mp, my->mc_env->me_psize);
|
|
|
- goto again;
|
|
|
- } else
|
|
|
- mc.mc_pg[mc.mc_top] = mp;
|
|
|
- continue;
|
|
|
- }
|
|
|
- }
|
|
|
- if (my->mc_wlen[toggle] >= MDB_WBUF) {
|
|
|
- rc = mdb_env_cthr_toggle(my, 1);
|
|
|
- if (rc)
|
|
|
- goto done;
|
|
|
- toggle = my->mc_toggle;
|
|
|
- }
|
|
|
- mo = (MDB_page *)(my->mc_wbuf[toggle] + my->mc_wlen[toggle]);
|
|
|
- mdb_page_copy(mo, mp, my->mc_env->me_psize);
|
|
|
- mo->mp_pgno = my->mc_next_pgno++;
|
|
|
- my->mc_wlen[toggle] += my->mc_env->me_psize;
|
|
|
- if (mc.mc_top) {
|
|
|
- /* Update parent if there is one */
|
|
|
- ni = NODEPTR(mc.mc_pg[mc.mc_top-1], mc.mc_ki[mc.mc_top-1]);
|
|
|
- SETPGNO(ni, mo->mp_pgno);
|
|
|
- mdb_cursor_pop(&mc);
|
|
|
- } else {
|
|
|
- /* Otherwise we're done */
|
|
|
- *pg = mo->mp_pgno;
|
|
|
- break;
|
|
|
- }
|
|
|
- }
|
|
|
-done:
|
|
|
- free(buf);
|
|
|
- return rc;
|
|
|
-}
|
|
|
-
|
|
|
- /** Copy environment with compaction. */
|
|
|
-static int ESECT
|
|
|
-mdb_env_copyfd1(MDB_env *env, HANDLE fd)
|
|
|
-{
|
|
|
- MDB_meta *mm;
|
|
|
- MDB_page *mp;
|
|
|
- mdb_copy my = {0};
|
|
|
- MDB_txn *txn = NULL;
|
|
|
- pthread_t thr;
|
|
|
- pgno_t root, new_root;
|
|
|
- int rc = MDB_SUCCESS;
|
|
|
-
|
|
|
-#ifdef _WIN32
|
|
|
- if (!(my.mc_mutex = CreateMutex(NULL, FALSE, NULL)) ||
|
|
|
- !(my.mc_cond = CreateEvent(NULL, FALSE, FALSE, NULL))) {
|
|
|
- rc = ErrCode();
|
|
|
- goto done;
|
|
|
- }
|
|
|
- my.mc_wbuf[0] = _aligned_malloc(MDB_WBUF*2, env->me_os_psize);
|
|
|
- if (my.mc_wbuf[0] == NULL) {
|
|
|
- /* _aligned_malloc() sets errno, but we use Windows error codes */
|
|
|
- rc = ERROR_NOT_ENOUGH_MEMORY;
|
|
|
- goto done;
|
|
|
- }
|
|
|
-#else
|
|
|
- if ((rc = pthread_mutex_init(&my.mc_mutex, NULL)) != 0)
|
|
|
- return rc;
|
|
|
- if ((rc = pthread_cond_init(&my.mc_cond, NULL)) != 0)
|
|
|
- goto done2;
|
|
|
-#ifdef HAVE_MEMALIGN
|
|
|
- my.mc_wbuf[0] = memalign(env->me_os_psize, MDB_WBUF*2);
|
|
|
- if (my.mc_wbuf[0] == NULL) {
|
|
|
- rc = errno;
|
|
|
- goto done;
|
|
|
- }
|
|
|
-#else
|
|
|
- {
|
|
|
- void *p;
|
|
|
- if ((rc = posix_memalign(&p, env->me_os_psize, MDB_WBUF*2)) != 0)
|
|
|
- goto done;
|
|
|
- my.mc_wbuf[0] = p;
|
|
|
- }
|
|
|
-#endif
|
|
|
-#endif
|
|
|
- memset(my.mc_wbuf[0], 0, MDB_WBUF*2);
|
|
|
- my.mc_wbuf[1] = my.mc_wbuf[0] + MDB_WBUF;
|
|
|
- my.mc_next_pgno = NUM_METAS;
|
|
|
- my.mc_env = env;
|
|
|
- my.mc_fd = fd;
|
|
|
- rc = THREAD_CREATE(thr, mdb_env_copythr, &my);
|
|
|
- if (rc)
|
|
|
- goto done;
|
|
|
-
|
|
|
- rc = mdb_txn_begin(env, NULL, MDB_RDONLY, &txn);
|
|
|
- if (rc)
|
|
|
- goto finish;
|
|
|
-
|
|
|
- mp = (MDB_page *)my.mc_wbuf[0];
|
|
|
- memset(mp, 0, NUM_METAS * env->me_psize);
|
|
|
- mp->mp_pgno = 0;
|
|
|
- mp->mp_flags = P_META;
|
|
|
- mm = (MDB_meta *)METADATA(mp);
|
|
|
- mdb_env_init_meta0(env, mm);
|
|
|
- mm->mm_address = env->me_metas[0]->mm_address;
|
|
|
-
|
|
|
- mp = (MDB_page *)(my.mc_wbuf[0] + env->me_psize);
|
|
|
- mp->mp_pgno = 1;
|
|
|
- mp->mp_flags = P_META;
|
|
|
- *(MDB_meta *)METADATA(mp) = *mm;
|
|
|
- mm = (MDB_meta *)METADATA(mp);
|
|
|
-
|
|
|
- /* Set metapage 1 with current main DB */
|
|
|
- root = new_root = txn->mt_dbs[MAIN_DBI].md_root;
|
|
|
- if (root != P_INVALID) {
|
|
|
- /* Count free pages + freeDB pages. Subtract from last_pg
|
|
|
- * to find the new last_pg, which also becomes the new root.
|
|
|
- */
|
|
|
- MDB_ID freecount = 0;
|
|
|
- MDB_cursor mc;
|
|
|
- MDB_val key, data;
|
|
|
- mdb_cursor_init(&mc, txn, FREE_DBI, NULL);
|
|
|
- while ((rc = mdb_cursor_get(&mc, &key, &data, MDB_NEXT)) == 0)
|
|
|
- freecount += *(MDB_ID *)data.mv_data;
|
|
|
- if (rc != MDB_NOTFOUND)
|
|
|
- goto finish;
|
|
|
- freecount += txn->mt_dbs[FREE_DBI].md_branch_pages +
|
|
|
- txn->mt_dbs[FREE_DBI].md_leaf_pages +
|
|
|
- txn->mt_dbs[FREE_DBI].md_overflow_pages;
|
|
|
-
|
|
|
- new_root = txn->mt_next_pgno - 1 - freecount;
|
|
|
- mm->mm_last_pg = new_root;
|
|
|
- mm->mm_dbs[MAIN_DBI] = txn->mt_dbs[MAIN_DBI];
|
|
|
- mm->mm_dbs[MAIN_DBI].md_root = new_root;
|
|
|
- } else {
|
|
|
- /* When the DB is empty, handle it specially to
|
|
|
- * fix any breakage like page leaks from ITS#8174.
