
 Stefano Cossu
Stefano Cossu
+ 2
- 3
.travis.yml
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 1
- 1
Dockerfile
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 3
- 0
MANIFEST.in
|
|||
|
|
||
|
|
||
|
|
||
+ 0
- 177
README.md
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 69
- 0
README.rst
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 3
- 1
conftest.py
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 0
- 43
doc/notes/architecture.md
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 0
- 33
doc/notes/cli.md
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 0
- 213
doc/notes/fcrepo4_deltas.md
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 0
- 260
doc/notes/indexing_strategy.md
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 0
- 27
doc/notes/messaging.md
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 0
- 57
doc/notes/migration.md
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 0
- 63
doc/notes/model.md
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 0
- 112
doc/notes/performance.md
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 0
- 82
doc/notes/storage.md
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 3
- 2
docker/docker_entrypoint
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 0
- 31
docker/etc/gunicorn.py
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 24
- 0
docker/etc/gunicorn.yml
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 23
- 0
docs/Makefile
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 86
- 0
docs/about.rst
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 25
- 0
docs/api.rst
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 38
- 0
docs/apidoc/lakesuperior.api.rst
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 46
- 0
docs/apidoc/lakesuperior.endpoints.rst
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 38
- 0
docs/apidoc/lakesuperior.messaging.rst
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 46
- 0
docs/apidoc/lakesuperior.model.rst
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 89
- 0
docs/apidoc/lakesuperior.rst
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 30
- 0
docs/apidoc/lakesuperior.store.ldp_nr.rst
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 30
- 0
docs/apidoc/lakesuperior.store.ldp_rs.rst
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 18
- 0
docs/apidoc/lakesuperior.store.rst
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 7
- 0
docs/apidoc/modules.rst
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 48
- 0
docs/architecture.rst
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 0
- 0
doc/assets/lakesuperior_arch.png → docs/assets/lakesuperior_arch.png
{kind=link}
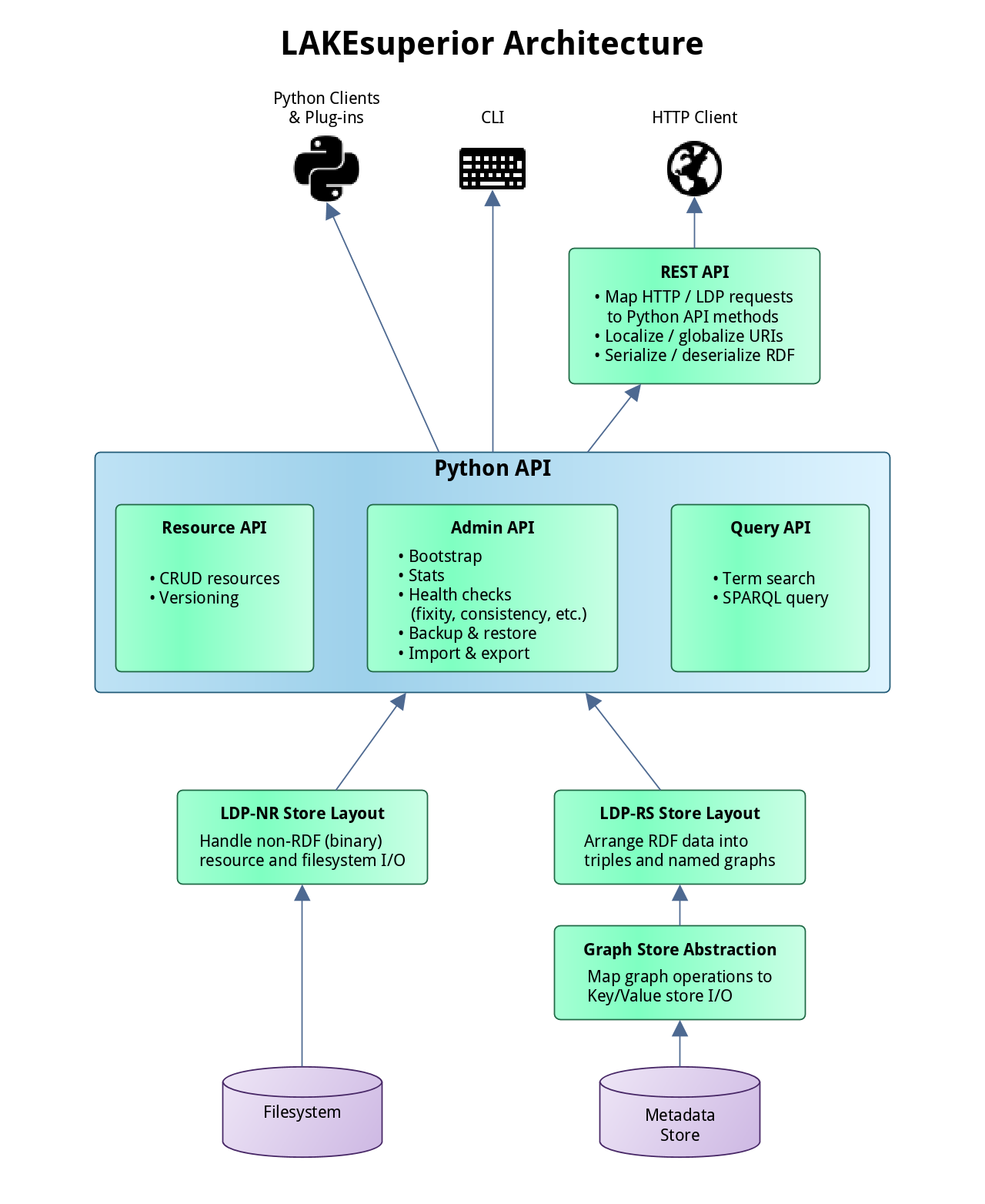
+ 0
- 0
doc/assets/lakesuperior_recommendations.pdf → docs/assets/lakesuperior_recommendations.pdf
二进制
docs/assets/profile_1K_children_get.pdf
+ 33
- 0
docs/cli.rst
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 191
- 0
docs/conf.py
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 40