|
|
|
- */
|
|
|
- mm->mm_dbs[MAIN_DBI].md_flags = txn->mt_dbs[MAIN_DBI].md_flags;
|
|
|
- }
|
|
|
- if (root != P_INVALID || mm->mm_dbs[MAIN_DBI].md_flags) {
|
|
|
- mm->mm_txnid = 1; /* use metapage 1 */
|
|
|
- }
|
|
|
-
|
|
|
- my.mc_wlen[0] = env->me_psize * NUM_METAS;
|
|
|
- my.mc_txn = txn;
|
|
|
- rc = mdb_env_cwalk(&my, &root, 0);
|
|
|
- if (rc == MDB_SUCCESS && root != new_root) {
|
|
|
- rc = MDB_INCOMPATIBLE; /* page leak or corrupt DB */
|
|
|
- }
|
|
|
-
|
|
|
-finish:
|
|
|
- if (rc)
|
|
|
- my.mc_error = rc;
|
|
|
- mdb_env_cthr_toggle(&my, 1 | MDB_EOF);
|
|
|
- rc = THREAD_FINISH(thr);
|
|
|
- mdb_txn_abort(txn);
|
|
|
-
|
|
|
-done:
|
|
|
-#ifdef _WIN32
|
|
|
- if (my.mc_wbuf[0]) _aligned_free(my.mc_wbuf[0]);
|
|
|
- if (my.mc_cond) CloseHandle(my.mc_cond);
|
|
|
- if (my.mc_mutex) CloseHandle(my.mc_mutex);
|
|
|
-#else
|
|
|
- free(my.mc_wbuf[0]);
|
|
|
- pthread_cond_destroy(&my.mc_cond);
|
|
|
-done2:
|
|
|
- pthread_mutex_destroy(&my.mc_mutex);
|
|
|
-#endif
|
|
|
- return rc ? rc : my.mc_error;
|
|
|
-}
|
|
|
-
|
|
|
- /** Copy environment as-is. */
|
|
|
-static int ESECT
|
|
|
-mdb_env_copyfd0(MDB_env *env, HANDLE fd)
|
|
|
-{
|
|
|
- MDB_txn *txn = NULL;
|
|
|
- mdb_mutexref_t wmutex = NULL;
|
|
|
- int rc;
|
|
|
- size_t wsize, w3;
|
|
|
- char *ptr;
|
|
|
-#ifdef _WIN32
|
|
|
- DWORD len, w2;
|
|
|
-#define DO_WRITE(rc, fd, ptr, w2, len) rc = WriteFile(fd, ptr, w2, &len, NULL)
|
|
|
-#else
|
|
|
- ssize_t len;
|
|
|
- size_t w2;
|
|
|
-#define DO_WRITE(rc, fd, ptr, w2, len) len = write(fd, ptr, w2); rc = (len >= 0)
|
|
|
-#endif
|
|
|
-
|
|
|
- /* Do the lock/unlock of the reader mutex before starting the
|
|
|
- * write txn. Otherwise other read txns could block writers.
|
|
|
- */
|
|
|
- rc = mdb_txn_begin(env, NULL, MDB_RDONLY, &txn);
|
|
|
- if (rc)
|
|
|
- return rc;
|
|
|
-
|
|
|
- if (env->me_txns) {
|
|
|
- /* We must start the actual read txn after blocking writers */
|
|
|
- mdb_txn_end(txn, MDB_END_RESET_TMP);
|
|
|
-
|
|
|
- /* Temporarily block writers until we snapshot the meta pages */
|
|
|
- wmutex = env->me_wmutex;
|
|
|
- if (LOCK_MUTEX(rc, env, wmutex))
|
|
|
- goto leave;
|
|
|
-
|
|
|
- rc = mdb_txn_renew0(txn);
|
|
|
- if (rc) {
|
|
|
- UNLOCK_MUTEX(wmutex);
|
|
|
- goto leave;
|
|
|
- }
|
|
|
- }
|
|
|
-
|
|
|
- wsize = env->me_psize * NUM_METAS;
|
|
|
- ptr = env->me_map;
|
|
|
- w2 = wsize;
|
|
|
- while (w2 > 0) {
|
|
|
- DO_WRITE(rc, fd, ptr, w2, len);
|
|
|
- if (!rc) {
|
|
|
- rc = ErrCode();
|
|
|
- break;
|
|
|
- } else if (len > 0) {
|
|
|
- rc = MDB_SUCCESS;
|
|
|
- ptr += len;
|
|
|
- w2 -= len;
|
|
|
- continue;
|
|
|
- } else {
|
|
|
- /* Non-blocking or async handles are not supported */
|
|
|
- rc = EIO;
|
|
|
- break;
|
|
|
- }
|
|
|
- }
|
|
|
- if (wmutex)
|
|
|
- UNLOCK_MUTEX(wmutex);
|
|
|
-
|
|
|
- if (rc)
|
|
|
- goto leave;
|
|
|
-
|
|
|
- w3 = txn->mt_next_pgno * env->me_psize;
|
|
|
- {
|
|
|
- size_t fsize = 0;
|
|
|
- if ((rc = mdb_fsize(env->me_fd, &fsize)))
|
|
|
- goto leave;
|
|
|
- if (w3 > fsize)
|
|
|
- w3 = fsize;
|
|
|
- }
|
|
|
- wsize = w3 - wsize;
|
|
|
- while (wsize > 0) {
|
|
|
- if (wsize > MAX_WRITE)
|
|
|
- w2 = MAX_WRITE;
|
|
|
- else
|
|
|
- w2 = wsize;
|
|
|
- DO_WRITE(rc, fd, ptr, w2, len);
|
|
|
- if (!rc) {
|
|
|
- rc = ErrCode();
|
|
|
- break;
|
|
|
- } else if (len > 0) {
|
|
|
- rc = MDB_SUCCESS;
|
|
|
- ptr += len;
|
|
|
- wsize -= len;
|
|
|
- continue;
|
|
|
- } else {
|
|
|
- rc = EIO;
|
|
|
- break;
|
|
|
- }
|
|
|
- }
|
|
|
-
|
|
|
-leave:
|
|
|
- mdb_txn_abort(txn);
|
|
|
- return rc;
|
|
|
-}
|
|
|
-
|
|
|
-int ESECT
|
|
|
-mdb_env_copyfd2(MDB_env *env, HANDLE fd, unsigned int flags)
|
|
|
-{
|
|
|
- if (flags & MDB_CP_COMPACT)
|
|
|
- return mdb_env_copyfd1(env, fd);
|
|
|
- else
|
|
|
- return mdb_env_copyfd0(env, fd);
|
|
|
-}
|
|
|
-
|
|
|
-int ESECT
|
|
|
-mdb_env_copyfd(MDB_env *env, HANDLE fd)
|
|
|
-{
|
|
|
- return mdb_env_copyfd2(env, fd, 0);
|
|
|
-}
|
|
|
-
|
|
|
-int ESECT
|
|
|
-mdb_env_copy2(MDB_env *env, const char *path, unsigned int flags)
|
|
|
-{
|
|
|
- int rc;
|
|
|
- MDB_name fname;
|
|
|
- HANDLE newfd = INVALID_HANDLE_VALUE;
|
|
|
-
|
|
|
- rc = mdb_fname_init(path, env->me_flags | MDB_NOLOCK, &fname);
|
|
|
- if (rc == MDB_SUCCESS) {
|
|
|
- rc = mdb_fopen(env, &fname, MDB_O_COPY, 0666, &newfd);
|
|
|
- mdb_fname_destroy(fname);
|
|
|
- }
|
|
|
- if (rc == MDB_SUCCESS) {
|
|
|
- rc = mdb_env_copyfd2(env, newfd, flags);
|
|
|
- if (close(newfd) < 0 && rc == MDB_SUCCESS)
|
|
|
- rc = ErrCode();
|
|
|
- }
|
|
|
- return rc;
|
|
|
-}
|
|
|
-
|
|
|
-int ESECT
|
|
|
-mdb_env_copy(MDB_env *env, const char *path)
|
|
|
-{
|
|
|
- return mdb_env_copy2(env, path, 0);
|
|
|
-}
|
|
|
-
|
|
|
-int ESECT
|
|
|
-mdb_env_set_flags(MDB_env *env, unsigned int flag, int onoff)
|
|
|
-{
|
|
|
- if (flag & ~CHANGEABLE)
|
|
|
- return EINVAL;
|
|
|
- if (onoff)
|
|
|
- env->me_flags |= flag;
|
|
|
- else
|
|
|
- env->me_flags &= ~flag;
|
|
|
- return MDB_SUCCESS;
|
|
|
-}
|
|
|
-
|
|
|
-int ESECT
|
|
|
-mdb_env_get_flags(MDB_env *env, unsigned int *arg)
|
|
|
-{
|
|
|
- if (!env || !arg)
|
|
|
- return EINVAL;
|
|
|
-
|
|
|
- *arg = env->me_flags & (CHANGEABLE|CHANGELESS);
|
|
|
- return MDB_SUCCESS;
|
|
|
-}
|
|
|
-
|
|
|
-int ESECT
|
|
|
-mdb_env_set_userctx(MDB_env *env, void *ctx)
|
|
|
-{
|
|
|
- if (!env)
|
|
|
- return EINVAL;
|
|
|
- env->me_userctx = ctx;
|
|
|
- return MDB_SUCCESS;
|
|
|
-}
|
|
|
-
|
|
|
-void * ESECT
|
|
|
-mdb_env_get_userctx(MDB_env *env)
|
|
|
-{
|
|
|
- return env ? env->me_userctx : NULL;
|
|
|
-}
|
|
|
-
|
|
|
-int ESECT
|
|
|
-mdb_env_set_assert(MDB_env *env, MDB_assert_func *func)
|
|
|
-{
|
|
|
- if (!env)
|
|
|
- return EINVAL;
|
|
|
-#ifndef NDEBUG
|
|
|
- env->me_assert_func = func;
|
|
|
-#endif
|
|
|
- return MDB_SUCCESS;
|
|
|
-}
|
|
|
-
|
|
|
-int ESECT
|
|
|
-mdb_env_get_path(MDB_env *env, const char **arg)
|
|
|
-{
|
|
|
- if (!env || !arg)
|
|
|
- return EINVAL;
|
|
|
-
|
|
|
- *arg = env->me_path;
|
|
|
- return MDB_SUCCESS;
|
|
|
-}
|
|
|
-
|
|
|
-int ESECT
|
|
|
-mdb_env_get_fd(MDB_env *env, mdb_filehandle_t *arg)
|
|
|
-{
|
|
|
- if (!env || !arg)
|
|
|
- return EINVAL;
|
|
|
-
|
|
|
- *arg = env->me_fd;
|
|
|
- return MDB_SUCCESS;
|
|
|
-}
|
|
|
-
|
|
|
-/** Common code for #mdb_stat() and #mdb_env_stat().
|
|
|
- * @param[in] env the environment to operate in.
|
|
|
- * @param[in] db the #MDB_db record containing the stats to return.
|
|
|
- * @param[out] arg the address of an #MDB_stat structure to receive the stats.
|
|
|
- * @return 0, this function always succeeds.
|
|
|
- */
|
|
|
-static int ESECT
|
|
|
-mdb_stat0(MDB_env *env, MDB_db *db, MDB_stat *arg)
|
|
|
-{
|
|
|
- arg->ms_psize = env->me_psize;
|
|
|
- arg->ms_depth = db->md_depth;
|
|
|
- arg->ms_branch_pages = db->md_branch_pages;
|
|
|
- arg->ms_leaf_pages = db->md_leaf_pages;
|
|
|
- arg->ms_overflow_pages = db->md_overflow_pages;
|
|
|
- arg->ms_entries = db->md_entries;
|
|
|
-
|
|
|
- return MDB_SUCCESS;
|
|
|
-}
|
|
|
-
|
|
|
-int ESECT
|
|
|
-mdb_env_stat(MDB_env *env, MDB_stat *arg)
|
|
|
-{
|
|
|
- MDB_meta *meta;
|
|
|
-
|
|
|
- if (env == NULL || arg == NULL)
|
|
|
- return EINVAL;
|
|
|
-
|
|
|
- meta = mdb_env_pick_meta(env);
|
|
|
-
|
|
|
- return mdb_stat0(env, &meta->mm_dbs[MAIN_DBI], arg);
|
|
|
-}
|
|
|
-
|
|
|
-int ESECT
|
|
|
-mdb_env_info(MDB_env *env, MDB_envinfo *arg)
|
|
|
-{
|
|
|
- MDB_meta *meta;
|
|
|
-
|
|
|
- if (env == NULL || arg == NULL)
|
|
|
- return EINVAL;
|
|
|
-
|
|
|
- meta = mdb_env_pick_meta(env);
|
|
|
- arg->me_mapaddr = meta->mm_address;
|
|
|
- arg->me_last_pgno = meta->mm_last_pg;
|
|
|
- arg->me_last_txnid = meta->mm_txnid;
|
|
|
-
|
|
|
- arg->me_mapsize = env->me_mapsize;
|
|
|
- arg->me_maxreaders = env->me_maxreaders;
|
|
|
- arg->me_numreaders = env->me_txns ? env->me_txns->mti_numreaders : 0;
|
|
|
- return MDB_SUCCESS;
|
|
|
-}
|
|
|
-
|
|
|
-/** Set the default comparison functions for a database.
|
|
|
- * Called immediately after a database is opened to set the defaults.
|
|
|
- * The user can then override them with #mdb_set_compare() or
|
|
|
- * #mdb_set_dupsort().
|
|
|
- * @param[in] txn A transaction handle returned by #mdb_txn_begin()
|
|
|
- * @param[in] dbi A database handle returned by #mdb_dbi_open()
|
|
|
- */
|
|
|
-static void
|
|
|
-mdb_default_cmp(MDB_txn *txn, MDB_dbi dbi)
|
|
|
-{
|
|
|
- uint16_t f = txn->mt_dbs[dbi].md_flags;
|
|
|
-
|
|
|
- txn->mt_dbxs[dbi].md_cmp =
|
|
|
- (f & MDB_REVERSEKEY) ? mdb_cmp_memnr :
|
|
|
- (f & MDB_INTEGERKEY) ? mdb_cmp_cint : mdb_cmp_memn;
|
|
|
-
|
|
|
- txn->mt_dbxs[dbi].md_dcmp =
|
|
|
- !(f & MDB_DUPSORT) ? 0 :
|
|
|
- ((f & MDB_INTEGERDUP)
|
|
|
- ? ((f & MDB_DUPFIXED) ? mdb_cmp_int : mdb_cmp_cint)
|
|
|
- : ((f & MDB_REVERSEDUP) ? mdb_cmp_memnr : mdb_cmp_memn));
|
|
|
-}
|
|
|
-
|
|
|
-int mdb_dbi_open(MDB_txn *txn, const char *name, unsigned int flags, MDB_dbi *dbi)
|
|
|
-{
|
|
|
- MDB_val key, data;
|
|
|
- MDB_dbi i;
|
|
|
- MDB_cursor mc;
|
|
|
- MDB_db dummy;
|
|
|
- int rc, dbflag, exact;
|
|
|
- unsigned int unused = 0, seq;
|
|
|
- char *namedup;
|
|
|
- size_t len;
|
|
|
-
|
|
|
- if (flags & ~VALID_FLAGS)
|
|
|
- return EINVAL;
|
|
|
- if (txn->mt_flags & MDB_TXN_BLOCKED)
|
|
|
- return MDB_BAD_TXN;
|
|
|
-
|
|
|
- /* main DB? */
|
|
|
- if (!name) {
|
|
|
- *dbi = MAIN_DBI;
|
|
|
- if (flags & PERSISTENT_FLAGS) {
|
|
|
- uint16_t f2 = flags & PERSISTENT_FLAGS;
|
|
|
- /* make sure flag changes get committed */
|
|
|
- if ((txn->mt_dbs[MAIN_DBI].md_flags | f2) != txn->mt_dbs[MAIN_DBI].md_flags) {
|
|
|
- txn->mt_dbs[MAIN_DBI].md_flags |= f2;
|
|
|
- txn->mt_flags |= MDB_TXN_DIRTY;
|
|
|
- }
|
|
|
- }
|
|
|
- mdb_default_cmp(txn, MAIN_DBI);
|
|
|
- return MDB_SUCCESS;
|
|
|
- }
|
|
|
-
|
|
|
- if (txn->mt_dbxs[MAIN_DBI].md_cmp == NULL) {
|
|
|
- mdb_default_cmp(txn, MAIN_DBI);
|
|
|
- }
|
|
|
-
|
|
|
- /* Is the DB already open? */
|
|
|
- len = strlen(name);
|
|
|
- for (i=CORE_DBS; i<txn->mt_numdbs; i++) {
|
|
|
- if (!txn->mt_dbxs[i].md_name.mv_size) {
|
|
|
- /* Remember this free slot */
|
|
|
- if (!unused) unused = i;
|
|
|
- continue;
|
|
|
- }
|
|
|
- if (len == txn->mt_dbxs[i].md_name.mv_size &&
|
|
|
- !strncmp(name, txn->mt_dbxs[i].md_name.mv_data, len)) {
|
|
|
- *dbi = i;
|
|
|
- return MDB_SUCCESS;
|
|
|
- }
|
|
|
- }
|
|
|
-
|
|
|
- /* If no free slot and max hit, fail */
|
|
|
- if (!unused && txn->mt_numdbs >= txn->mt_env->me_maxdbs)
|
|
|
- return MDB_DBS_FULL;
|
|
|
-
|
|
|
- /* Cannot mix named databases with some mainDB flags */
|
|
|
- if (txn->mt_dbs[MAIN_DBI].md_flags & (MDB_DUPSORT|MDB_INTEGERKEY))
|
|
|