- 0
docs/contributing.rst
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 0
- 0
doc/examples/store_layouts/graph_per_aspect.trig → docs/examples/store_layouts/graph_per_aspect.trig
+ 0
- 0
doc/examples/store_layouts/graph_per_resource+.trig → docs/examples/store_layouts/graph_per_resource+.trig
+ 0
- 0
doc/examples/store_layouts/graph_per_resource.trig → docs/examples/store_layouts/graph_per_resource.trig
+ 244
- 0
docs/fcrepo4_deltas.rst
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 9
- 0
docs/help.rst
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 52
- 0
docs/index.rst
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 311
- 0
docs/indexing_strategy.rst
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 30
- 0
docs/messaging.rst
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 65
- 0
docs/migration.rst
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 65
- 0
docs/model.rst
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 0
- 0
doc/notes/TODO → docs/notes/TODO.historic
+ 133
- 0
docs/performance.rst
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 101
- 0
docs/setup.rst
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 0
- 0
doc/src/lakesuperior_arch.graphml → docs/src/lakesuperior_arch.graphml
+ 0
- 0
doc/src/lakesuperior_content_model.graphml → docs/src/lakesuperior_content_model.graphml
+ 0
- 0
doc/src/lakesuperior_recommendations.md → docs/src/lakesuperior_recommendations.md
+ 0
- 0
doc/src/template.latex → docs/src/template.latex
+ 0
- 0
doc/src/use_cases_transactions.md → docs/src/use_cases_transactions.md
+ 94
- 0
docs/storage.rst
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 117
- 0
docs/usage.rst
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 0
- 32
etc.defaults/gunicorn.py
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 24
- 0
etc.defaults/gunicorn.yml
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 0
- 5
fcrepo
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 0
- 0
lakesuperior/api/__init__.py
+ 9
- 8
lakesuperior/api/query.py
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 65
- 62
lakesuperior/api/resource.py
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 2
- 2
lakesuperior/config_parser.py
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 0
- 0
lakesuperior/dictionaries/__init__.py
+ 0
- 0
lakesuperior/endpoints/__init__.py
+ 8
- 8
lakesuperior/endpoints/admin.py
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 50
- 47
lakesuperior/endpoints/ldp.py
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 3
- 7
lakesuperior/endpoints/main.py
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 5
- 5
lakesuperior/endpoints/query.py
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 0
- 0
static/assets/css/bootstrap-theme.css → lakesuperior/endpoints/templates/static/assets/css/bootstrap-theme.css
+ 0
- 0
static/assets/css/bootstrap-theme.css.map → lakesuperior/endpoints/templates/static/assets/css/bootstrap-theme.css.map
+ 0
- 0