- return (flags & MDB_CREATE) ? MDB_INCOMPATIBLE : MDB_NOTFOUND;
|
|
|
-
|
|
|
- /* Find the DB info */
|
|
|
- dbflag = DB_NEW|DB_VALID|DB_USRVALID;
|
|
|
- exact = 0;
|
|
|
- key.mv_size = len;
|
|
|
- key.mv_data = (void *)name;
|
|
|
- mdb_cursor_init(&mc, txn, MAIN_DBI, NULL);
|
|
|
- rc = mdb_cursor_set(&mc, &key, &data, MDB_SET, &exact);
|
|
|
- if (rc == MDB_SUCCESS) {
|
|
|
- /* make sure this is actually a DB */
|
|
|
- MDB_node *node = NODEPTR(mc.mc_pg[mc.mc_top], mc.mc_ki[mc.mc_top]);
|
|
|
- if ((node->mn_flags & (F_DUPDATA|F_SUBDATA)) != F_SUBDATA)
|
|
|
- return MDB_INCOMPATIBLE;
|
|
|
- } else {
|
|
|
- if (rc != MDB_NOTFOUND || !(flags & MDB_CREATE))
|
|
|
- return rc;
|
|
|
- if (F_ISSET(txn->mt_flags, MDB_TXN_RDONLY))
|
|
|
- return EACCES;
|
|
|
- }
|
|
|
-
|
|
|
- /* Done here so we cannot fail after creating a new DB */
|
|
|
- if ((namedup = strdup(name)) == NULL)
|
|
|
- return ENOMEM;
|
|
|
-
|
|
|
- if (rc) {
|
|
|
- /* MDB_NOTFOUND and MDB_CREATE: Create new DB */
|
|
|
- data.mv_size = sizeof(MDB_db);
|
|
|
- data.mv_data = &dummy;
|
|
|
- memset(&dummy, 0, sizeof(dummy));
|
|
|
- dummy.md_root = P_INVALID;
|
|
|
- dummy.md_flags = flags & PERSISTENT_FLAGS;
|
|
|
- WITH_CURSOR_TRACKING(mc,
|
|
|
- rc = mdb_cursor_put(&mc, &key, &data, F_SUBDATA));
|
|
|
- dbflag |= DB_DIRTY;
|
|
|
- }
|
|
|
-
|
|
|
- if (rc) {
|
|
|
- free(namedup);
|
|
|
- } else {
|
|
|
- /* Got info, register DBI in this txn */
|
|
|
- unsigned int slot = unused ? unused : txn->mt_numdbs;
|
|
|
- txn->mt_dbxs[slot].md_name.mv_data = namedup;
|
|
|
- txn->mt_dbxs[slot].md_name.mv_size = len;
|
|
|
- txn->mt_dbxs[slot].md_rel = NULL;
|
|
|
- txn->mt_dbflags[slot] = dbflag;
|
|
|
- /* txn-> and env-> are the same in read txns, use
|
|
|
- * tmp variable to avoid undefined assignment
|
|
|
- */
|
|
|
- seq = ++txn->mt_env->me_dbiseqs[slot];
|
|
|
- txn->mt_dbiseqs[slot] = seq;
|
|
|
-
|
|
|
- memcpy(&txn->mt_dbs[slot], data.mv_data, sizeof(MDB_db));
|
|
|
- *dbi = slot;
|
|
|
- mdb_default_cmp(txn, slot);
|
|
|
- if (!unused) {
|
|
|
- txn->mt_numdbs++;
|
|
|
- }
|
|
|
- }
|
|
|
-
|
|
|
- return rc;
|
|
|
-}
|
|
|
-
|
|
|
-int ESECT
|
|
|
-mdb_stat(MDB_txn *txn, MDB_dbi dbi, MDB_stat *arg)
|
|
|
-{
|
|
|
- if (!arg || !TXN_DBI_EXIST(txn, dbi, DB_VALID))
|
|
|
- return EINVAL;
|
|
|
-
|
|
|
- if (txn->mt_flags & MDB_TXN_BLOCKED)
|
|
|
- return MDB_BAD_TXN;
|
|
|
-
|
|
|
- if (txn->mt_dbflags[dbi] & DB_STALE) {
|
|
|
- MDB_cursor mc;
|
|
|
- MDB_xcursor mx;
|
|
|
- /* Stale, must read the DB's root. cursor_init does it for us. */
|
|
|
- mdb_cursor_init(&mc, txn, dbi, &mx);
|
|
|
- }
|
|
|
- return mdb_stat0(txn->mt_env, &txn->mt_dbs[dbi], arg);
|
|
|
-}
|
|
|
-
|
|
|
-void mdb_dbi_close(MDB_env *env, MDB_dbi dbi)
|
|
|
-{
|
|
|
- char *ptr;
|
|
|
- if (dbi < CORE_DBS || dbi >= env->me_maxdbs)
|
|
|
- return;
|
|
|
- ptr = env->me_dbxs[dbi].md_name.mv_data;
|
|
|
- /* If there was no name, this was already closed */
|
|
|
- if (ptr) {
|
|
|
- env->me_dbxs[dbi].md_name.mv_data = NULL;
|
|
|
- env->me_dbxs[dbi].md_name.mv_size = 0;
|
|
|
- env->me_dbflags[dbi] = 0;
|
|
|
- env->me_dbiseqs[dbi]++;
|
|
|
- free(ptr);
|
|
|
- }
|
|
|
-}
|
|
|
-
|
|
|
-int mdb_dbi_flags(MDB_txn *txn, MDB_dbi dbi, unsigned int *flags)
|
|
|
-{
|
|
|
- /* We could return the flags for the FREE_DBI too but what's the point? */
|
|
|
- if (!TXN_DBI_EXIST(txn, dbi, DB_USRVALID))
|
|
|
- return EINVAL;
|
|
|
- *flags = txn->mt_dbs[dbi].md_flags & PERSISTENT_FLAGS;
|
|
|
- return MDB_SUCCESS;
|
|
|
-}
|
|
|
-
|
|
|
-/** Add all the DB's pages to the free list.
|
|
|
- * @param[in] mc Cursor on the DB to free.
|
|
|
- * @param[in] subs non-Zero to check for sub-DBs in this DB.
|
|
|
- * @return 0 on success, non-zero on failure.
|
|
|
- */
|
|
|
-static int
|
|
|
-mdb_drop0(MDB_cursor *mc, int subs)
|
|
|
-{
|
|
|
- int rc;
|
|
|
-
|
|
|
- rc = mdb_page_search(mc, NULL, MDB_PS_FIRST);
|
|
|
- if (rc == MDB_SUCCESS) {
|
|
|
- MDB_txn *txn = mc->mc_txn;
|
|
|
- MDB_node *ni;
|
|
|
- MDB_cursor mx;
|
|
|
- unsigned int i;
|
|
|
-
|
|
|
- /* DUPSORT sub-DBs have no ovpages/DBs. Omit scanning leaves.
|
|
|
- * This also avoids any P_LEAF2 pages, which have no nodes.
|
|
|
- * Also if the DB doesn't have sub-DBs and has no overflow
|
|
|
- * pages, omit scanning leaves.
|
|
|
- */
|
|
|
- if ((mc->mc_flags & C_SUB) ||
|
|
|
- (!subs && !mc->mc_db->md_overflow_pages))
|
|
|
- mdb_cursor_pop(mc);
|
|
|
-
|
|
|
- mdb_cursor_copy(mc, &mx);
|
|
|
- while (mc->mc_snum > 0) {
|
|
|
- MDB_page *mp = mc->mc_pg[mc->mc_top];
|
|
|
- unsigned n = NUMKEYS(mp);
|
|
|
- if (IS_LEAF(mp)) {
|
|
|
- for (i=0; i<n; i++) {
|
|
|
- ni = NODEPTR(mp, i);
|
|
|
- if (ni->mn_flags & F_BIGDATA) {
|
|
|
- MDB_page *omp;
|
|
|
- pgno_t pg;
|
|
|
- memcpy(&pg, NODEDATA(ni), sizeof(pg));
|
|
|
- rc = mdb_page_get(mc, pg, &omp, NULL);
|
|
|
- if (rc != 0)
|
|
|
- goto done;
|
|
|
- mdb_cassert(mc, IS_OVERFLOW(omp));
|
|
|
- rc = mdb_midl_append_range(&txn->mt_free_pgs,
|
|
|
- pg, omp->mp_pages);
|
|
|
- if (rc)
|
|
|
- goto done;
|
|
|
- mc->mc_db->md_overflow_pages -= omp->mp_pages;
|
|
|
- if (!mc->mc_db->md_overflow_pages && !subs)
|
|
|
- break;
|
|
|
- } else if (subs && (ni->mn_flags & F_SUBDATA)) {
|
|
|
- mdb_xcursor_init1(mc, ni);
|
|
|
- rc = mdb_drop0(&mc->mc_xcursor->mx_cursor, 0);
|
|
|
- if (rc)
|
|
|
- goto done;
|
|
|
- }
|
|
|
- }
|
|
|
- if (!subs && !mc->mc_db->md_overflow_pages)
|
|
|
- goto pop;
|
|
|
- } else {
|
|
|
- if ((rc = mdb_midl_need(&txn->mt_free_pgs, n)) != 0)
|
|
|
- goto done;
|
|
|
- for (i=0; i<n; i++) {
|
|
|
- pgno_t pg;
|
|
|
- ni = NODEPTR(mp, i);
|
|
|
- pg = NODEPGNO(ni);
|
|
|
- /* free it */
|
|
|
- mdb_midl_xappend(txn->mt_free_pgs, pg);
|
|
|
- }
|
|
|
- }
|
|
|
- if (!mc->mc_top)
|
|
|
- break;
|
|
|
- mc->mc_ki[mc->mc_top] = i;
|
|
|
- rc = mdb_cursor_sibling(mc, 1);
|
|
|
- if (rc) {
|
|
|
- if (rc != MDB_NOTFOUND)
|
|
|
- goto done;
|
|
|
- /* no more siblings, go back to beginning
|
|
|
- * of previous level.
|
|
|
- */
|
|
|
-pop:
|
|
|
- mdb_cursor_pop(mc);
|
|
|
- mc->mc_ki[0] = 0;
|
|
|
- for (i=1; i<mc->mc_snum; i++) {
|
|
|
- mc->mc_ki[i] = 0;
|
|
|
- mc->mc_pg[i] = mx.mc_pg[i];
|
|
|
- }
|
|
|
- }
|
|
|
- }
|
|
|
- /* free it */
|
|
|
- rc = mdb_midl_append(&txn->mt_free_pgs, mc->mc_db->md_root);
|
|
|
-done:
|
|
|
- if (rc)
|
|
|
- txn->mt_flags |= MDB_TXN_ERROR;
|
|
|
- } else if (rc == MDB_NOTFOUND) {
|
|
|
- rc = MDB_SUCCESS;
|
|
|
- }
|
|
|
- mc->mc_flags &= ~C_INITIALIZED;
|
|
|
- return rc;
|
|
|
-}
|
|
|
-
|
|
|
-int mdb_drop(MDB_txn *txn, MDB_dbi dbi, int del)
|
|
|
-{
|
|
|
- MDB_cursor *mc, *m2;
|
|
|
- int rc;
|
|
|
-
|
|
|
- if ((unsigned)del > 1 || !TXN_DBI_EXIST(txn, dbi, DB_USRVALID))
|
|
|
- return EINVAL;
|
|
|
-
|
|
|
- if (F_ISSET(txn->mt_flags, MDB_TXN_RDONLY))
|
|
|
- return EACCES;
|
|
|
-
|
|
|
- if (TXN_DBI_CHANGED(txn, dbi))
|
|
|
- return MDB_BAD_DBI;
|
|
|
-
|
|
|
- rc = mdb_cursor_open(txn, dbi, &mc);
|
|
|
- if (rc)
|
|
|
- return rc;
|
|
|
-
|
|
|
- rc = mdb_drop0(mc, mc->mc_db->md_flags & MDB_DUPSORT);
|
|
|
- /* Invalidate the dropped DB's cursors */
|
|
|
- for (m2 = txn->mt_cursors[dbi]; m2; m2 = m2->mc_next)
|
|
|
- m2->mc_flags &= ~(C_INITIALIZED|C_EOF);
|
|
|
- if (rc)
|
|
|
- goto leave;
|
|
|
-
|
|
|
- /* Can't delete the main DB */
|
|
|
- if (del && dbi >= CORE_DBS) {
|
|
|
- rc = mdb_del0(txn, MAIN_DBI, &mc->mc_dbx->md_name, NULL, F_SUBDATA);
|
|
|
- if (!rc) {
|
|
|
- txn->mt_dbflags[dbi] = DB_STALE;
|
|
|
- mdb_dbi_close(txn->mt_env, dbi);
|
|
|
- } else {
|
|
|
- txn->mt_flags |= MDB_TXN_ERROR;
|
|
|
- }
|
|
|
- } else {
|
|
|
- /* reset the DB record, mark it dirty */
|
|
|
- txn->mt_dbflags[dbi] |= DB_DIRTY;
|
|
|
- txn->mt_dbs[dbi].md_depth = 0;
|
|
|
- txn->mt_dbs[dbi].md_branch_pages = 0;
|
|
|
- txn->mt_dbs[dbi].md_leaf_pages = 0;
|
|
|
- txn->mt_dbs[dbi].md_overflow_pages = 0;
|
|
|
- txn->mt_dbs[dbi].md_entries = 0;
|
|
|
- txn->mt_dbs[dbi].md_root = P_INVALID;
|
|
|
-
|
|
|
- txn->mt_flags |= MDB_TXN_DIRTY;
|
|
|
- }
|
|
|
-leave:
|
|
|
- mdb_cursor_close(mc);
|
|
|
- return rc;
|
|
|
-}
|
|
|
-
|
|
|
-int mdb_set_compare(MDB_txn *txn, MDB_dbi dbi, MDB_cmp_func *cmp)
|
|
|
-{
|
|
|
- if (!TXN_DBI_EXIST(txn, dbi, DB_USRVALID))
|
|
|
- return EINVAL;
|
|
|
-
|
|
|
- txn->mt_dbxs[dbi].md_cmp = cmp;
|
|
|
- return MDB_SUCCESS;
|
|
|
-}
|
|
|
-
|
|
|
-int mdb_set_dupsort(MDB_txn *txn, MDB_dbi dbi, MDB_cmp_func *cmp)
|
|
|
-{
|
|
|
- if (!TXN_DBI_EXIST(txn, dbi, DB_USRVALID))
|
|
|
- return EINVAL;
|
|
|
-
|
|
|
- txn->mt_dbxs[dbi].md_dcmp = cmp;
|
|
|
- return MDB_SUCCESS;
|
|
|
-}
|
|
|
-
|
|
|
-int mdb_set_relfunc(MDB_txn *txn, MDB_dbi dbi, MDB_rel_func *rel)
|
|
|
-{
|
|
|
- if (!TXN_DBI_EXIST(txn, dbi, DB_USRVALID))
|
|
|
- return EINVAL;
|
|
|
-
|
|
|
- txn->mt_dbxs[dbi].md_rel = rel;
|
|
|
- return MDB_SUCCESS;
|
|
|
-}
|
|
|
-
|
|
|
-int mdb_set_relctx(MDB_txn *txn, MDB_dbi dbi, void *ctx)
|
|
|
-{
|
|
|
- if (!TXN_DBI_EXIST(txn, dbi, DB_USRVALID))
|
|
|
- return EINVAL;
|
|
|
-
|
|
|
- txn->mt_dbxs[dbi].md_relctx = ctx;
|
|
|
- return MDB_SUCCESS;
|
|
|
-}
|
|
|
-
|
|
|
-int ESECT
|
|
|
-mdb_env_get_maxkeysize(MDB_env *env)
|
|
|
-{
|
|
|
- return ENV_MAXKEY(env);
|
|
|
-}
|
|
|
-
|
|
|
-int ESECT
|
|
|
-mdb_reader_list(MDB_env *env, MDB_msg_func *func, void *ctx)
|
|
|
-{
|
|
|
- unsigned int i, rdrs;
|
|
|
- MDB_reader *mr;
|
|
|
- char buf[64];
|
|
|
- int rc = 0, first = 1;
|
|
|
-
|
|
|
- if (!env || !func)
|
|
|
- return -1;
|
|
|
- if (!env->me_txns) {
|
|
|
- return func("(no reader locks)\n", ctx);
|
|
|
- }
|
|
|
- rdrs = env->me_txns->mti_numreaders;
|
|
|
- mr = env->me_txns->mti_readers;
|
|
|
- for (i=0; i<rdrs; i++) {
|
|
|
- if (mr[i].mr_pid) {
|
|
|
- txnid_t txnid = mr[i].mr_txnid;
|
|
|
- sprintf(buf, txnid == (txnid_t)-1 ?