static/assets/css/bootstrap-theme.min.css → lakesuperior/endpoints/templates/static/assets/css/bootstrap-theme.min.css
+ 0
- 0
static/assets/css/bootstrap-theme.min.css.map → lakesuperior/endpoints/templates/static/assets/css/bootstrap-theme.min.css.map
+ 0
- 0
static/assets/css/bootstrap.css → lakesuperior/endpoints/templates/static/assets/css/bootstrap.css
+ 0
- 0
static/assets/css/bootstrap.css.map → lakesuperior/endpoints/templates/static/assets/css/bootstrap.css.map
+ 0
- 0
static/assets/css/bootstrap.min.css → lakesuperior/endpoints/templates/static/assets/css/bootstrap.min.css
+ 0
- 0
static/assets/css/bootstrap.min.css.map → lakesuperior/endpoints/templates/static/assets/css/bootstrap.min.css.map
+ 0
- 0
static/assets/css/yasgui.min.css → lakesuperior/endpoints/templates/static/assets/css/yasgui.min.css
+ 0
- 0
static/assets/fonts/glyphicons-halflings-regular.eot → lakesuperior/endpoints/templates/static/assets/fonts/glyphicons-halflings-regular.eot
+ 0
- 0
static/assets/fonts/glyphicons-halflings-regular.svg → lakesuperior/endpoints/templates/static/assets/fonts/glyphicons-halflings-regular.svg
{kind=link}
+ 0
- 0
static/assets/fonts/glyphicons-halflings-regular.ttf → lakesuperior/endpoints/templates/static/assets/fonts/glyphicons-halflings-regular.ttf
+ 0
- 0
static/assets/fonts/glyphicons-halflings-regular.woff → lakesuperior/endpoints/templates/static/assets/fonts/glyphicons-halflings-regular.woff
+ 0
- 0
static/assets/fonts/glyphicons-halflings-regular.woff2 → lakesuperior/endpoints/templates/static/assets/fonts/glyphicons-halflings-regular.woff2
+ 0
- 0
static/assets/js/bootstrap.js → lakesuperior/endpoints/templates/static/assets/js/bootstrap.js
+ 0
- 0
static/assets/js/bootstrap.min.js → lakesuperior/endpoints/templates/static/assets/js/bootstrap.min.js
+ 0
- 0
static/assets/js/jquery-3.2.1.min.js → lakesuperior/endpoints/templates/static/assets/js/jquery-3.2.1.min.js
+ 0
- 0
static/assets/js/npm.js → lakesuperior/endpoints/templates/static/assets/js/npm.js
+ 0
- 0
static/assets/js/yasgui.min.js → lakesuperior/endpoints/templates/static/assets/js/yasgui.min.js
+ 10
- 3
lakesuperior/env_setup.py
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 59
- 9
lakesuperior/globals.py
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 0
- 1
lsup-admin → lakesuperior/lsup_admin.py
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
+ 0
- 0
lakesuperior/messaging/__init__.py
+ 14
- 18
lakesuperior/messaging/formatters.py
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 24
- 16
lakesuperior/messaging/handlers.py
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 6
- 8
lakesuperior/messaging/messenger.py
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 27
- 25
lakesuperior/migrator.py
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 28
- 26
lakesuperior/model/ldp_factory.py
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 14
- 13
lakesuperior/model/ldp_nr.py
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
+ 15
- 17
lakesuperior/model/ldp_rs.py
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||
|
|
||