|
|
|
- "%10d %"Z"x -\n" : "%10d %"Z"x %"Z"u\n",
|
|
|
- (int)mr[i].mr_pid, (size_t)mr[i].mr_tid, txnid);
|
|
|
- if (first) {
|
|
|
- first = 0;
|
|
|
- rc = func(" pid thread txnid\n", ctx);
|
|
|
- if (rc < 0)
|
|
|
- break;
|
|
|
- }
|
|
|
- rc = func(buf, ctx);
|
|
|
- if (rc < 0)
|
|
|
- break;
|
|
|
- }
|
|
|
- }
|
|
|
- if (first) {
|
|
|
- rc = func("(no active readers)\n", ctx);
|
|
|
- }
|
|
|
- return rc;
|
|
|
-}
|
|
|
-
|
|
|
-/** Insert pid into list if not already present.
|
|
|
- * return -1 if already present.
|
|
|
- */
|
|
|
-static int ESECT
|
|
|
-mdb_pid_insert(MDB_PID_T *ids, MDB_PID_T pid)
|
|
|
-{
|
|
|
- /* binary search of pid in list */
|
|
|
- unsigned base = 0;
|
|
|
- unsigned cursor = 1;
|
|
|
- int val = 0;
|
|
|
- unsigned n = ids[0];
|
|
|
-
|
|
|
- while( 0 < n ) {
|
|
|
- unsigned pivot = n >> 1;
|
|
|
- cursor = base + pivot + 1;
|
|
|
- val = pid - ids[cursor];
|
|
|
-
|
|
|
- if( val < 0 ) {
|
|
|
- n = pivot;
|
|
|
-
|
|
|
- } else if ( val > 0 ) {
|
|
|
- base = cursor;
|
|
|
- n -= pivot + 1;
|
|
|
-
|
|
|
- } else {
|
|
|
- /* found, so it's a duplicate */
|
|
|
- return -1;
|
|
|
- }
|
|
|
- }
|
|
|
-
|
|
|
- if( val > 0 ) {
|
|
|
- ++cursor;
|
|
|
- }
|
|
|
- ids[0]++;
|
|
|
- for (n = ids[0]; n > cursor; n--)
|
|
|
- ids[n] = ids[n-1];
|
|
|
- ids[n] = pid;
|
|
|
- return 0;
|
|
|
-}
|
|
|
-
|
|
|
-int ESECT
|
|
|
-mdb_reader_check(MDB_env *env, int *dead)
|
|
|
-{
|
|
|
- if (!env)
|
|
|
- return EINVAL;
|
|
|
- if (dead)
|
|
|
- *dead = 0;
|
|
|
- return env->me_txns ? mdb_reader_check0(env, 0, dead) : MDB_SUCCESS;
|
|
|
-}
|
|
|
-
|
|
|
-/** As #mdb_reader_check(). \b rlocked is set if caller locked #me_rmutex. */
|
|
|
-static int ESECT
|
|
|
-mdb_reader_check0(MDB_env *env, int rlocked, int *dead)
|
|
|
-{
|
|
|
- mdb_mutexref_t rmutex = rlocked ? NULL : env->me_rmutex;
|
|
|
- unsigned int i, j, rdrs;
|
|
|
- MDB_reader *mr;
|
|
|
- MDB_PID_T *pids, pid;
|
|
|
- int rc = MDB_SUCCESS, count = 0;
|
|
|
-
|
|
|
- rdrs = env->me_txns->mti_numreaders;
|
|
|
- pids = malloc((rdrs+1) * sizeof(MDB_PID_T));
|
|
|
- if (!pids)
|
|
|
- return ENOMEM;
|
|
|
- pids[0] = 0;
|
|
|
- mr = env->me_txns->mti_readers;
|
|
|
- for (i=0; i<rdrs; i++) {
|
|
|
- pid = mr[i].mr_pid;
|
|
|
- if (pid && pid != env->me_pid) {
|
|
|
- if (mdb_pid_insert(pids, pid) == 0) {
|
|
|
- if (!mdb_reader_pid(env, Pidcheck, pid)) {
|
|
|
- /* Stale reader found */
|
|
|
- j = i;
|
|
|
- if (rmutex) {
|
|
|
- if ((rc = LOCK_MUTEX0(rmutex)) != 0) {
|
|
|
- if ((rc = mdb_mutex_failed(env, rmutex, rc)))
|
|
|
- break;
|
|
|
- rdrs = 0; /* the above checked all readers */
|
|
|
- } else {
|
|
|
- /* Recheck, a new process may have reused pid */
|
|
|
- if (mdb_reader_pid(env, Pidcheck, pid))
|
|
|
- j = rdrs;
|
|
|
- }
|
|
|
- }
|
|
|
- for (; j<rdrs; j++)
|
|
|
- if (mr[j].mr_pid == pid) {
|
|
|
- DPRINTF(("clear stale reader pid %u txn %"Z"d",
|
|
|
- (unsigned) pid, mr[j].mr_txnid));
|
|
|
- mr[j].mr_pid = 0;
|
|
|
- count++;
|
|
|
- }
|
|
|
- if (rmutex)
|
|
|
- UNLOCK_MUTEX(rmutex);
|
|
|
- }
|
|
|
- }
|
|
|
- }
|
|
|
- }
|
|
|
- free(pids);
|
|
|
- if (dead)
|
|
|
- *dead = count;
|
|
|
- return rc;
|
|
|
-}
|
|
|
-
|
|
|
-#ifdef MDB_ROBUST_SUPPORTED
|
|
|
-/** Handle #LOCK_MUTEX0() failure.
|
|
|
- * Try to repair the lock file if the mutex owner died.
|
|
|
- * @param[in] env the environment handle
|
|
|
- * @param[in] mutex LOCK_MUTEX0() mutex
|
|
|
- * @param[in] rc LOCK_MUTEX0() error (nonzero)
|
|
|
- * @return 0 on success with the mutex locked, or an error code on failure.
|
|
|
- */
|
|
|
-static int ESECT
|
|
|
-mdb_mutex_failed(MDB_env *env, mdb_mutexref_t mutex, int rc)
|
|
|
-{
|
|
|
- int rlocked, rc2;
|
|
|
- MDB_meta *meta;
|
|
|
-
|
|
|
- if (rc == MDB_OWNERDEAD) {
|
|
|
- /* We own the mutex. Clean up after dead previous owner. */
|
|
|
- rc = MDB_SUCCESS;
|
|
|
- rlocked = (mutex == env->me_rmutex);
|
|
|
- if (!rlocked) {
|
|
|
- /* Keep mti_txnid updated, otherwise next writer can
|
|
|
- * overwrite data which latest meta page refers to.
|
|
|
- */
|
|
|
- meta = mdb_env_pick_meta(env);
|
|
|
- env->me_txns->mti_txnid = meta->mm_txnid;
|
|
|
- /* env is hosed if the dead thread was ours */
|
|
|
- if (env->me_txn) {
|
|
|
- env->me_flags |= MDB_FATAL_ERROR;
|
|
|
- env->me_txn = NULL;
|
|
|
- rc = MDB_PANIC;
|
|
|
- }
|
|
|
- }
|
|
|
- DPRINTF(("%cmutex owner died, %s", (rlocked ? 'r' : 'w'),
|
|
|
- (rc ? "this process' env is hosed" : "recovering")));
|
|
|
- rc2 = mdb_reader_check0(env, rlocked, NULL);
|
|
|
- if (rc2 == 0)
|
|
|
- rc2 = mdb_mutex_consistent(mutex);
|
|
|
- if (rc || (rc = rc2)) {
|
|
|
- DPRINTF(("LOCK_MUTEX recovery failed, %s", mdb_strerror(rc)));
|
|
|
- UNLOCK_MUTEX(mutex);
|
|
|
- }
|
|
|
- } else {
|
|
|
-#ifdef _WIN32
|
|
|
- rc = ErrCode();
|
|
|
-#endif
|
|
|
- DPRINTF(("LOCK_MUTEX failed, %s", mdb_strerror(rc)));
|
|
|
- }
|
|
|
-
|
|
|
- return rc;
|
|
|
-}
|
|
|
-#endif /* MDB_ROBUST_SUPPORTED */
|
|
|
-
|
|
|
-#if defined(_WIN32)
|
|
|
-/** Convert \b src to new wchar_t[] string with room for \b xtra extra chars */
|
|
|
-static int ESECT
|
|
|
-utf8_to_utf16(const char *src, MDB_name *dst, int xtra)
|
|
|
-{
|
|
|
- int rc, need = 0;
|
|
|
- wchar_t *result = NULL;
|
|
|
- for (;;) { /* malloc result, then fill it in */
|
|
|
- need = MultiByteToWideChar(CP_UTF8, 0, src, -1, result, need);
|
|
|
- if (!need) {
|
|
|
- rc = ErrCode();
|
|
|
- free(result);
|
|
|
- return rc;
|
|
|
- }
|
|
|
- if (!result) {
|
|
|
- result = malloc(sizeof(wchar_t) * (need + xtra));
|
|
|
- if (!result)
|
|
|
- return ENOMEM;
|
|
|
- continue;
|
|
|
- }
|
|
|
- dst->mn_alloced = 1;
|
|
|
- dst->mn_len = need - 1;
|
|
|
- dst->mn_val = result;
|
|
|
- return MDB_SUCCESS;
|
|
|
- }
|
|
|
-}
|
|
|
-#endif /* defined(_WIN32) */
|
|
|
-/** @} */
|

 Stefano Cossu
Stefano Cossu
{kind=link}

{kind=link}
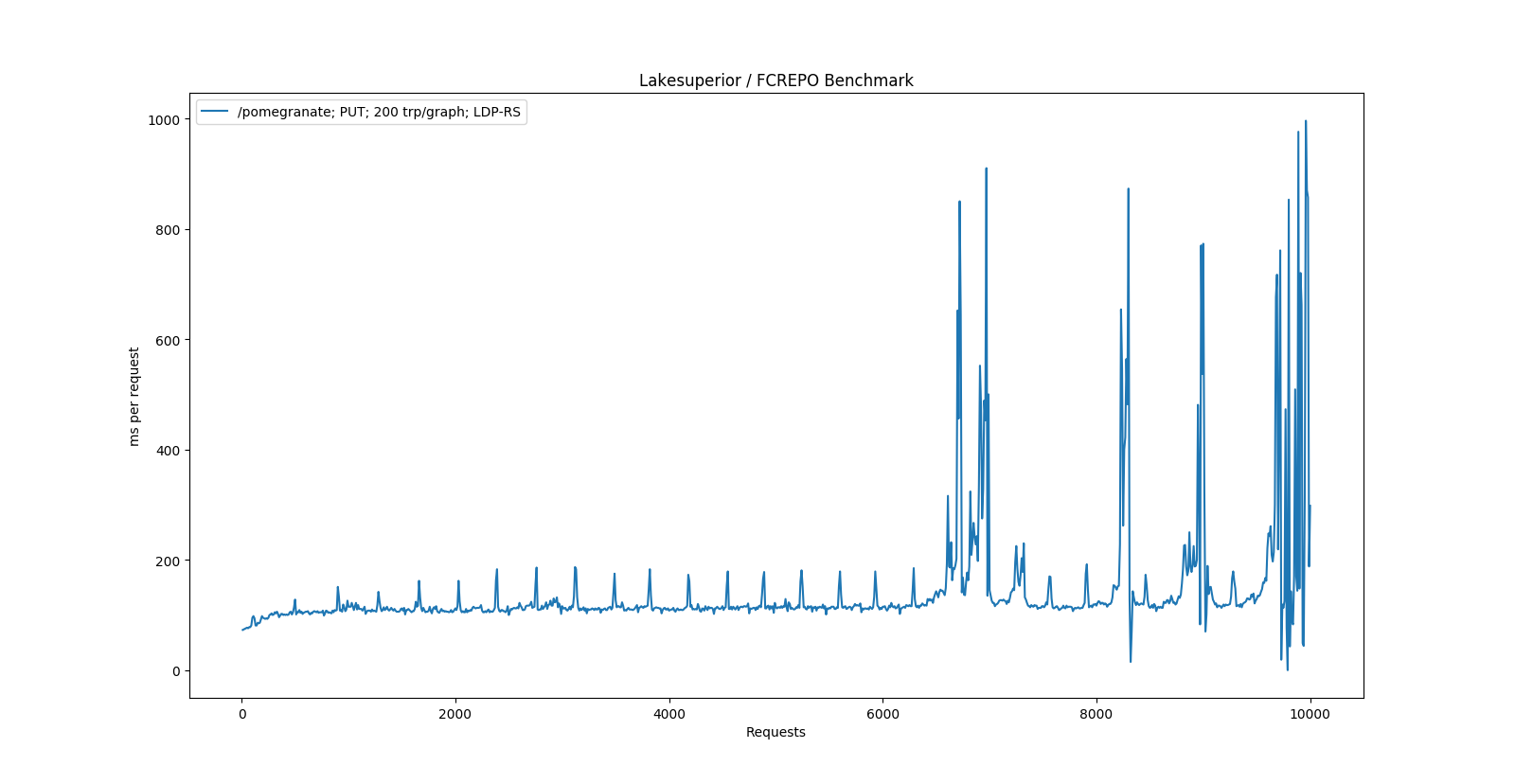
{kind=link}
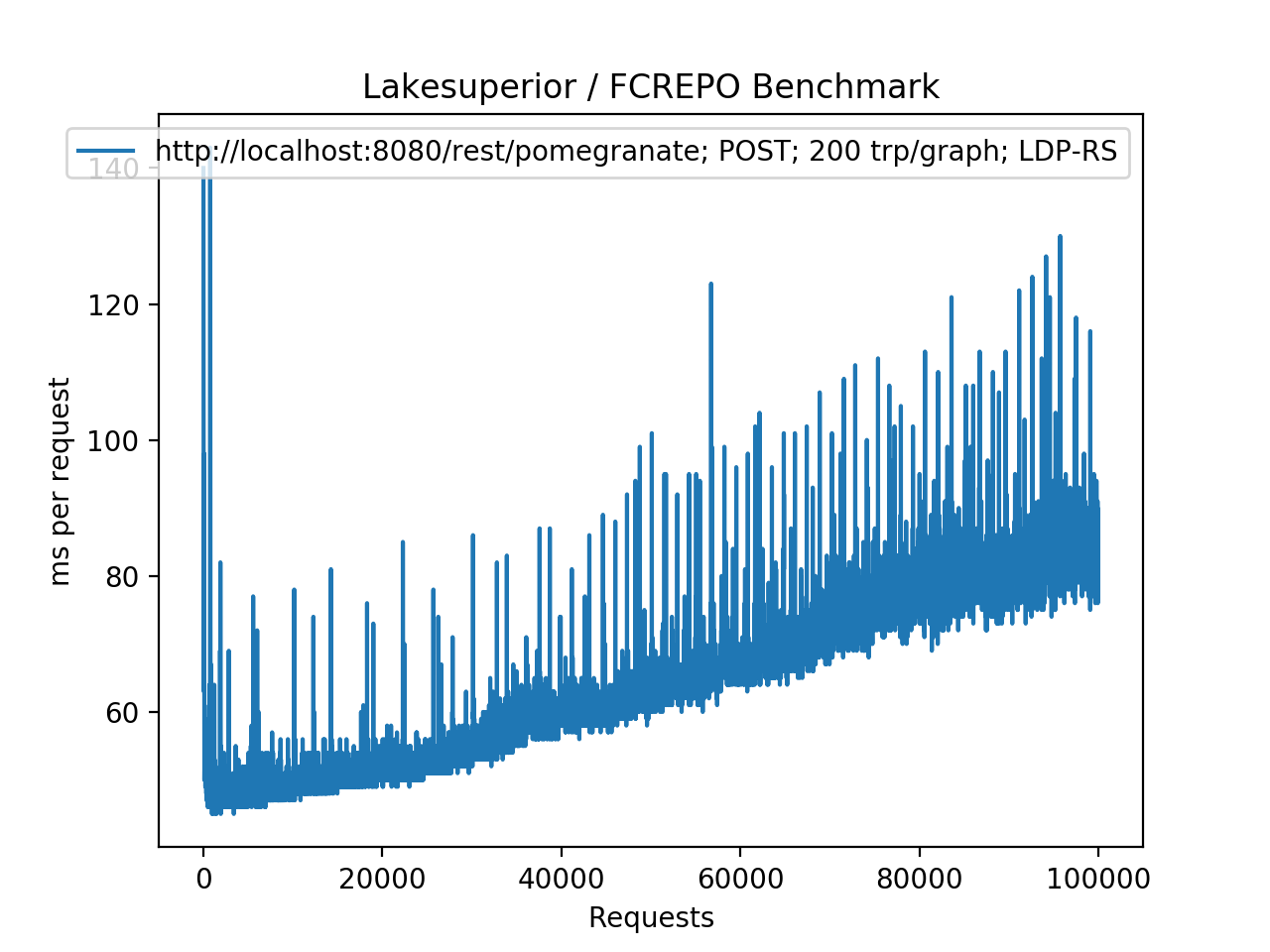
{kind=link}
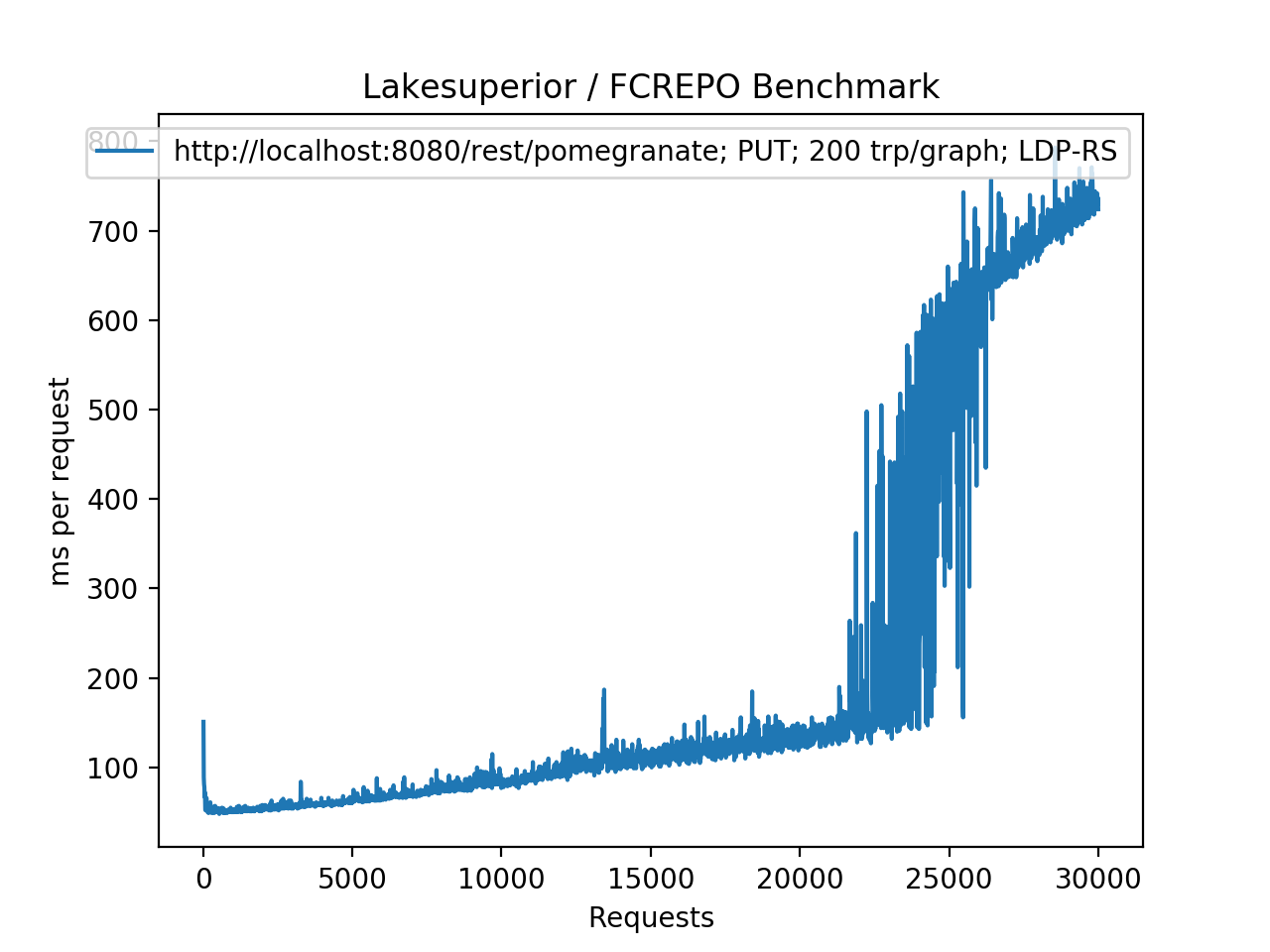
{kind=link}
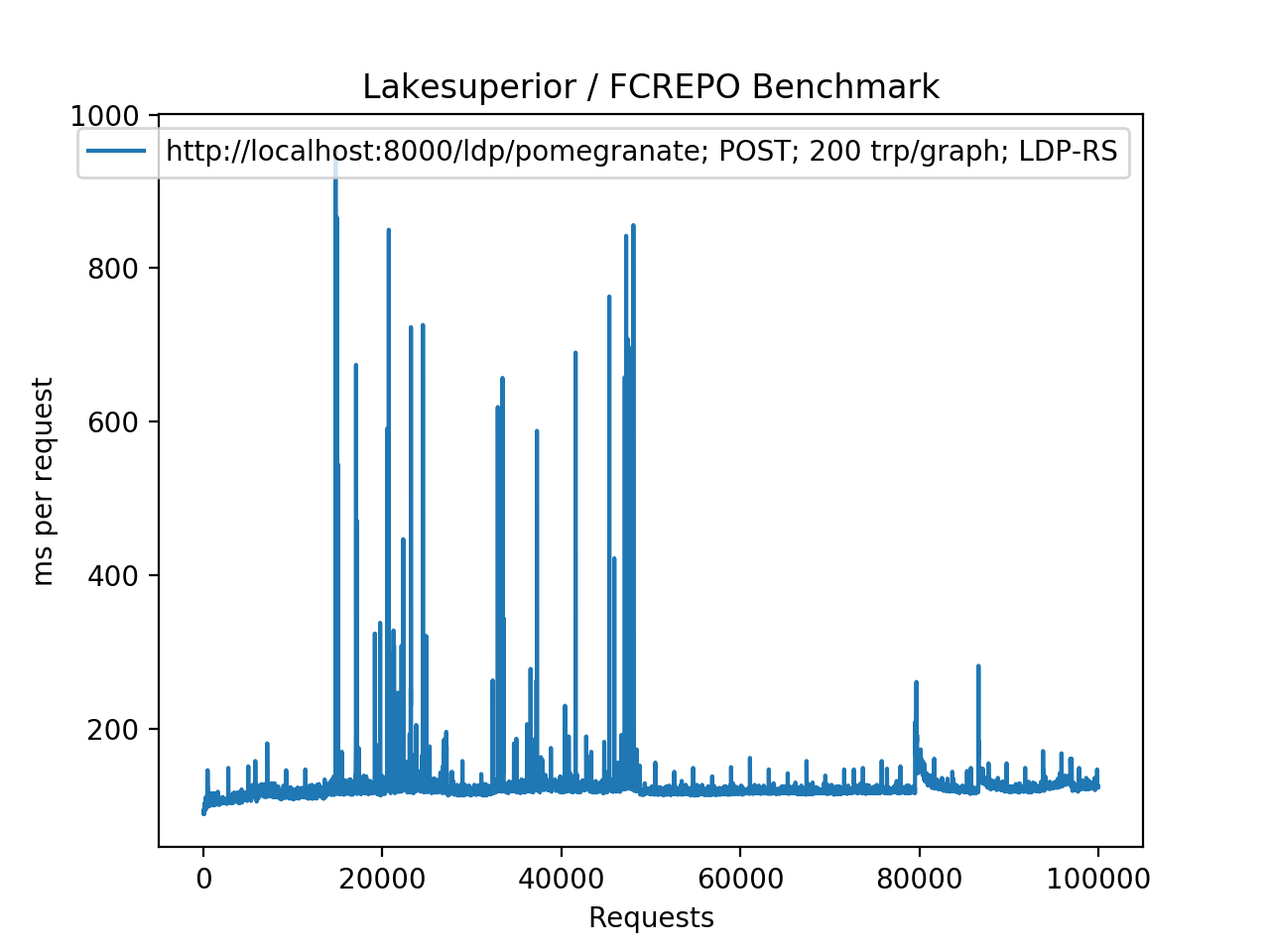
{kind=link}